TL;DR:
- It’s be crazy to assume in advance that the same solution to a different scenario is correct
- A system should retain Agility, not Agile, and to keep it simple
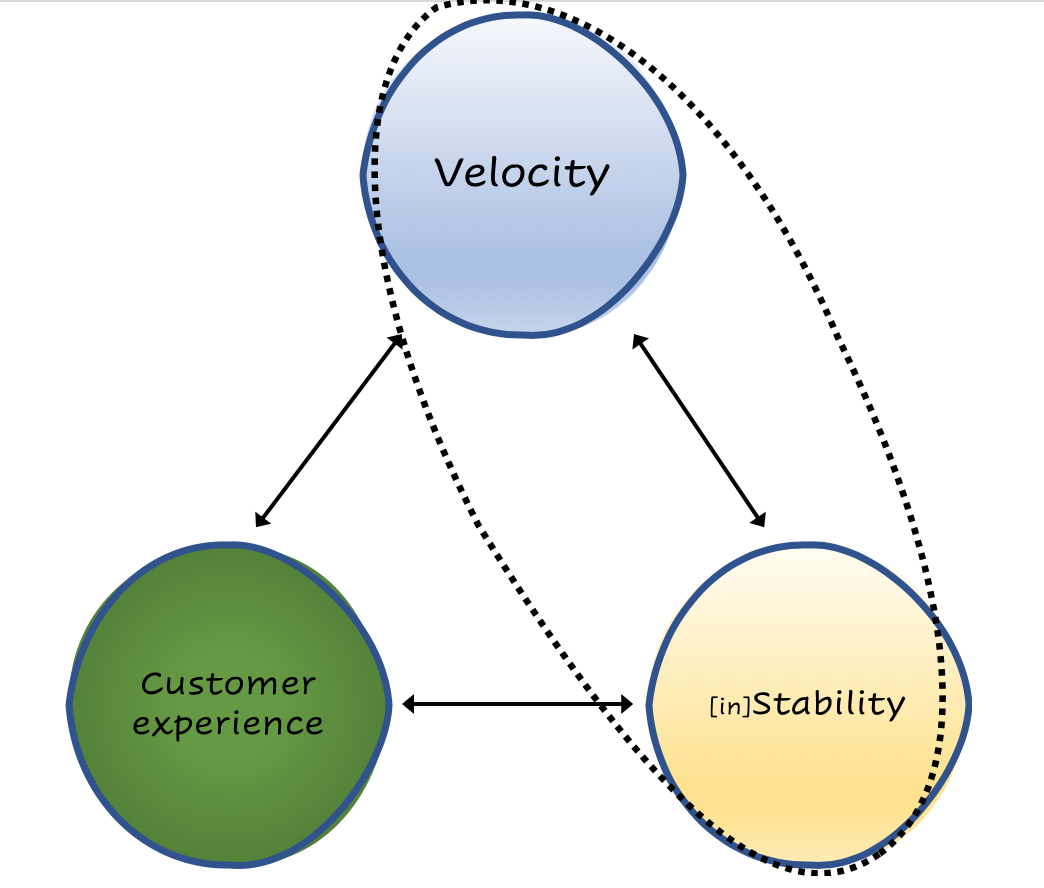
- Velocity is the need and wish to run forward with business and development alike
- Developers love to come to work.. to work.. not to do maintenance
- There is a tradeoff: high Velocity entails more changes and more frequently which entails higher Instability. A system should overcome that
- There are two kinds of instabilities to prevent. One caused by Velocity, the other caused by the system itself.
- Agile is not a free ticket to do your job with disregard to consequences
- The second year syndrome is when you focus effort on all the prevented instabilities you’ve caused in year one, instead of on the money makers. Instability is a time that could have been invested in Velocity, or to better prevent instability
- 80% of instabilities could be prevented by CI/CD, TDD/BDD and design for high availability. For the 20% who are unpreventable, reduce duration and impact via isolation and tracing.
- Chasing incorrect goals is also a loss of Velocity
As I expected an endless stream of tasks, one of the first things I needed as an engineering manager was to manage them. I needed to manage tasks and my team. As I was sprinting (pun intended) towards signing up to Jira, I halted my horses thinking to myself “you know how to use Jira, do you know why you use Jira?”. Historically speaking the answer is because until now I’ve always joined a company that already used Jira, so naturally I wanted to go with what I know.
But this is now, a new company and new people. Today I’m founding a new software company/division. I’d be crazy to assume in advance that the same solution to a different scenario is correct. You’d now expect that the answer to “Why Jira?” would be because we’re Agile, which is exactly what I told myself. That was just me moving the “why” question from label/domain to another. Now I had to question and answer what Agile is. “Why Agile?”. “Should Agile?”.
I’ve spent a lot of time contemplating and reading about Agile. There is a lot to it, but what Uncle Bob said in one of his famous lectures “Agile is Dead” is what best defines it for me and which I try to practice:
Agility – what to do:
- Find out where you are
- Take a small step towards your goal
- Adjust your understanding based on what you learned
- Repeat
Agility – how to do it:
- When faced with two or more alternatives that deliver roughly the same value, take the path that make future change easier
I think it captures the essence of Agile/Agility at its best, or the very least something you should always keep in mind (another mantra!) and to not deviate from. Silo would require a system and a culture that would retain Agility and to keep it simple (stupid). The rest of it (user stories and epics, Scrum and Kanban, story points, retrospective and the entire glossary) are optional management tools that some may help you do that and some may further you away from Agility [see later in this series, on The Self Inspector: Culture Drop]. But while reading the Agile manifesto, I did take one single term with me down the road.
Velocity, just like any other term in Agile glossary, is obviously ambiguous. Velocity mostly refers to the amount of units of work done in the previous Sprint. Velocity in physics is how fast you are going. I do not wish for us to drop Velocity, to be slower. From the business perspective, it is a race. If you drop your Velocity, the competitors will make you eat their dust. You’d lose your business edge, you’d be trailing behind others instead of leading the domain and you’ll eventually go bankrupt.
From the technological perspective, adaptation of new technologies helps you retain and increase Velocity while legacy ones drop your Velocity. Myself, both as a software developer and an engineering manager, I know what developers want. Developers want to run and run fast. They want to work, they want to create. This is why they love to come to work.
Unfortunately, high Velocity entails more changes and more frequently which entails higher Instability. That’s the tradeoff. As an architect, I would need to provide them with the necessary system and tools for my developers. They should continue to run fast as they can and to not look behind. A system that is not sensitive to change frequency, and one that should not be halted by Velocity. This is not easy.
I love downtime! (said no one never)
Velocity is the need and wish to run forward with business and development. Instability interferes with that. If your Jenkins goes down because it’s out of memory all of sudden, that would be an engineer’s time and effort spent on maintenance and downtime, on fixing the old and not on progressing the new. Instability causes a Velocity drop. That’s not why the developer came to work that day.
In the previous article I’ve talked about preventing instabilities, time to elaborate on what causes it. There are mainly two kinds of instabilities to prevent, each one dealt differently. Instability caused by Velocity happens when an update for a bug fix or a new feature has been pushed. Preventing it is one thing [will be covered in a future article about tests]. To prevent Instability caused by the system itself, by its underlying servers/applicative infrastructure, is a whole other thing [majorly covered in Part II: Feet in the Cloud].
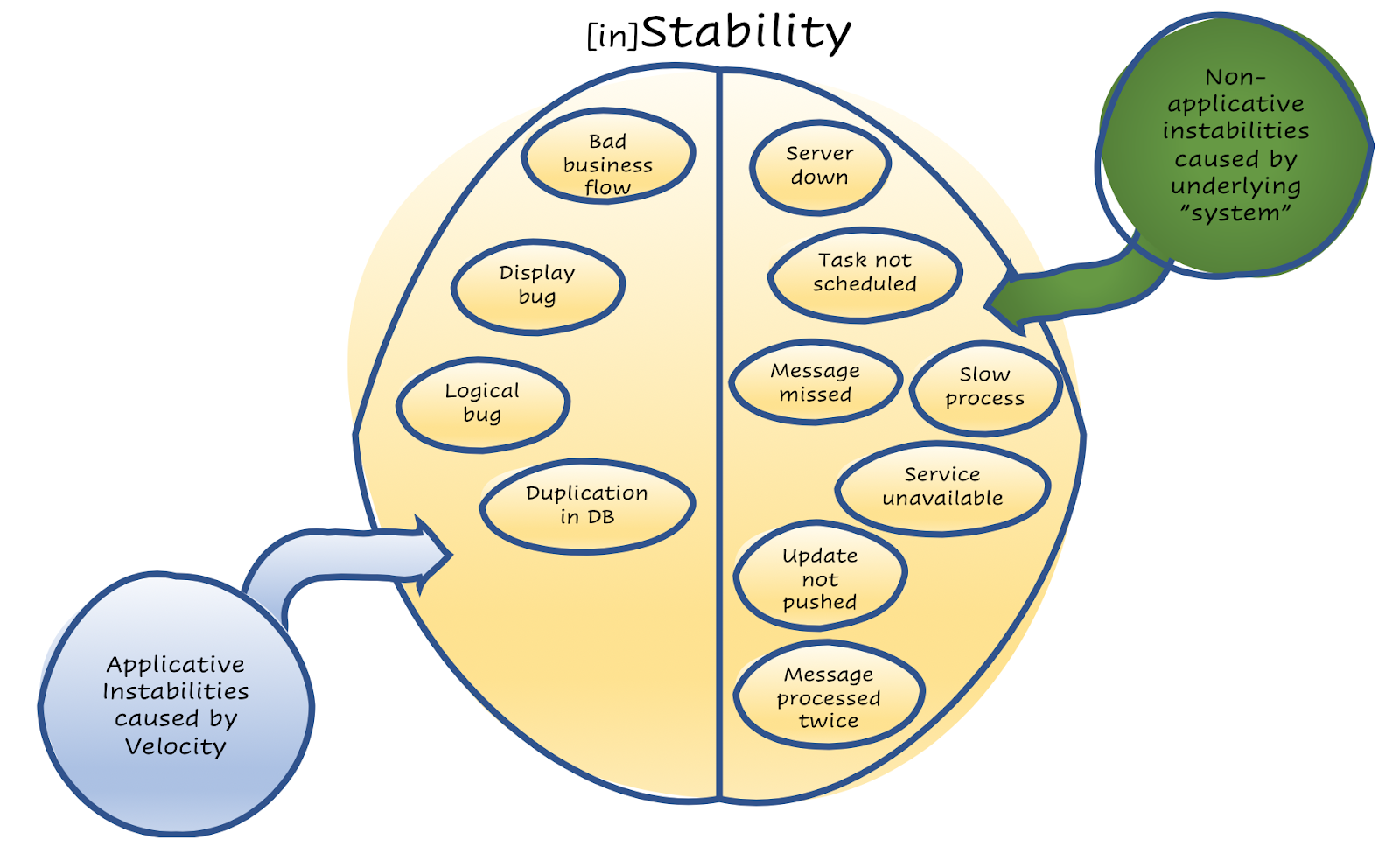
To better explain the difference, let’s review two bugs we discovered at Silo during development, both of which could have led to some very angry customers in production.
One bug caused the Food Management Service to reply 243 weeks instead of 10 days. It happened due to an incorrect coding, a human error by one of our developers. It happens and that’s okay. We are human after all. You should not be afraid to make a mistake (If that mantra sounds familiar, it’s because it was mentioned in part I about company values) ! This one did not reach production. It was caught by our CI/CD pipeline, by the unit and integration tests it is running before deployment. An unnecessary/uncalled for instability has been prevented. Velocity was not dropped.
The second bug caused the same service not to reply to the client at all. This was caused because one of the underlying infrastructure applications of the messaging system has crashed for an unknown underlying OS issue. This issue itself could have happened in production, as underlying OS issues do occur, but would not have an effect on the customers at all as the underlying infrastructure was designed in advance for high availability, so there would always be a separate independent backup ready. That is another unnecessary/uncalled for instability that has been prevented. Velocity was not dropped yet again.
An external spectator, a customer or the CEO/COO, could not tell the difference between these two bugs / causes for instability. Try to explain management, marketing and customers the difference between the two. Although they might understand the difference in severity, they would not care. Customers expect things to work no matter the cause. That’s details to them.
At Deaply (2014), we worked at a really high Velocity. The seven of us coded 20-30 tickets a day. As there were no safeguards whatsoever, almost 75% of the deployments were reverted due to unknown bugs. It was so bad that one time there was a deployment freeze for three weeks straight. That is a Velocity of zero caused by tons of preventable instabilities.
I remember a specific push I made that contained a bug, one that caused bad pricing format to be shown to the end users. It led to less clicks on the widget/ad, what the company was making actual money of. The damages were about $10,000 dollars an hour. The issue lasted for 4 hours. I’ve done the math, it summed up to about 4 months of my salary back then. It was a totally preventable bug that a simple unit test would have caught. Alas, TDD/BDD was not a part of the development culture at Dealply. To our defence, back in 2014 barely anyone in Israel practiced it. Today in 2020 if you’re not doing it, you better have a good reason not to. In Silo, we actually did have one, but more on that in a future article about TDD/BDD.
The Second Year Syndrome
You must wonder how Dealply ended with weeks of deployment freezes. It did not come out of nowhere. The same happened at Wiser. When I joined these companies they both were at the stage of scaling up, business wise and technically wise. Problem is the latter blocked the first from happening.
Agile is not a free ticket to do your job with disregard to consequences. I’ve heard enough of the phrases “we don’t need to plan in advance we are Agile!” or “don’t worry about scaling” or “it’s a startup you’re supposed to work 12 hours a day”. That is just signs of lack of design considerations that will ultimately lead to failing to scale the technology, the business or both. There will come a day that someone has to pay for it and it is always when the company needs to prove its worth. That is a known tradeoff between speed and quality, but it is nothing but a misconception.
The first year of a startup is naturally emphasizing on proof of concept, to validate your product and the need for your product, which is indeed important. If you do it really poorly, you would find yourself waking up in the middle of the night after a 12 hours workday (!) to the wonderful phone rings of PagerDuty because your latest push crashed down all the servers. You would then have a very bad night sleep, only to go the next day to work, for another 12 hours. Half of your workday you’d spend on putting out last night’s fires. “It’s okay, I’m working for a startup and I’ll be rich one day because I work hard” you’d tell yourself. A year passes and your company has proved it has a promising future value and you’ve been funded. Congrats, now what?
Instead of pouring money into fulfilling that promise, the money makers, you’d hire more engineers who would spend the upcoming year either rewriting the entire system from scratch or putting fires with you. They too would be working 12 hours a day and waking up at night because of what you’ve done wrong in your first year. It would be harder for you to invest the right effort towards raising the company’s value. The company’s Velocity would be small due to its Instability. Instability is a time that could have been invested in Velocity, or to better prevent instability. This is the second year syndrome.
“This would not happen on our watch” is what I promised both Silo’s management, its investors and my team. From day one we have automated almost everything, to make sure that every flow/process that involves the production environment will be free of human made errors. As Agent Smith from the Matrix says, never send a human to do a machine’s job. There was no such thing as compiling/deploying from your workstation. Everything was to be done through our CI/CD system. No exceptions whatsoever.
We’ve embedded a test/behavior driven development (TDD/BDD) inherently in our culture. Our servers and databases were either Serverless or fully manageable to minimize maintenance and down town. We were scale ready and highly available from day one. Everything to prevent instability in advance, everything to prevent bad updates from reaching production. To catch errors and issues before they happen. In so, we clearly defined our QA’s job definition – to be our last line of defence.
We had all these safeguards in place so we can maintain our Velocity, so we can go on coding without almost any worry as 80% of the issues (Pareto Law) are being actively and continuously prevented.
Alert, trace, recreate, deploy, repeat
It was decided that chasing our tails to gain an unachievable 100% stable system was not worth the effort. Chasing incorrect goals is also a loss of Velocity. Instead, for the rest of the 20% that can not be caught in advance, we invested a lot of time into a tracing system called Event Analysis that would collect and analyze everything that happened within the system [more on it in a future article].
Even if something would go wary, we’d have an alerting system in place to catch it as quickly as possible. When an error surfaced, all a developer had to do is copy-paste the trace/Event log into a new unit test (TDD/BDD to the rescue again!) which recreated the issue in almost an instant. That allowed us to minimize instability time. Another effort saved and reinvested into Velocity. The new unit test would validate that the issue would not resurface again.
An alert, a trace, a fast re-creation, a safe deploy. That would be an effective workflow. My vision was for this to be so efficient so we’d need only a 4 days work week and with less employees. I wished to be the only employer that would be able to offer an engineer a 4 days job and get 5 days worth of work out of him. That would be another way to make sure I’ll be able to recruit the best engineers. Architecture has also much to do with HR.
This workflow proved itself perfectly during our PoC. We sent 20 devices to customers “in the field”. All the devices connected and updated successfully as we had time to thoroughly test it. Within a week and a half the devices were fully stable and have met customer satisfaction. Within a total of three weeks 60 issues were recreated and resolved by a single engineer and a single QA. The PoC ran for two months with zero downtime and zero sleepless nights.
To be honest, one must remember that Silo was a physical product and we had a lot of past relevant experience. Software was always ahead in time and there were always design and manufacturing delays with the device. Even though we had all the time in the world to set up everything, it is still much of a big deal, as we lacked resources. We managed to do all that and develop an entire device with a very small team (3 in PoC stage, 5-8 in production stage). In a different scenario, doing the same in half the time would have required double the personnel, that’s for sure.
We kept that workflow during the production stage of the development and the production environment was live, ready and steady. Unfortunately, the physical device was never released, at least at the time of writing this. We were only mere 6 weeks away from the first batch sent.