
We’ve seen three evolutionary processes so far (there might be more). Each and every application has the potential of entering a state of a Monolith, a Bundle or a Legacy. Eventually our application would end up at one of these states, maybe even a combination of them. Afterwards, eventually a Cause (event) would surface that would make you consider a refactor. It could be a technological shift, hiring of new developers or we simply grew tired of it. Once decided on a refactor, it would be a question of when. Between the decision and the execution, the application has entered a state of refactor needed. In the following chapters, we’d be exploring these new states.
Now, Later, Never
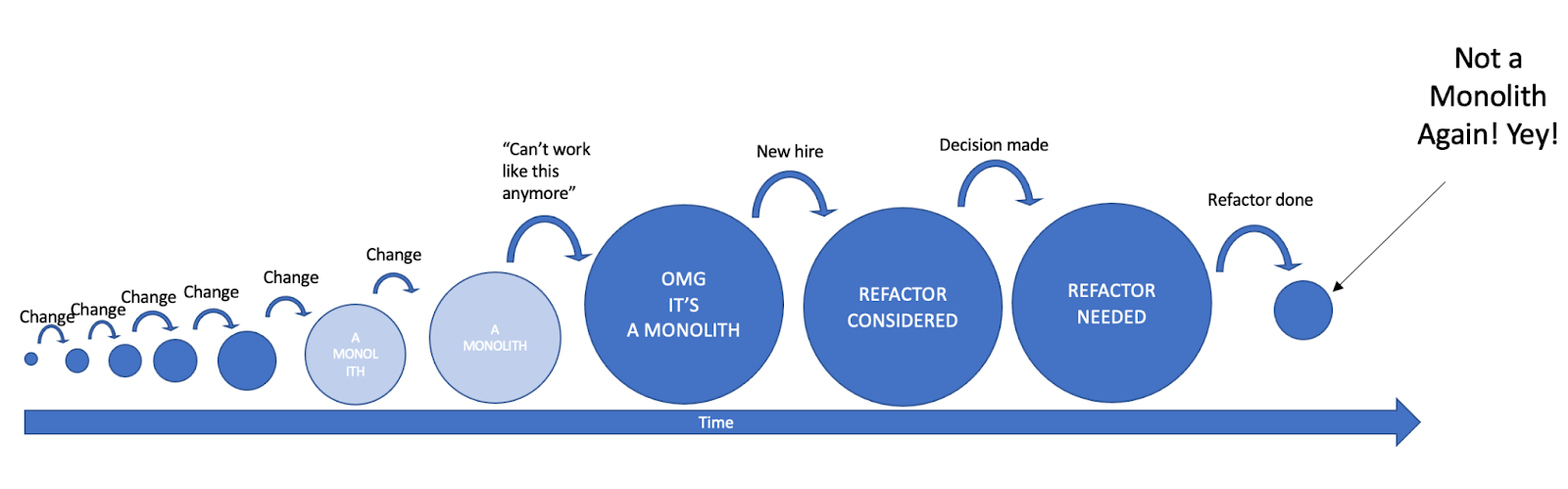
If we’d take our application’s state machine we modeled before a little bit forward in time, we’d see the new states of the refactor. The last state is an expected one after a refactor is done. We wish for the application to go back into not being a Monolith again. (In this chapter we’ll be continuing with the Monolith evolution as an example. Any other evolutionary process is valid as well).
The refactor needed is a funny and fuzzy state which is mostly a state of mind. Once entered we would start thinking on every Change “should we do this now or after the refactor?”. That is even before we know what a refactor would mean or when it would be! Because in our mind everything takes at least half the time after the refactor and the refactor would happen soon enough. Is it true though, or is it only in your mind?
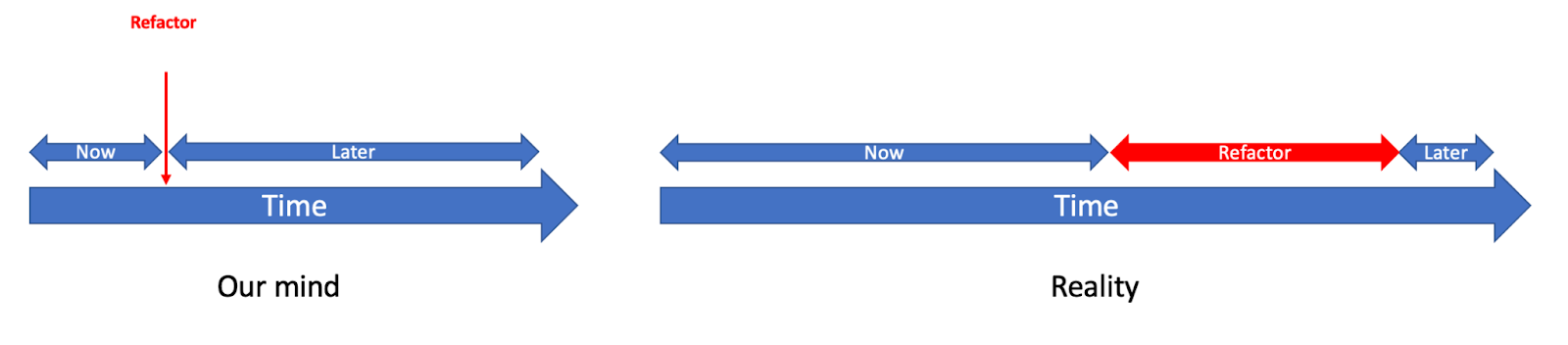
A refactor is not a point in time. A refactor is a time consuming effort. It is an effort being diverted from slowly moving the business forward, on the promise that you’d be moving your business faster afterwards. That is supposedly a temporary drop in Velocity in order to increase it.
Unfortunately, whatever the answer to “should we do this Change now or after the refactor?” is completely biased by our expectations. If we decide to do the Change now, it is a waste because our application is in an inefficient state that produces waste. If we were to postpone it, we’d be making a conscious decision not to move the business forward. That is money not earned.
We’ve set ourselves a trap. Once we tell our colleagues we’ve decided to postpone it, they would have a solid expectation, a date set on when it will happen – after the refactor which in their minds is a point in time, not a time consuming effort. We won’t meet that unrealistic expectation thus the feature would be released far into the future than thought. That would be a failure set to happen. We would also have a solid expectation on the effort required for this new feature – if after the refactor it won’t take half the time it would be a failure in everyone’s eyes.
Our expectations need to be better managed and resolved.
A Continuous Refactor
A refactor is also a Change. We’ve already reviewed more than once what Change entails. Instabilities, and instabilities have the potential to cause a Velocity drop. So in fact, we’d be dropping our Velocity and the result would be – dropping our Velocity even more!
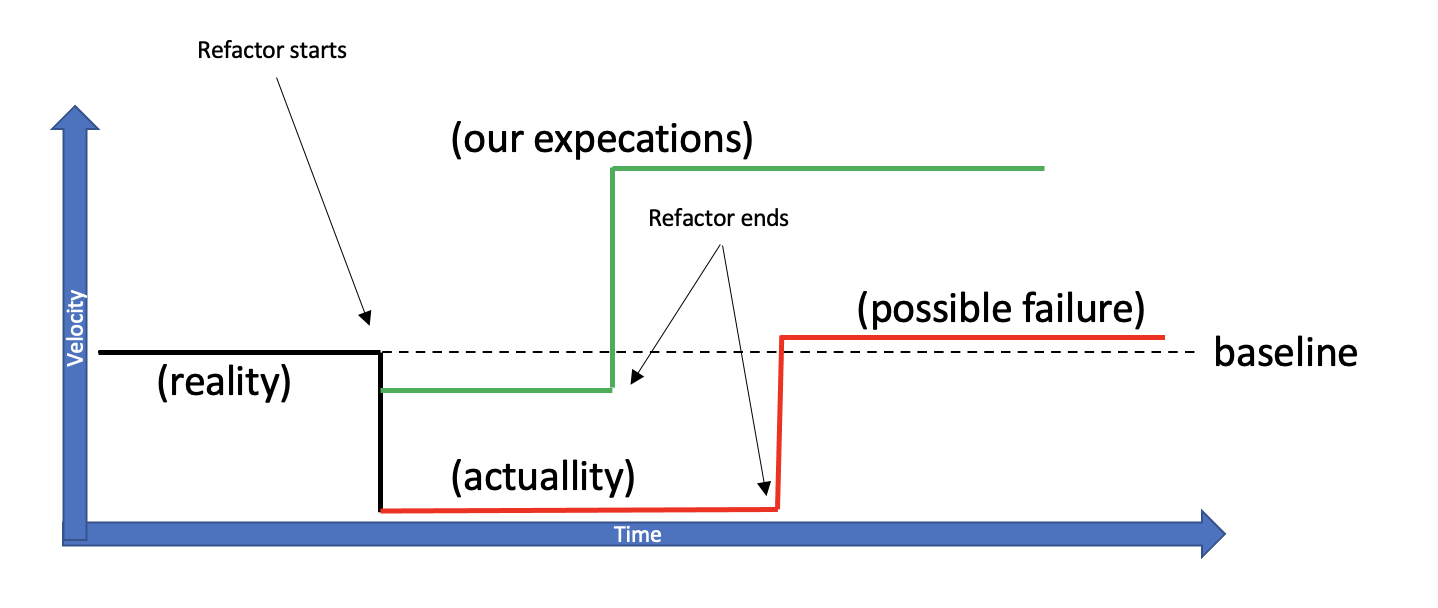
A refactor is not just a Change. A refactor once done and deployed is a big Change, an accumulation of small changes. In the chapter about a Bundle’s waste we’ve reviewed that big deployments are a source of inefficiency as they would send us on long Hunts, to find out what went wrong. In the following chapter on how to remove and avoid these inefficiency, we’ve seen that continuously deploying small changes is a superior strategy. A refactor can be similar. Instead of one big refactor, lots of small ones. One after the other. How treating a refactor as a process would affect our efforts to increase our Velocity?
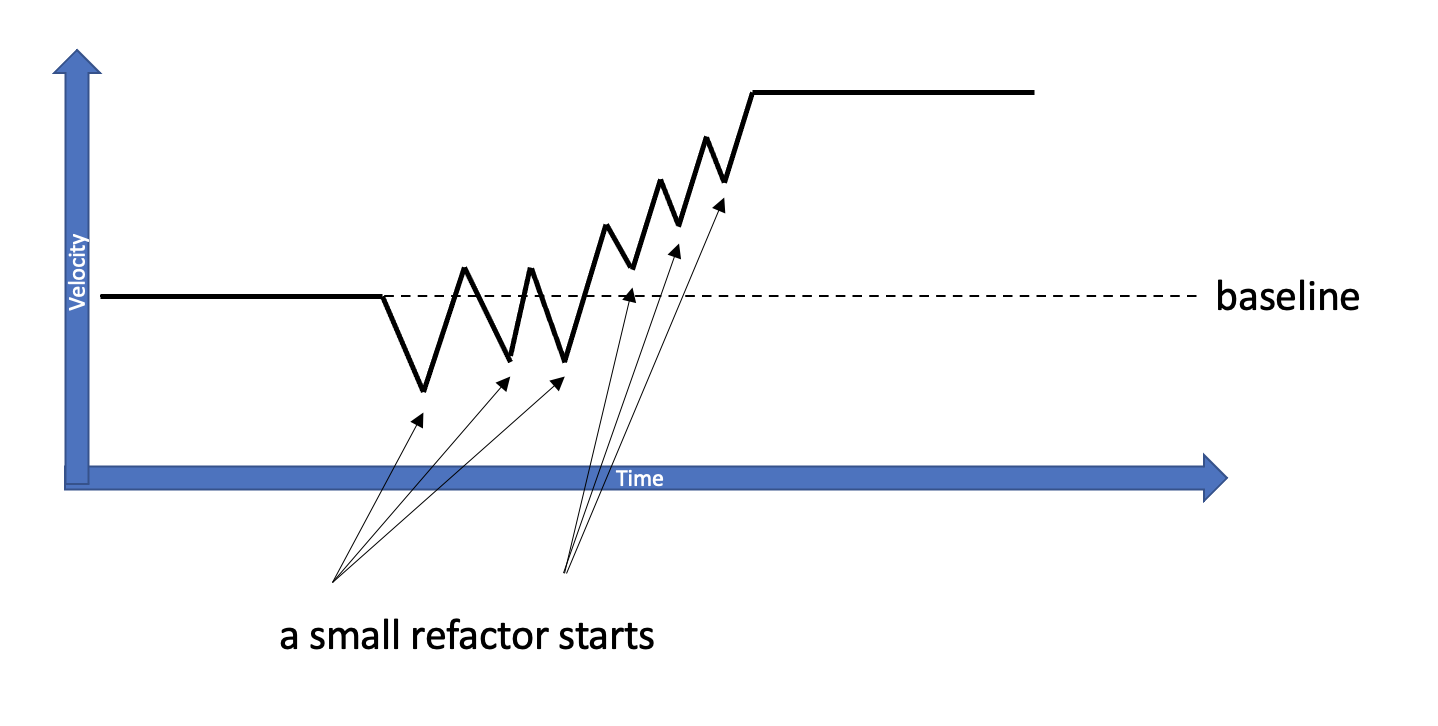
The initial Velocity drop will not be to a complete zero. Our effort can be divided between the refactor and moving our business forward. There won’t be a version freeze so there might be some code conflict so resolve.
After a few beneficial small refactors, within days we would gain a Velocity increase and not keep our fingers crossed for a theoretical one after months. On the contrary, if we see that the planned refactor leads us nowhere we can just stop whenever we like. Replan or drop it. If the process goes well enough, our Velocity would sooner go above the baseline, sooner than months. We can always stop once we’ve gained enough Velocity. As the refactor is done in parallel to our day-to-day work, we’ll know better when to stop. We’d be avoiding unnecessary refactoring effort, and preventing valueless executions is a must.
Once a beneficial refactor is celebrated, what will happen next?
Forward to the Past
After a few weeks of beneficial effort we’ve decided to halt the refactor because the Velocity has gone high enough. It could be twice or thrice then before, or even a Velocity higher than ever. We might be satisfied by the results, but have we really met our expectations?
One of our wishes was “for the application to go back into not being a Monolith again”. While discussing the evolution process of a Legacy, we’ve also seen the dangers of time traveling and our misconception of it. We can not go back to a previous state, there is no going back to not a Monolith. An application after a refactor, just like after any Change is not the same as it was before it. The code would be entirely different. What we did was to move it forward to not being a Monolith (no again here). And once there, continue to do Changes, and Change is the catalyst of all evolution processes. The clock has started ticking again.
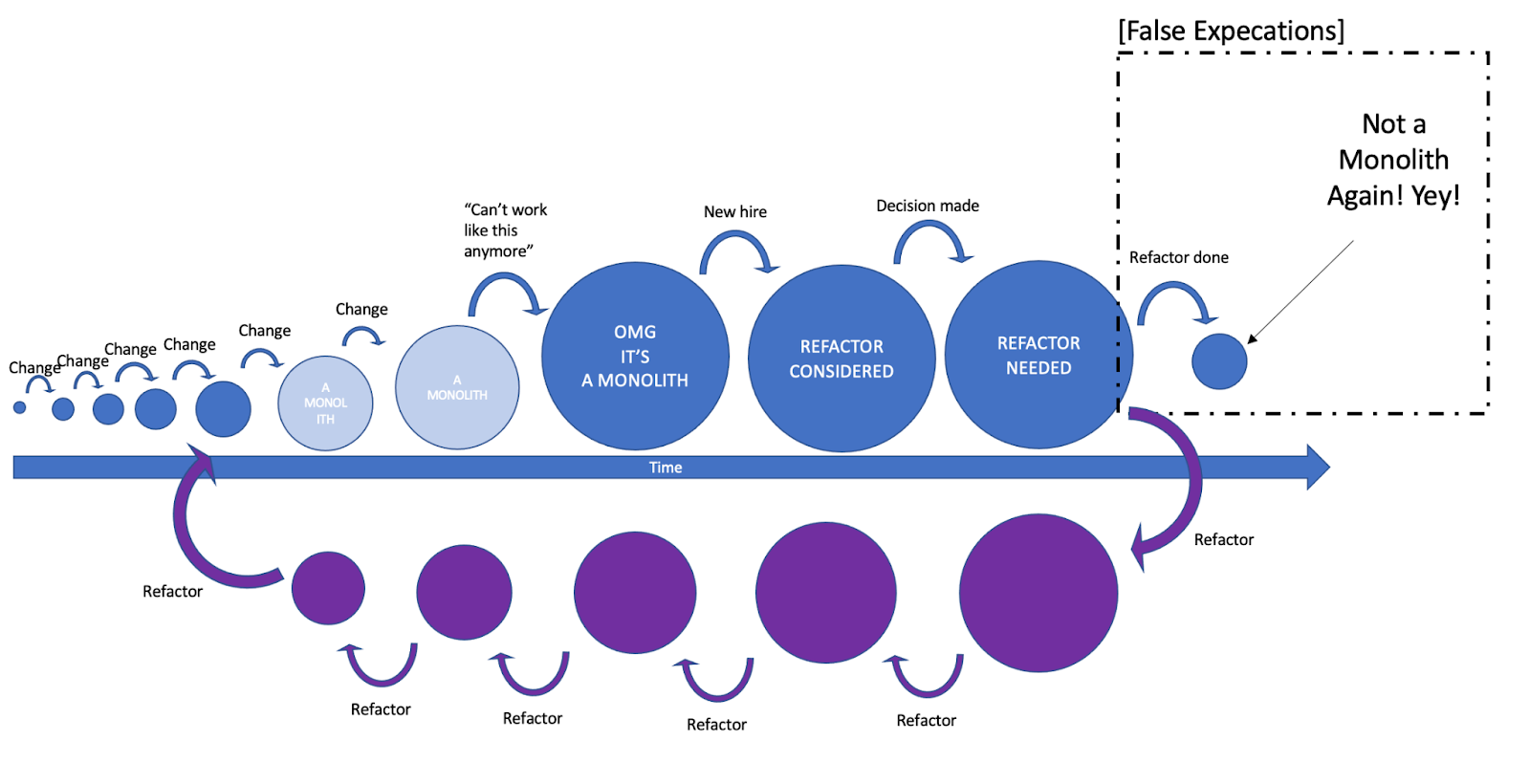
If the evolution process continues but only from a different spot, it is not only a question of how high our Velocity is now. It’s also a question for how long it would remain high enough. How long will it be until another refactor is needed? A beneficial refactor is one where a sufficient amount of effort buys us enough time, postpones what eventually would happen as further into the future as possible. Mathematically speaking, the lower the decay rate is, the slower the evolution process is. How have we impacted our Velocity’s decay rate?
To grasp it, let’s have a look at two possible outcomes. Let’s presume we’ve put in a month of effort and the refactor process took us two months. One outcome would be that after just three months our engineers would once again say “I can’t work like this any more”. That would be a failure. A second outcome would be that the same would happen, only after three years. That is indeed a more beneficial outcome. So, how long is good enough? We would see an answer to this in the next series (“The Inevitable”) where we would be discussing the Beneficial and Eventualism frameworks.
Problem is, there are two opposing forces / factors in effect here.
Some beneficial refactors eases up our coding. For example, a refactor that would correctly arrange the code between files, classes, components, features, tests, etc. It takes us less effort to code and in a shorter time period. These are the kinds of refactors we have in mind when we expect the development to take half the time. These increase our Velocity.
Some beneficial refactors make it easier to extend our application. It is a probable outcome because we do know better what our application is intended to do, better than yesterday. Let’s think of an ETL-like product as an example. At its first iteration, it was coded to be extended by adding more flows. A year later, we’ve learned that engineers are not only extending the product by coding flows but also extending by coding components. After the refactor it’s now easier to do so! These not only increase our Velocity but have the potential to increase it to an all time high.
The opposing force to increasing our Velocity is the rate of Changes. As we’ve eased up development (coding and extending) we can do more Changes at a given time. If before the refactor the team made 10 Changes a week, they would now be doing 20 a week. The higher the rate of Changes, the faster the evolution process would be, the faster our Velocity would decrease. An outcome of a beneficial refactor should be a slower decrease in Velocity then before, a lower decay rate. It must overcome the increase in the rate of Changes that it would be causing.
We now need to ask ourselves, can refactoring be avoided? That’s the next chapter.