
One of the things I admire most about Amazon’s supply chain is the bin packing. When I order several things together, there would be one package waiting for me outside the door. I love efficiency. Furthermore, if I need to return one item I can return just that one item. I wish it was the same with an application’s Bundle.
The Hunt
At DealPly we did not really drop our pens and go home at 4pm. Sometimes I did so at 6pm but that’s not the point. We used to deploy only once every 3 days or so. The company was running about 100 EC2 servers which would autoscale fast when needed, a matter of a minute or two. Back then at the early days of AWS, a huge effort was required by a well experienced DevOps professional to achieve such capability. The build & deployment processes were complicated and long running. It was a matter of an hour or so to create a new AMI image with the latest application version and to replace all the servers with it.
When I joined the company our main application had already evolved into a Monolith and we had about 10 engineers split into three teams continuously making necessary changes to it. Upon deployment, the Bundle could easily include 30 something changes:
- 10 bug fixes done by the server team
- 5 new features to be A/B tested by the server team
- 10 changes to server responses done by the client team
- 5 changes to the sorting algorithm done by the data science team.
The company also had a BI team which created and maintained quite a tight monitoring system and for good reasons. The smallest drop in the company’s KPI of Clicks (which we were making money out of each and every one) quickly translated into tens of thousands of dollars lost by the hour. For a small startup company that is a lot.
If I remember correctly, each new deployment first propagated to 10% of the servers. Then we had to wait for 1-2 hours for a green light from the BI team (or have a look at the dashboards ourselves) before propagating to all servers. Unfortunately, there was also a red light which entailed a revert (sometimes to all the servers), a deployment freeze – and a hunt.
Usually the hunt was a matter of an hour or so. But sometimes it could have taken days. We had to go through each and every change that is already committed to main to find the faulty change. A single needle that was faulty in a haystack of 30 changes. The longer the interval between deployments, the more changes are accumulated. If a preventable or too long of a hunt is a time waste, an inefficiency, then the accumulation of many events are the cause of it.
When thinking of hunts, we’d naturally think of bugs. But we are hunting for changes. A change could also be a product change with an expected drop in Clicks that takes effect once deployed. In such cases or even when a combination of changes is the reason for the red light, it is almost impossible to distinguish between faults and expectations.
If instabilities are a waste of time, Velocity Drops, then changes are what’s causing it. That’s right. Each and every change has the potential to introduce instabilities. We must wonder as a thought for the future – why change anything at all?
Freeze, Revert, Freeze
Before the hunt even starts, we’d need to undo the latest deployment. To revert.
Unlike a package from Amazon, you can not return just one item. Alas we deployed a Bundle, an accumulation of many changes. A revert due to a single change is a revert to all the accumulated changes. This is a most dire consequence of a Bundle. Multiple changes are coupled together through the deployment process itself.
Once reverted, you are also moving your business backward, or at most postponing it from moving forward. Some of the changes reverted had the potential to make more money, as they include new features or critical bug fixes. They are all on a halt for a while. That is money not earned.
On the timeline, we can see the effects of a hunt, freeze and revert. The changes stop. Work stops.
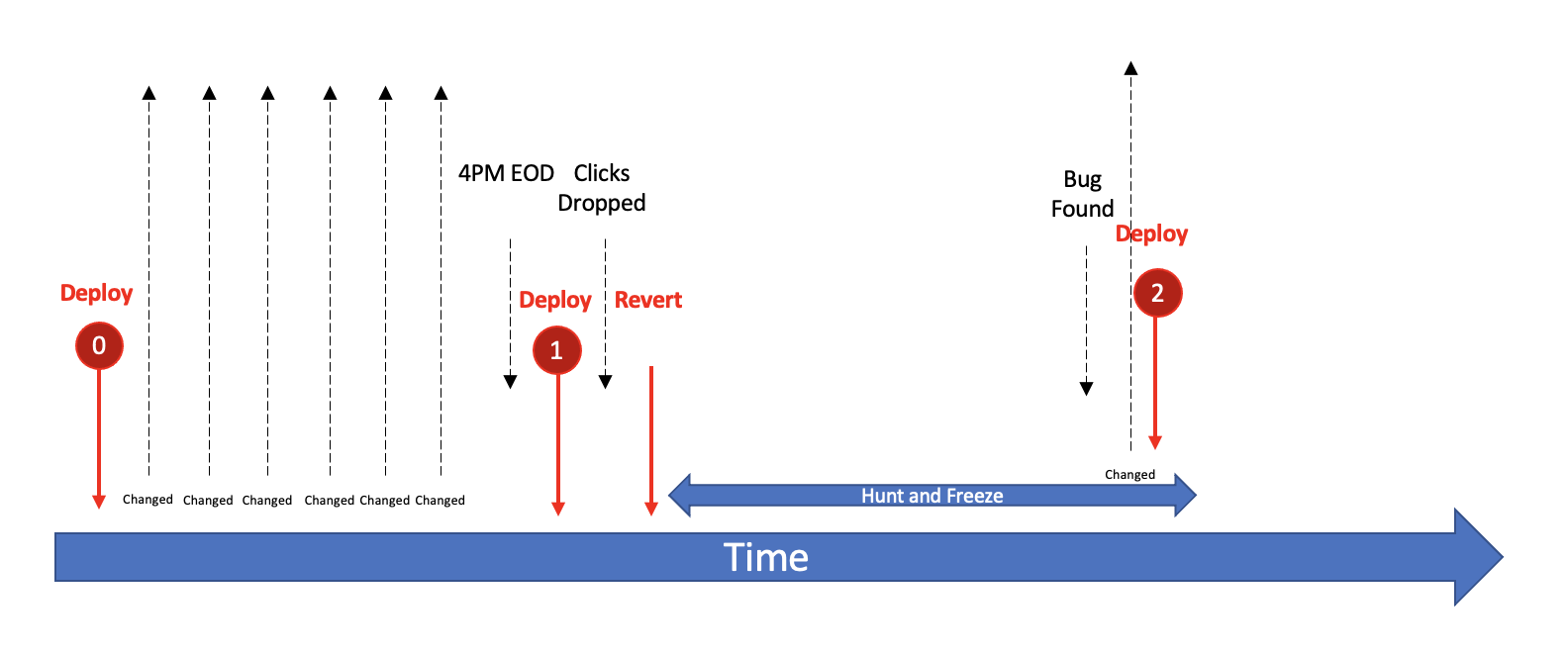
Unfortunately, we’d wish it was true and time would freeze as well. We were in a deployment freeze, not a version freeze. During freezes and hunts our excellent engineers kept on working and making more and more changes, more and more commits to the main branch.
The Bundle of Deloy (2) on the timeline did not have just 31 changes more than that of Deploy (0). It had 61 changes! The initial 30 changes of Deploy (0) + another change to fix the change that has caused the click drop + 30 new ones done during the freeze. One time we were not “lucky” enough and had to go to another hunt and then another hunt. It took us about three weeks to finish that deployment. All because a Bundle is an accumulation of changes.
Danger: Time Travel
After Deploy (1) there was a revert. Reverting is a risky operation. It’s an attempt to play with time itself. We are trying to go back in time, while time moves forward. Reverting is an attempt to restore our application to a previous state. That is not what we actually do. If we’d have a look at any git history, we’d see that a revert is another commit forward in time. Another commit is another change and we already know what change entails, a potential instability. A revert always creates a new state for our application. Only sometimes the new one is similar to an old one.
A revert of a deployment is a whole other story. That is reverting a running version to a previous one. Once again, that is not moving our applications and servers back in time. We are moving them forward in time to a previous state. Going back to a state may sound safe, because we’ve already been in that state. We’ve been to that state, but that state would be in a new point in time. This makes a revert even riskier than any other normal deployment. A deployment done correctly moves everything forward in time. Including the immediate dependencies. When a revert is done incorrectly, our application and its dependencies would be inconsistent in time.
Inconsistency is a source of trouble. For example, let’s think about integration. We’ve deployed a change that has altered a contract between our server application and our web application. We gave a green light to the client team and they have deployed theirs. Suddenly, we’d like to revert our server application. With a state of mind of going backward in time, we’d revert and break the integration. With a state of mind of moving forward in time, we’d think about it like every other deployment. Which we’d then realize that this revert would be a breaking change.
When a Bundle is reverted, with tens of changes, we’d be crazy to assume that nothing wrong would happen. Who knows if any of the 30 accumulated changes won’t be one that would cause a breaking change? Maybe more than one.
Now that we know the risks, consequences and waste a Bundle entails, next we’d try to unbundle it. To unburden ourselves a little.