
I don’t know if you had the chance to run into a family member you haven’t seen for 30 years, since he was a small toddler. If you haven’t, try googling “Brad Pitt as a baby” or any other celebrity of your choice. Your immediate reaction would probably be “OMG there is no way that this is Brad Pitt! He has grown and changed so much!”. Same goes for this very big Git repository you are working on. When it was first born/created, it was empty. A minute afterwards it had a single “main” file. And now you’re looking at it – and it’s old. It has grown and changed so much. It was not born as a Monolith – it has evolved to one.
We may have simply inherited it, or we just haven’t seen it happening right in front of our eyes – and by our own hands. Let’s dig in and see the process and causes that evolve applications into Monoliths.
Now is not the Right Time
Let’s go back to 2015 to a company called DealPly (true story). The company started with a single very specific flow, shown below as a pipeline. I guess that a few weeks into the company’s lifetime, each block had about several hundreds of lines of code. Each block was calling the one after it until the client request was fulfilled and returned.

It started off as something simple which correctly required a simple solution, a single monolithic application. Naturally, with the company’s success the business grew and became more and more complicated. It happened both as expected and unexpected. It’s expected that it would have happened, it’s unexpected what exactly would happen. The business grew and the backlog along with it. More and more tasks were added, which originated from product requirements.
In order to imagine what the engineers had to go through, let’s randomly pick one out of hundreds of these tasks and put ourselves in their expensive shoes.
We’ve been given the task to code a new filtering algorithm into the Filter Offers Block. We gave it a quick look and estimated it at 4 days. We’ve also said that if the design was different this specific task could have been done in half the time, 2 days only. Moreover, we said that each future similar task would be cut in half as well. It seems like now is the right time to do it. Unfortunately the redesign effort would be about 10 days of work. Two weeks seems like a very long time. We’d need to invest 8 extra days of work now in order to save 2 days now.
Suddenly this now seems more like never. Because the effort of a specific task is marginal to a somewhat vaguely needed change. And a redesign is not as valuable as pushing the product forward.
To decide not to redesign could be the right choice to make. It may not be beneficial because it would turn out there is only one future similar task to execute in the upcoming weeks. It could also be the wrong choice as it could also turn out that this one future similar task would take 30 days and we did not do what it takes to cut it in half and make it into a feasible one. That’s how it is when dealing with the unknown. We take calculated guesses.
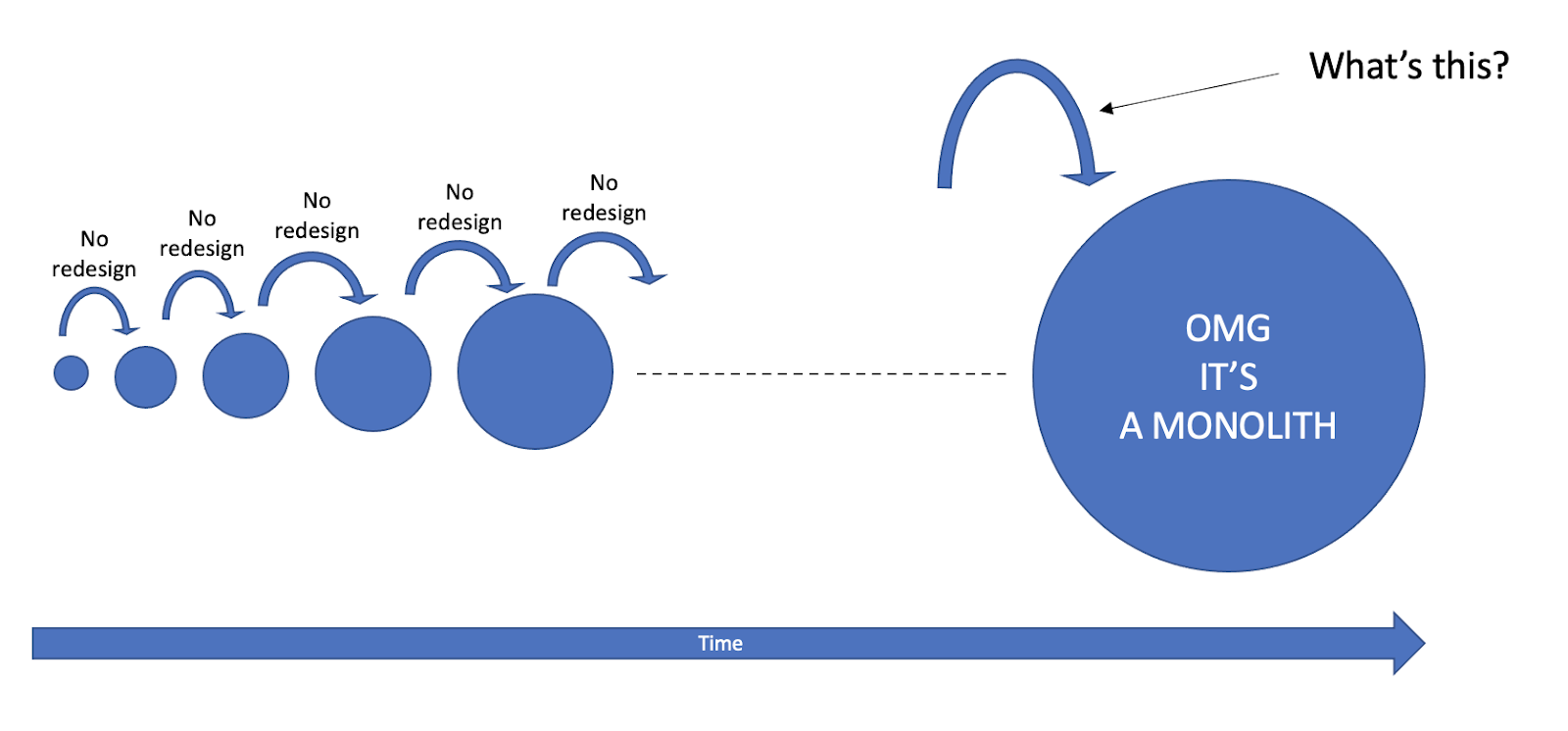
Alas it’s not a question whether we made the right decision to redesign or not. It is also not a question of effort and value. Every time we choose not to ease our development now (by redesigning, a refactor, etc), the consequences would be marginally and unnoticeably evolving our application into a Monolith.
We make a lot of these small decisions on a daily basis. They are so small and their results are so marginal that in order to become a Monolith it has to accumulate enough. Even so, we only notice that we have a Monolith on our hands when something happens. And by then it has accumulated too much.
Later in this series we’d investigate the consequences of choosing to do a redesign or a refactor.
The Flood
The accumulation continues unnoticed until something happens. In order to understand what happens and when, we’d need a different perspective on the work done in DealPly. Let’s have a look at it from the application’s design, the class diagram, to try and uncover this.
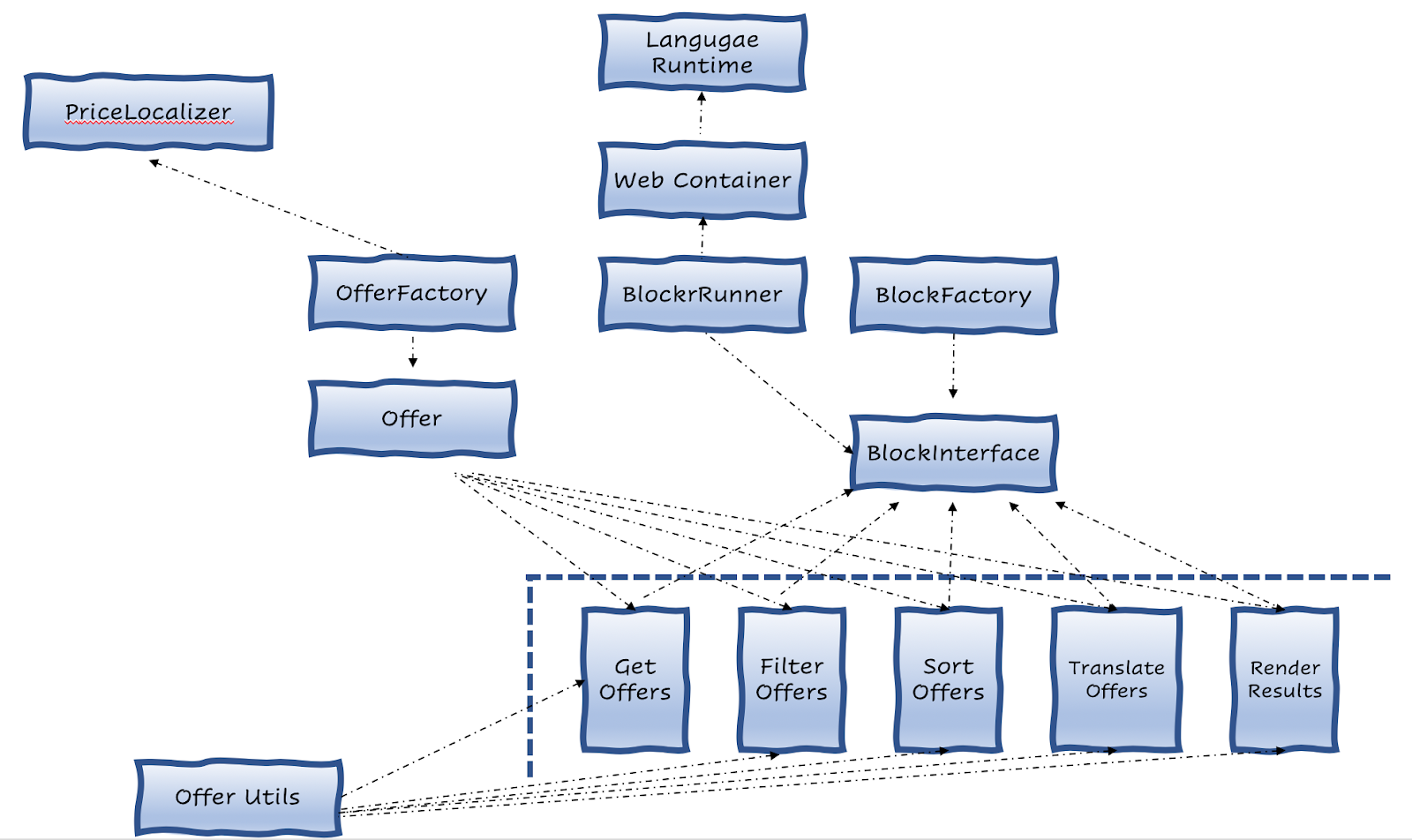
At the bottom right we can see that for each block in the business pipeline (the previous diagram) there is a respected component (most likely a Class). Each one is indeed mutually independent from another.
The application’s design perspective shows us some in-direct dependencies, ones that an engineer treads on while coding almost any task given. Some are more environment related (The BlockRunner, the Web Container) and some are more business related (Offer and Offer Utils).
We’ve picked the task of adding a new filtering algorithm. What does it include? Indeed 95% of the coding done would be within the Filter Offers component. Alas the other 5% include just a simple touch to the Offer Utils class, just to change a single line of code to it. Nothing more than a simple if condition.
As engineers we are extremely focused while coding, as we should be. Cognitively, we would not be looking at the other components who use Offer Utils and the function that he has changed. We have no reason to as it’s outside the scope of our task. We do nothing wrong; we are a mere living being cognitively focused on a task at hand and on the component we need to work on. Even if we were to have a look, how would we know we introduced a bug? It is a code we are not familiar with of a business flow we never knew existed in the first place! We would deploy it to production with a “bug” and we all know what happens next. We thought that we finished the task, but it turns out we were wrong. Now we need to drop everything we do, trace it through the unknown code and fix it.
A better scenario would be that our code is sufficiently covered with tests. We’ve only broken some unit or integration tests. We have avoided bringing down production which is good on its own. Now we’d “only” have to put effort into investigating what was wrong, fixing other people’s code that we’re not entirely familiar with, or re-do your entire work.
To break a test is far better than bringing down our production environment, or to hurt our customer’s experience. Either way, the consequences would be an extra effort on top of the actual coding after we are done with the actual coding! The frustration this does to us! It seems like it’s our own doing but it’s definitely not our own fault.
Personally I’ve seen this extra effort measured in days. What we may have not seen is that the extra effort grows into being measured in days. As the code grows, the extra effort grows. Every change we commit has the potential to affect more code – because there is more code.
Today we may spend 10 extra days of effort.
These 10 days were only 8 days 6 months months ago.
These 10 days were 5 days only a year ago.
These 10 days were just one day two years ago.
The above would be us looking back at time, “after the crime”. As time moves forward we should also be looking in a forward direction, “before the crime”:
The extra effort is 1 day today.
As the code grows, a year from now the extra effort would be 5 days.
As the code grows, a year and a half from now the extra effort would be 8 days.
As the code grows, two years from now the extra effort would be 10 days.
It’s not what we haven’t done in the past that costs us. It is, but it is not the cause. The cause is what we decide not to do now that produces a future cost. It accumulates, so it is only a matter of time until what was supposed to be an internal encapsulated change resulted in changes throughout the code base and ended up wasting days of extra effort.
This is the event that causes us to notice that we’ve been working on a Monolith for a long time now. The event in which we spend too much time on a single task to finish it without any problems. Where we tell ourselves “we can’t work like this any more”. Where we are way too frustrated with it.
It is sudden not because we’ve done something wrong. It is sudden because it has been accumulating “under the surface” through a series of small decisions taken, the ones we’ve investigated at the beginning of this chapter. That’s the consequences of it. What was missing was a specific task that has taken a noticeable amount of extra work. And this was the task that has caused us to see it already is a Monolith.
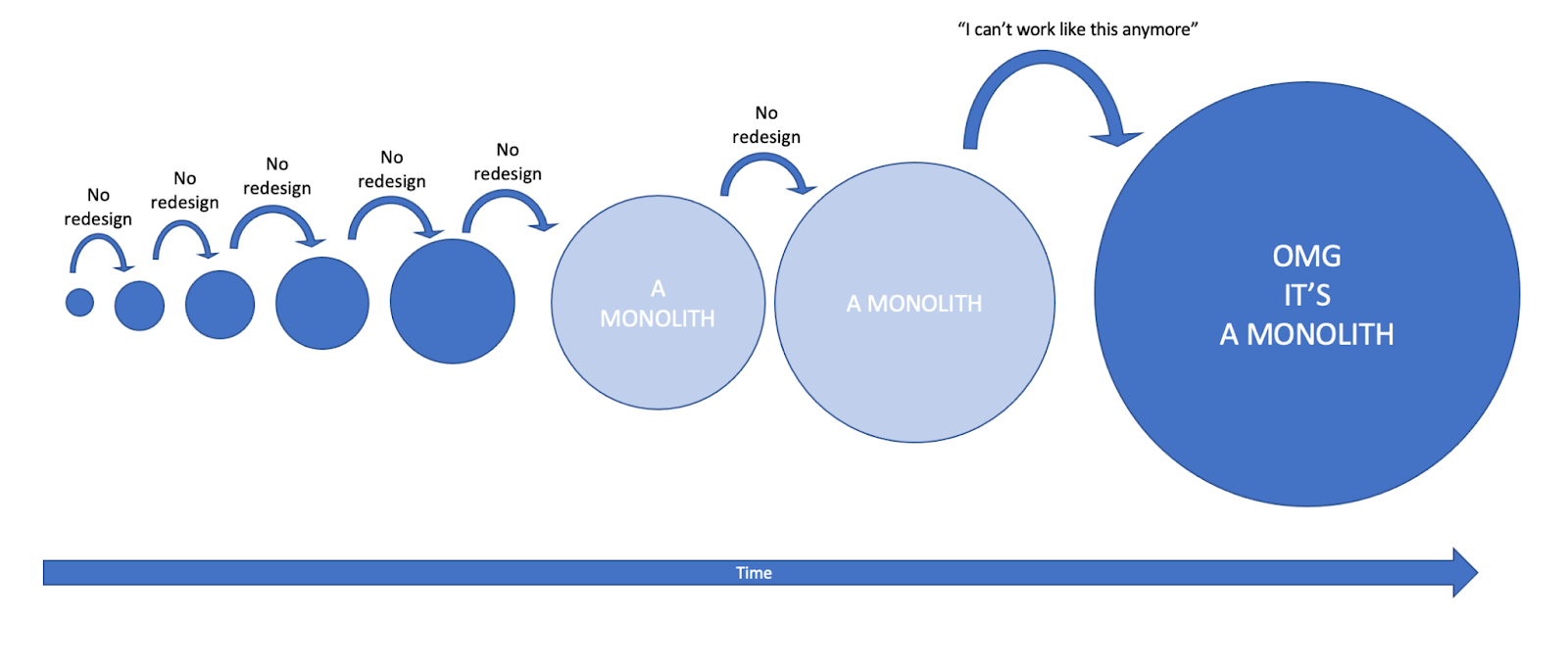
We shouldn’t feel bad about it. That accumulation effect and the inability to notice small differences under a certain threshold, is a cognitive issue known as Sensory Threshold which for us living beings is hard to overcome. That is true both for code growth or growth of extra effort.
Time of Need
There is another element to the evolution process that we need to put our mind into. And that is time itself. If we were to have another look at the above diagram, we may notice that we haven’t given enough thought to the x-axis of time.
Let’s start by looking back at history. Having a single monolithic application is a design choice or even a design pattern. And it’s been around for decades. It is still a much valid, very dominant, sometimes even a needed one. How come suddenly out of nowhere so many have evolved to being “Evil Monoliths”?
Think of the big companies of 30 years ago, like SAP or Oracle. The Service Oriented Architecture design pattern already existed back then. It was very hard, complicated and costly to set up and maintain it. Big companies had the financial and technical means to go with non-monolithic solutions. And it also was with great value to them. But before means and value they had the need. SAP, Oracle and others were big enough to need complicated solutions. And there weren’t that many of these companies around. For small companies trying to solve “small” problems, a single monolithic application was good enough. Still is! What is also true is that problems grew bigger since then. Small companies are trying to resolve really big problems. They were called startups.
About twenty years ago in the early 00’s, after the dot.com bubble burst, if you wanted to find a plumber in your vicinity, you’d go to yellow pages dot com. You’d click through the appropriate categories, type in your city name and you’d get a list of a few hundred plumbers. That’s what Yellow Pages was back then, a simple index of service personnel. It might have been a complicated project but once it’s done it is done. The problem of finding a plumber has been resolved.
However in 2021 if you were to found a new startup company it would be a platform for continuous household maintenance. A platform that will know in advance when to send you the most honest plumber as reported by your neighbors, by the week’s end. The platform will also integrate with your Smart Lock to give the plumber a one time access. And while he’s there he will be monitored, graded and analyzed through Smart Cameras. Two years later, the platform will extend to carpet cleaners, and air conditioning repairs. Four years later it would also expand to continuous office maintenance and continuous car maintenance. The problem of getting everything fixed correctly and on time will never be fully resolved.
Don’t get me wrong, I’m not complaining. Thinking big is what drives innovation. Innovation drives good engineering. I’m an engineer. I get the chance to do good engineering because people think big.
30 years ago not every other company was trying to be the next something. Back then, applications did not have neither the reason nor the time to evolve into Monoliths. Today there exists a reason for the code to grow. Today we are trying to resolve an ever growing problem with an ever growing solution that continuously changes. And as the problem is a never ending one, there exists enough time for a single monolithic application to evolve into a Monolith.
If we are working on a small finite problem, a single monolithic application would do. If we plan to change the world, we should expect that a single monolithic application would Eventually evolve into a Monolith. We should consider how soon it will happen and that it will always hit us at the worst time possible [see Second Year Syndrome].
When it does hit us it would then prevent us from changing the world efficiently. Which is what we’ll be talking about in the next chapter.