
In the previous chapter we’ve seen the difference between Technical and Non-Technical Causes. It is easy to find mutual exclusivities within the cluster of Technical Causes because indeed they are somewhat naturally independent. However, Products are naturally intertwined.
We had to find another way to find a mutual exclusivity within the Non-Technical cluster of Causes. We’ve done so with a method that tricks our binary thinking minds: what shouldn’t Change together, shouldn’t Change together. Unless we really really really need to. That would force us to cluster our Causes into mutually exclusive ones, and create Directions within the Change Stream.
Alas, when we applied the above on our design we also made a mess. We indeed created a Direction per Product, but the Product Modules were unable to Change together at all as we do sometimes need. They were too independent, and were unable to reach all the way over to the Non-Technical Modules.
In this chapter we’re going to resolve this mess, starting with finally understanding what Products are.
Go with the Flow
Let’s continue with our story from the previous chapter, of an auction eCommerce website who serves Sellers and Buyers. Both of them not only share something, sometimes they go through the same things. For example, both Sellers and Buyers need to pay. The Sellers need to pay us for our website’s service and Buyers need to pay us for the Seller’s item.
When they are both done adding items to the checkout basket, they need to go through Payment. They’ll both select a Payment method and a Payment plan, review the order and confirm it. Once done, the most amazing thing happens – the Buyer goes back to being a Buyer and the Seller goes back to being a Seller. They would also later be able to go through their Payment history.
Let’s examine what going through Payment is. It starts with a user taking one step. And then another step. And then another one. There is a name for that thing we do when we take one step after the other, a journey. So I guess it is no wonder that some PMs call it a User Journey. Those are technically known as a procedure, a process or a Flow. And while someone goes through it, steps may change a state which can later be viewed. [We’re going to use the term Flow as process and procedure have a technical ambiguity]
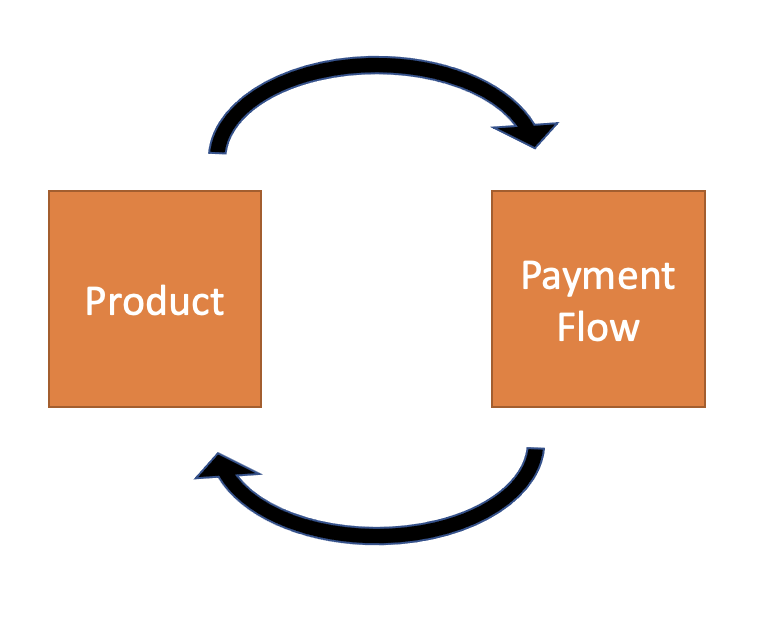
Now, no matter who you are and what Product you are using, a Buyer or Seller enters the Payment Flow and once they are out of it they go back to the Product they came from. We’ve actually already seen that kind of separation, where an intersection between Modules is a Module of its own. It was a suggestion on how to overcome tunnel visions.
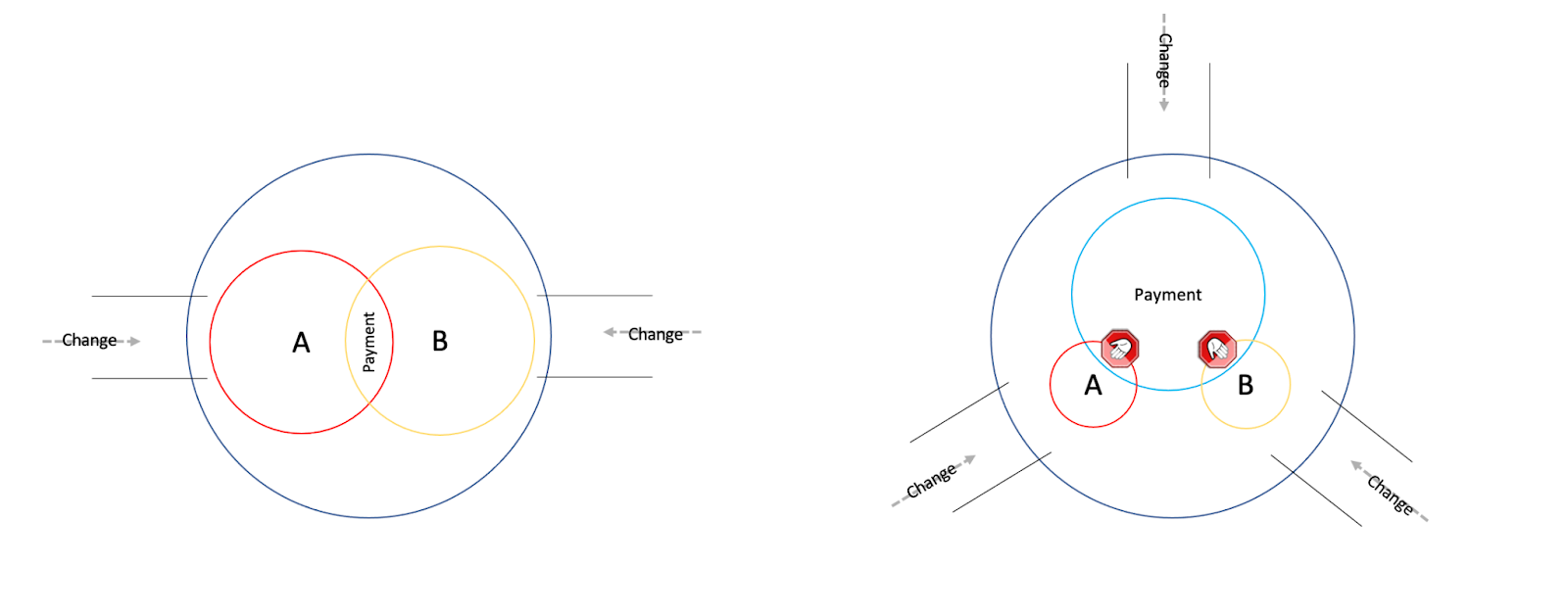
There is the Buyer Product (Module A) and the Seller Product (Module B). There is Payment which is shared between them and they are both dependent on it. In the right design above, we’ve added another Direction of Change, as Payment has its own closed set and cluster of Causes.
There is no Product
I think we can agree that Module A and Module B are Products. But in chapter 3 we’ve said that Payment (Module) C is a Product, and in this chapter we’re saying that it is a Flow. To answer which one is it, we have to consider time.
Given enough time, something born as a Flow will eventually grow into a Product. It can also be born as a Product with exactly one Flow, and we already know what it will grow to be – the already grown Buyer and Seller Products include at least one Flow.
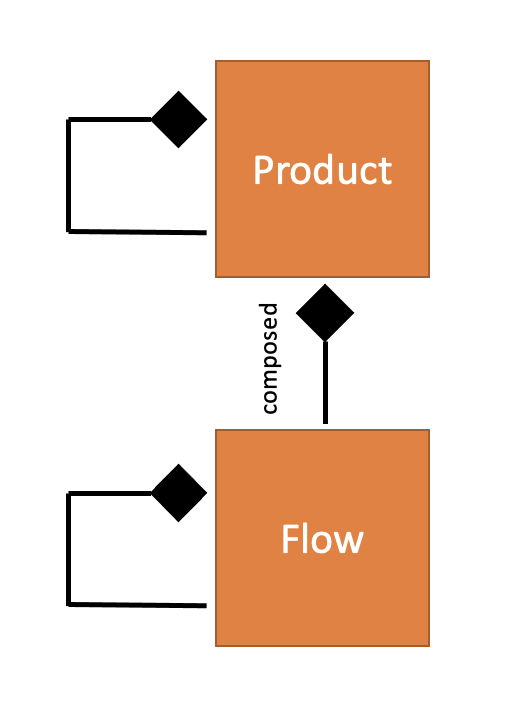
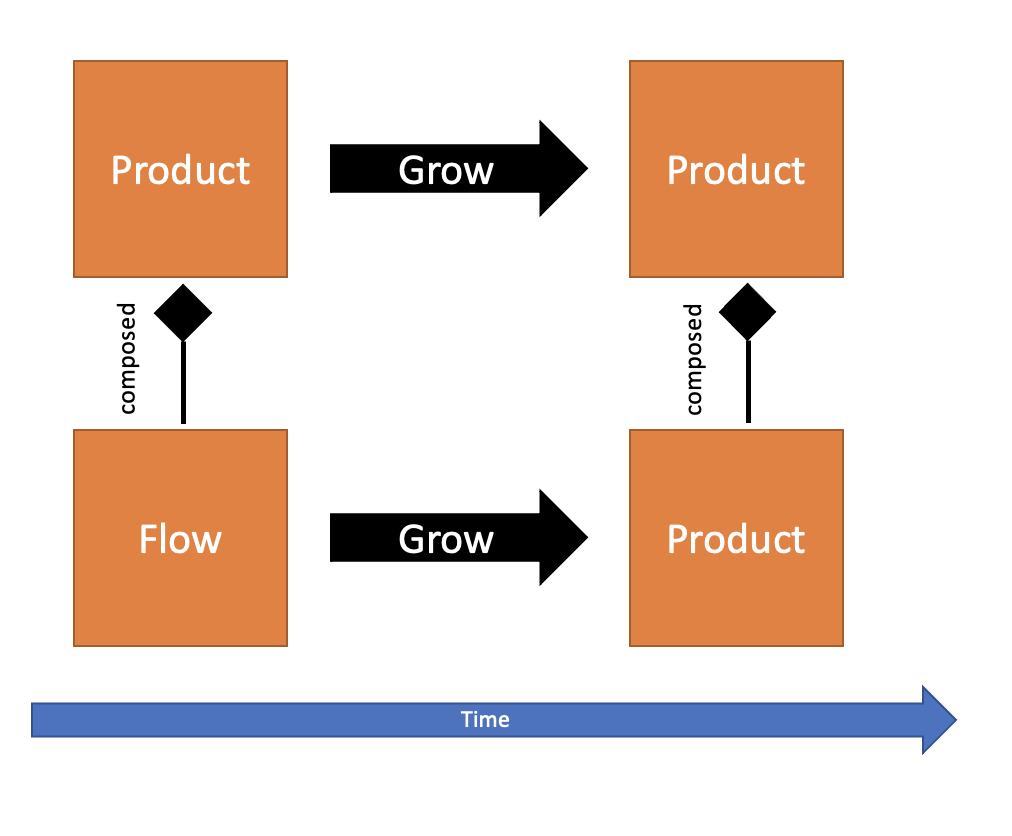
Product is an entity composed out of other Products or Flows. A Flow has a state and a view that might be shared with the Product. Viewing a state is just another User Journey, another Flow. Flows can be composed of Flows.
But we kind of already knew that, because instead of calling it a Flow we tend to call it a Feature. A Product is composed of Features, and when a Feature grows “big enough” it turns into a Product of its own, that is now composed of smaller Features. Products and Features are nothing more than an ever changing grouping of Flows.
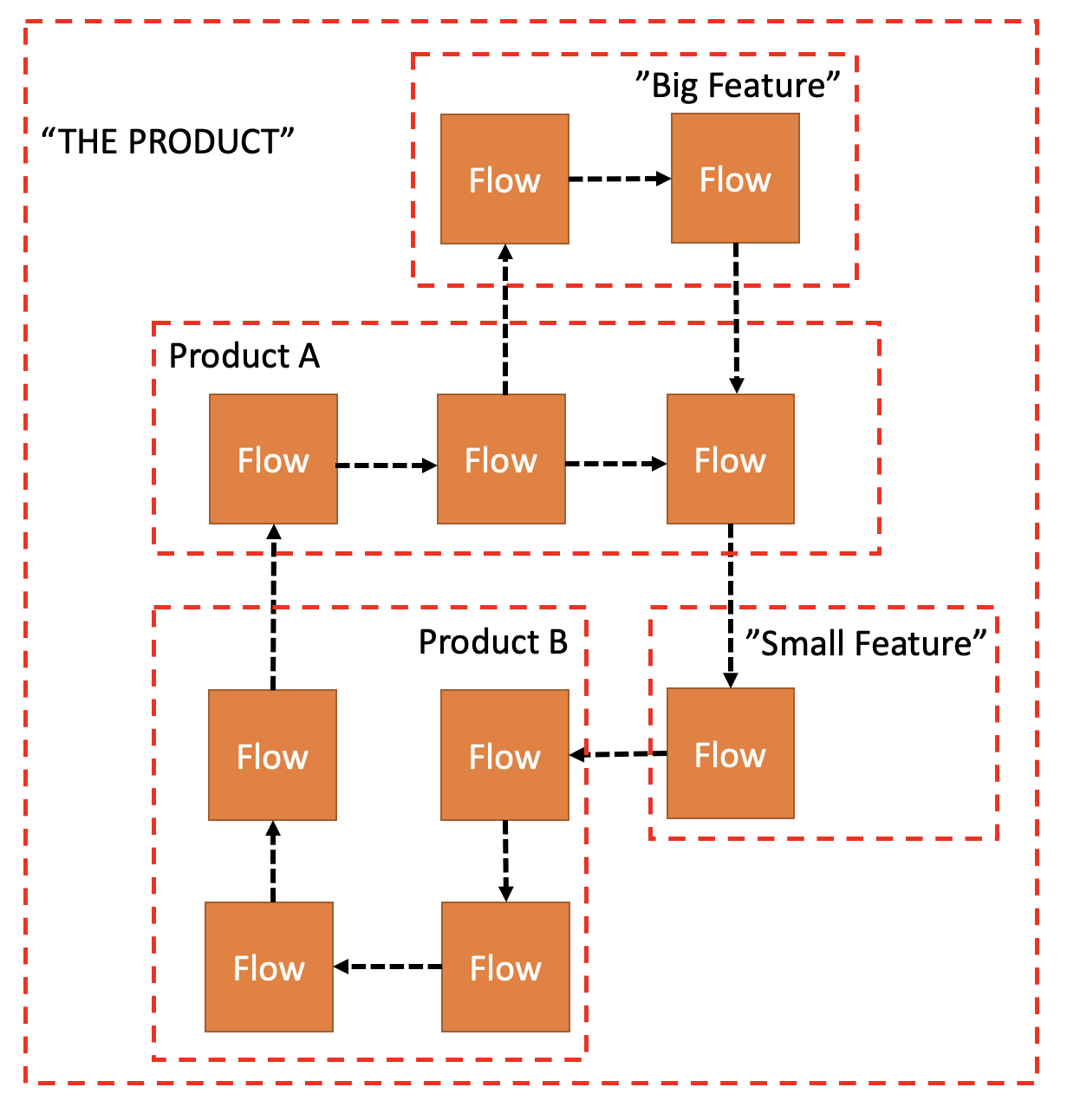
Seeing it as so explains why the cluster of Non-Technical Causes can be further divided into smaller mutually exclusive clusters of Causes. Product A (Buyer) has its own Causes to Change, and so does Product B (Seller). Same goes for “Small Feature” (e.g. Login) and “Big Feature” (Payment). As such, each one has its own Direction with a Module at its end, with all the beneficial outcomes of it we have seen before.
But still, if the Causes are indeed mutually exclusive, how come Products are so intertwined?
Doing Business
Let’s go back to our design. We have three Products that should not Change together, who are also composed of Flows. We ended up making them independent and completely isolated because of their mutually exclusive Directions.
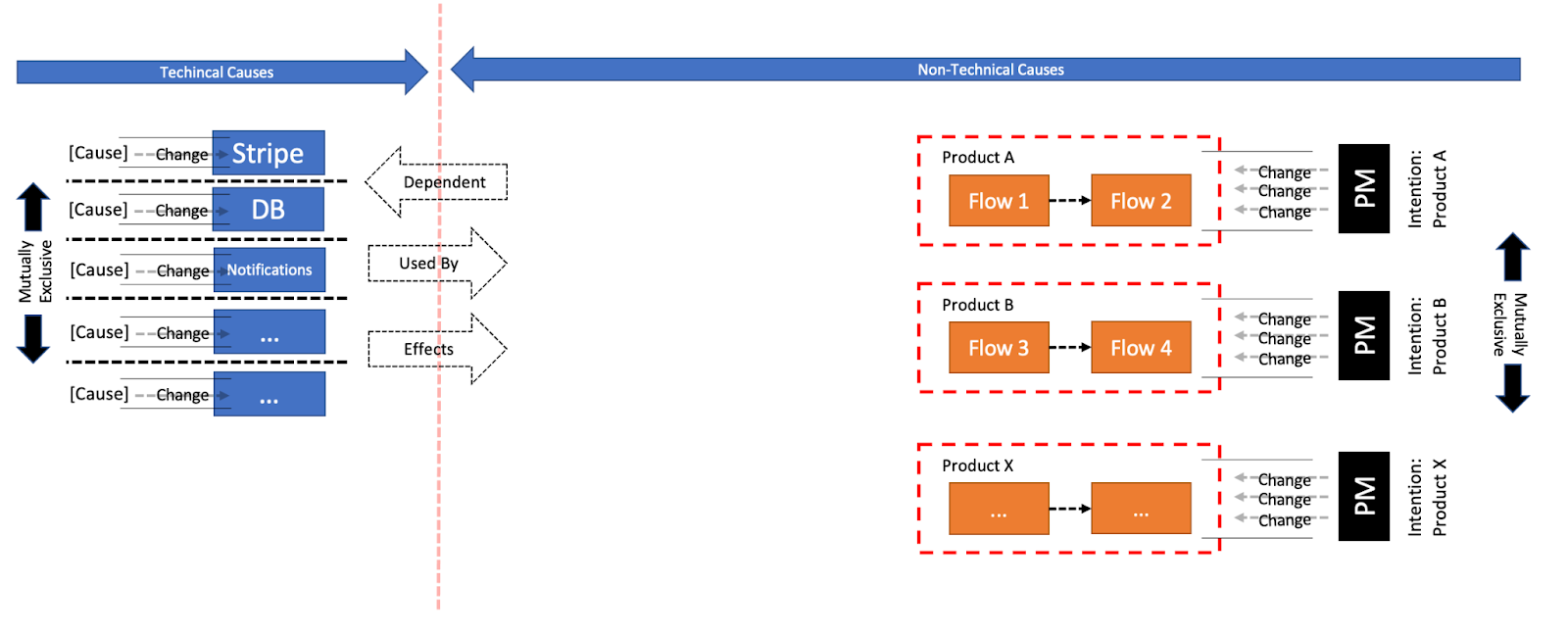
Flow 1 and Flow 3 share a common, but they belong to two isolated Products so they can not share it. For instance, as prices are shown both to Buyers and Sellers they share something called Pricing. Let’s create that entity and also presume that in order for it to calculate a price, it requires data stored in both Stripe and our DB. The pseudo code would be:
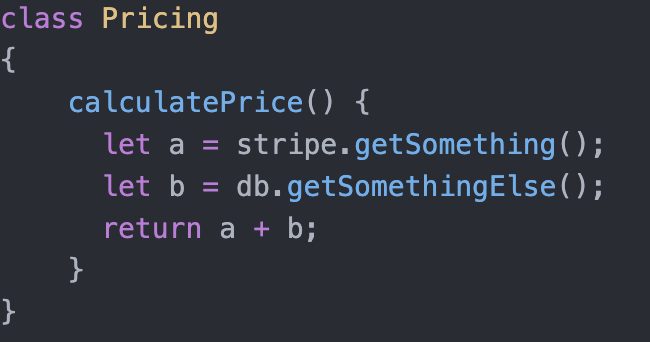
But, if we’ll look at the Directions of Change we’ll see a mistake being made.
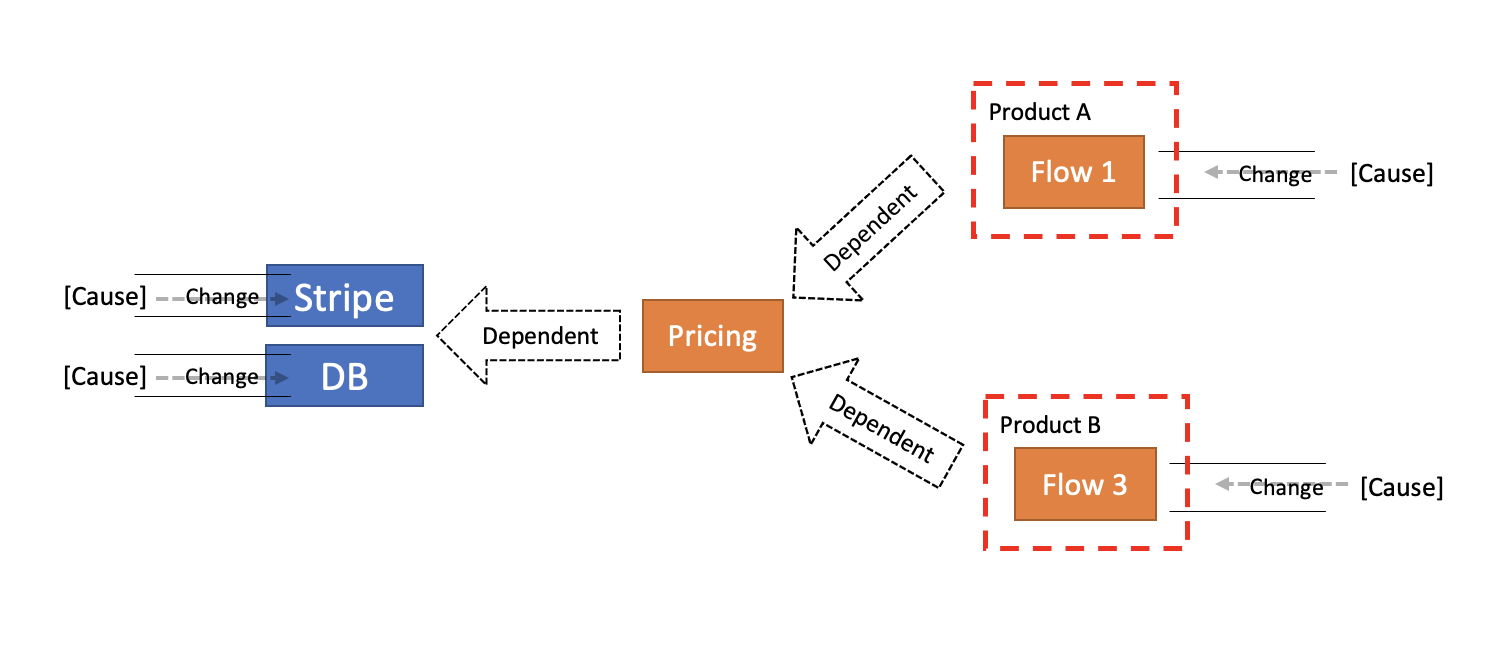
Sure, Stripe and our DB are encapsulated from our Products, but Pricing is our own company’s internal doing. No reason for a Change in Stripe to affect it. Stripe and Pricing shouldn’t Change together . Both aren’t even within the same reach and control. Same goes for our DB, if we will eventually replace it with another, it should not affect Pricing. DB and Pricing shouldn’t Change together.
Now, let’s say there is a Cause to Change Product A and it involves Pricing. That would be a Change going from Flow 1 to Pricing to DB. This is a Change cutting through layers, a symptom of and a tendency of Products. It is exactly the same one big Change of right-to-left that should be done in smaller ones.
We already know how to overcome all of the above, by adding another Direction.
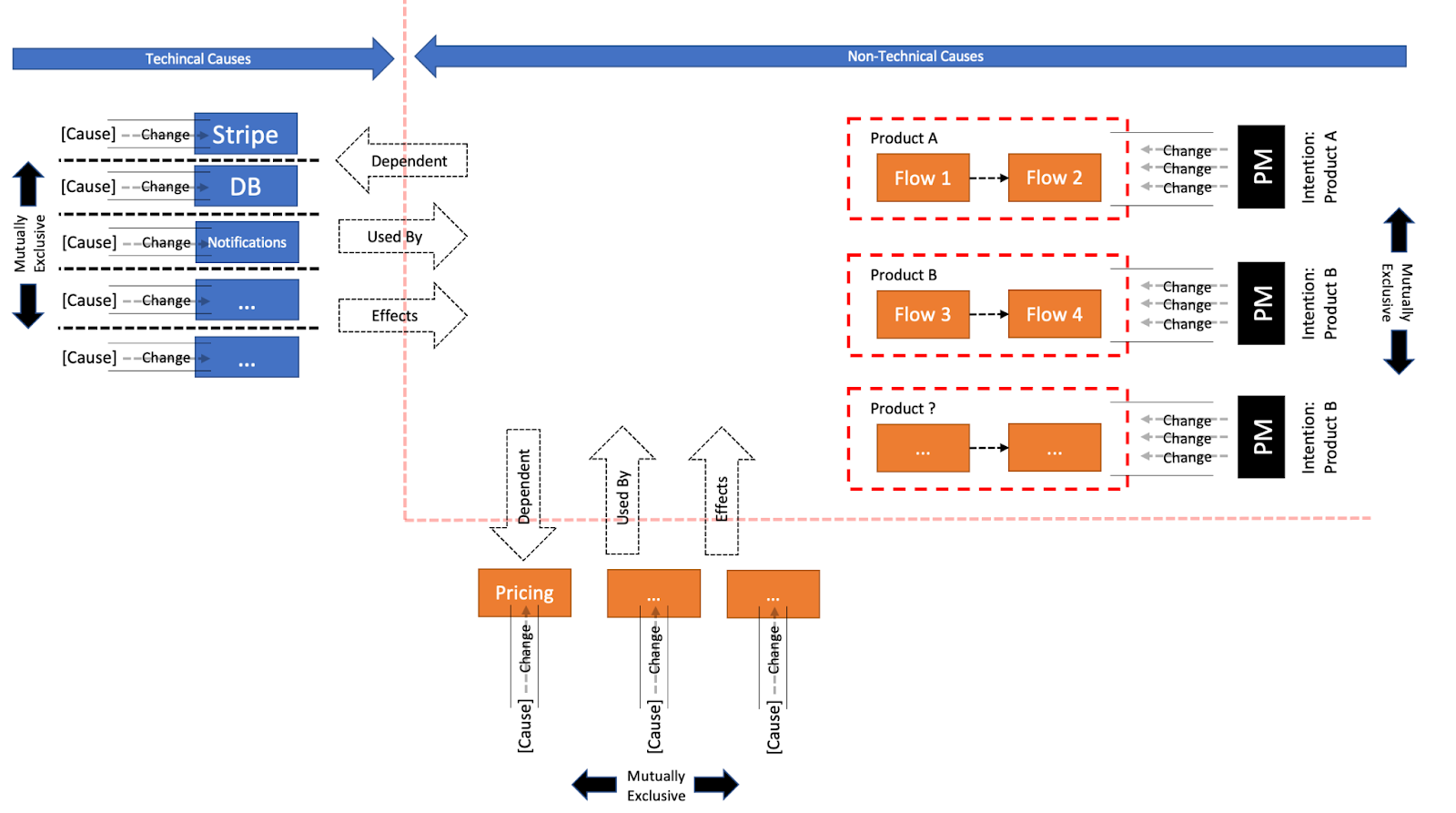
Product A and Product B should not Change together, unless we really need to. We made sure we could by doing a few small Changes. If Pricing needs to Change for both, it can with one small Change through its own Direction, resulting in Changing both. If a follow up Change to Product A and/or Product B is needed, that would be two more small Changes going through their respective Directions. If we have the Intention to Change only one of them, we’d have a stop sign at the integration point with Pricing to warn us and prevent unintended consequences.
As Pricing’s Direction is mutually exclusive, it grows independently from any other entity. Meaning we can design it uniquely. As it also does not depend on a Flow’s state or on data, Pricing can be composed of pure functions, making it far more testable. It could even be coded in the more suitable Pragmatic way, even if Clean Code fits the other Modules better. No need to enforce styles where they are non-beneficial. Most important, Pricing is reusable, which is exactly what our Flow Modules requires it to be.
Which brings the question, what kind of Module is this or better yet what it isn’t. It is neither a Product nor a Flow Module, but what Changes it are definitely Non-Technical Causes because Pricing isn’t a Technical. I think that these kinds of Modules are what we commonly call the Business Logic. But that is not a mutually exclusive name, so we better not fall into a false dichotomy caused by our binary thinking minds yet again.
Flows & Currents
As Pricing is an independent Module, someone else needs to get the data for it as an input. The data that is all the way over at the Technical Modules. I guess some other kind of Module will be needed. One that will get the data, pass it as an input to Pricing, and then.. well I guess it will show the result to the end user.
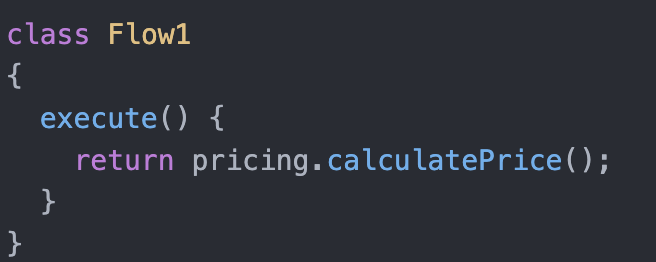
I’m not sure what this Module is but it’s pseudo code of it would be:
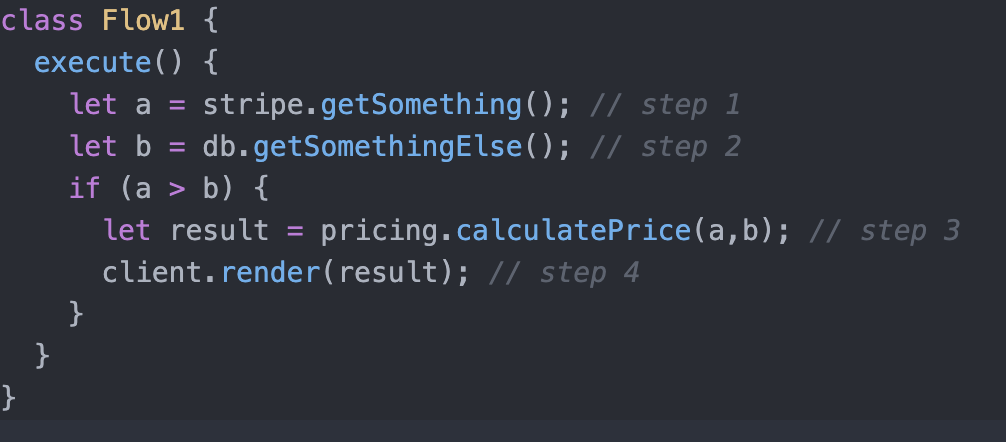
Surprise! It’s the Flow Module! It’s code is literally doing one step after the other which is exactly what a Flow is. The result is expected to be a simple, readable and maintainable code that correlates and reflects the User’s Journey and the various paths it takes. With the details kept short and encapsulated as it’s unfamiliar with the exact details of Stripe, DB and Pricing.
Flow Modules are easily composable and allow users to journey between Flows and Products, because they are composed of it! As long as they maintain the integrations between them, in our case its the function’s signature, they will grow independently. Which coincides with their Direction of Change, and of its beneficial outcomes.



That is more than just a theory and pseudo code. Luckily or not, there are several design patterns dedicated just for this kind of Modules. Two design patterns I know of are State Machines and Chain of Responsibility (A.k.a pipes and filters or pipeline). And there are probably more.
One Last Dichotomy
Out of this family of design patterns, we can find a name that will better help us define the distinction between BL (Business Logic) and Flows, as these names are a false dichotomy. And honestly, it’s hard to make the exact distinction between the two kinds, which code goes into which.
We’ve defined BL to be independent and of pure state, and Flows have and manage states (do not confuse state and sessions, although they do relate to one another). So a mutually exclusive name would be Behavioral v.s. Non-Behavioral Modules. This extremely correlates to the difference between Test Driven Development and Behavior Driven Development. There might be other Behavioral Modules that are not Flows that we are unaware of, and there could be other Non-Behavioral ones that are not Business Logic that we are unaware of.


As we have two overlapping dichotomies, we must pay attention to:
- All Technical Modules are Non-Behavioral ones
- All Behavioral Modules are Non-Technical ones
- No Behavioral Module is a Technical one
- A Non-Behavioral Module can be a Technical one and vice-versa.
That leaves us with what Non-Product Modules are. They can be Non-Behavioral, such as an offline asynchronous process that syncs between Stripe and our DB. They can also be Behavioral, such as Silo’s update flow we’ve seen in the previous chapter.
No matter what Non-Products are or how we classify them, no need to refactor our application’s design to support those. They can reuse Non-Behavioral and Technical Modules as they need or please. Our design is open for the future Changes, which is what we previously called designed for Changeability, which postpones the erosive evolutionary processes caused by Change.
Finally we’ve finished designing a single application, not only as an intro to designing multiple ones which we’ll do in the following series Breaking Change. Throughout this journey, we’ve learned how to model applications and what to consider during design. More than that, we’ve learned how to model a reality when we modeled Products, Flows, Causes, Directions, the Change itself and the Change Stream.
In order to prove to ourselves we’re on the correct path, we’ve had the guiding light of the evolutionary processes. To use them, we had to go beyond Good v.s. Bad. Whatever postpones them is beneficial, what hastens them is non-beneficial. And as the outcomes of a design are never immediate, we had the eventualism framework to work with.
Now we are ready for the last piece of the puzzle, to the one subject we left unknown on purpose, in order to make sure our design would be agnostic to the Source of Change. On this, in the next chapter.