In the previous chapter, we’ve argued that size doesn’t matter because size is not constant. It is ever changing through time, and is an outcome of Throughput and an application’s design. On the contrary, we’ve seen that size is a technical limitation. After we’ve seen the real tradeoff between the two, of penalties and Inefficiencies, we’ve come to the conclusion that cohesion matters and not size.
If it’s not about size, we are left to wonder what Microservices really are. In this chapter we’ll try to figure it out, first by continuing ruling out what it isn’t by taking a stroll down memory lane.
First, we should correct a common historical mistake I’ve seen around. Microservices were not born out or as an answer to a single Monolithic design. It’s not one or the other. Historically speaking, between the two was the Service Oriented Architecture and Messaging. Microservices came to fix its faults: “Netflix makes the link explicit – until recently referring to their architectural style as fine-grained SOA”. (see footnote #7 in Martin Fowler’s writings about Microservices). For us to better understand what Microservices are, we need to compare it to SoA and not to a Monolith. So let’s go!
HTTP API
It is frequently mentioned that every microservice must have an HTTP API. That is not 100% accurate. In the heart of SoA exists a centralized message broker, a communication layer that asynchronously sends messages between multiple applications. Each application independently and continuously consumes these messages in order to react and/or maintain consistency between them. These applications were called Services, and only them.
A message broker is a very complicated distributed application to make and requires vast resources. In the days before open source and cloud/IaaS providers, only a few very large enterprises made those. Microsoft and Oracle were the biggest two and they sold message brokers to other large enterprises. And they made the greatest effort to make sure we won’t be able to easily switch to any rival. Their customers quickly ran into a vendor lock.
Among other things, they made it technically hard to do so. The message broker communicated with applications with a proprietary communication protocol both in the transport layer and the application layer. If you had a message broker by Microsoft and wished to switch to Oracle’s you’d have to refactor all of your Services, ensuring the switch would be a financially hard thing to do.
A non-proprietary communication protocol would prevent that technical vendor locking, and this is why it was decided to be a must. The most common one back then was TCP/IP due to the rise of the Internet. And as it was already a standard and unified transport layer, it was better to skip right ahead over the application layer and HTTP. Today, there is nothing preventing the usage of other open source protocols, such as MQTT or Google’s Protobuf.
Points of Failure
Speaking of a centralized message broker, it goes without saying its cluster is a single point of failure. If the cluster went down, the entire company went down with it. And they were hard to maintain. To make them highly available, running a cluster of 3 to 5 instances, not only required expertise but was also extremely expensive and required a long implementation process measured in months.
As Reliability and SLA were a challenge, in Microservices there is no message broker or anything centralized. Either direct HTTP calls or an obfuscation of them with a distributed service mesh, such as with Istio’s Envoy. As there is no centralized point of failure, there is no single point of failure. Which is quite brilliant and cheaper.
So, if Reliability, SLA and costs were an issue back in the early 2000’s, it is not always so today. Maybe even the other way around. Today, where we have IaaS and Cloud providers, it is within a Infrastructure-as-a-Code module to deploy a message broker with 99.999% availability/SLA and with barely any maintenance overhead. Almost zero setup and maintenance costs. and with pricing per usage and/or actual running time, it is definitely cheaper than 20 years ago. It may end up being cheaper than a service mesh, which requires a dedicated CPU per Service instance.
So, if a service mesh can obfuscate a distributed communication layer, it can definitely obfuscate a highly reliable message broker. Both would have no effect on the application itself. It would have a non-proprietary communication protocol anyhow.
[Note (September 2022): I did not refer to a component called Service Discovery/Registry. Typically it may be beyond the responsibility of a message broker, or it may not even be able to integrate with it. On AWS, SD/SR is handled by the load balancer and SNS can not integrate with an external SD/SR.]
Furthermore, making a chain of synchronous HTTP calls 99.999% reliable, is quite the challenge. There would not be a circuit breaker between them, and it is said that any system large enough would eventually require asynchronous processes anyhow.
Distribution
In both Microservices and SoA, it is needed to distribute and deploy applications between multiple servers. And it has been forever possible, but was hard to do. Nothing ever prevented us from running multiple processes on the same machine. Although it is less reliable than running it within Containers. Nothing ever prevented us from running a single process per machine to overcome that, but it is expensive to do so. Nothing ever prevented us from manually distributing Containers and processes between machines, but that’s what an orchestrator is for.
It was the progress made in infrastructure that enabled and eased both SoA and Microservices. But both architectures came to life years before so. The concept of Microservices had started forming up in 2004-2005, and matured in 2011. Docker containers, the stepping stone of the technological advancement made, was only released in 2013. And SoA was in existence decades before that.
More than that. Nothing ever prevented us from distributing our applications to other companies. Applications installed in our customers’ servers have been in existence for a long time. Software packages and SDKs also had been distributed for years. But here lies what differs a microservice from anything else in the past.
Breaking Boundaries
When we talked about Rollouts, we talked about boundaries and ownership. Both Packages and Agents have something in common. They are owned by us, but placed in someone’s else’s territory.
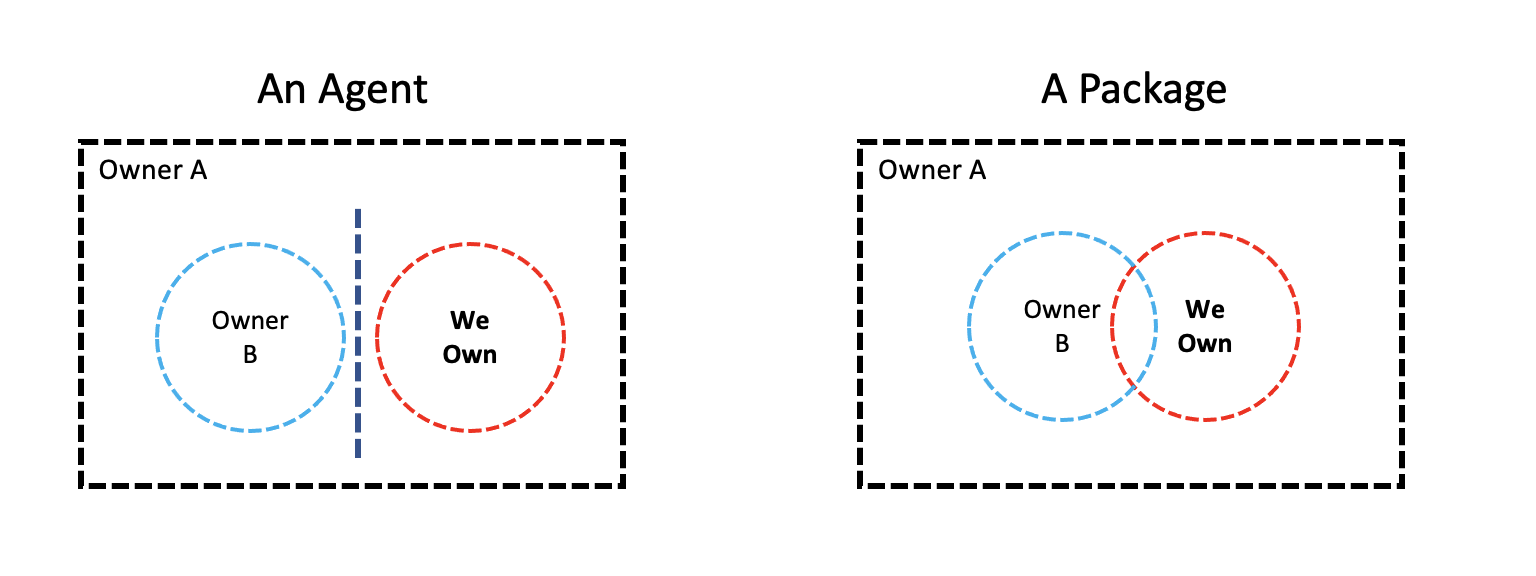
An Agent is an independent application placed adjacent to an application owned by someone else, on a server owned by maybe even a third unknown entity. If we notice carefully, this relationship also applies to other applications such as databases. On the contrary, a Package is something we own and is placed inside an application owned by someone else.
In both cases, it is the territory’s owner who decides when to update and not us who actually owns the application. As a result, a Rollout can be a matter of days, weeks and months. Our control over it is limited, if at all. While with some effort, an agent can self-update itself, a database mustn’t. And a package simply can not. Or can’t it?
Let’s see how we can theoretically and quite practically turn every Package to an application. What we need is to wrap each and every public function with an HTTP endpoint, and invoke it instead of the function. It’s kind of what rpc/gRPC is all about. I’m not saying it is a best practice, and there is statefulness to take care of, but it is technically possible.
Once done, it is no longer a Package coupled into someone else’s application. We’d now be holding two mutually exclusive applications, who share a relationship. As long as we maintain backward compatibility of the HTTP contract, which is somewhat similar to maintaining a method’s signature, all will be fine. But there is still something blocking us from updating it whenever we want and without permission.
We only turned our Package into an Agent. It would no longer be running in an application, but adjacent to it. It is still something of ours in a foreign territory, and we still require the territory owner’s permission to update. But we did create the potential for it to be moved to our territory. As they both now overcome the physical boundary of network between them with HTTP calls, there is nothing coupling them to be in the same server.
Breaking Ownership
Let’s assume these two applications are owned by two teams working for the same company. One is owned by us, the other is owned by Team A. As our application no longer must be adjacent to theirs, we can launch our own server and deploy our application to it. In our own territory so we can really update it whenever we want. We’ve removed the Delays caused by ownership of territories.
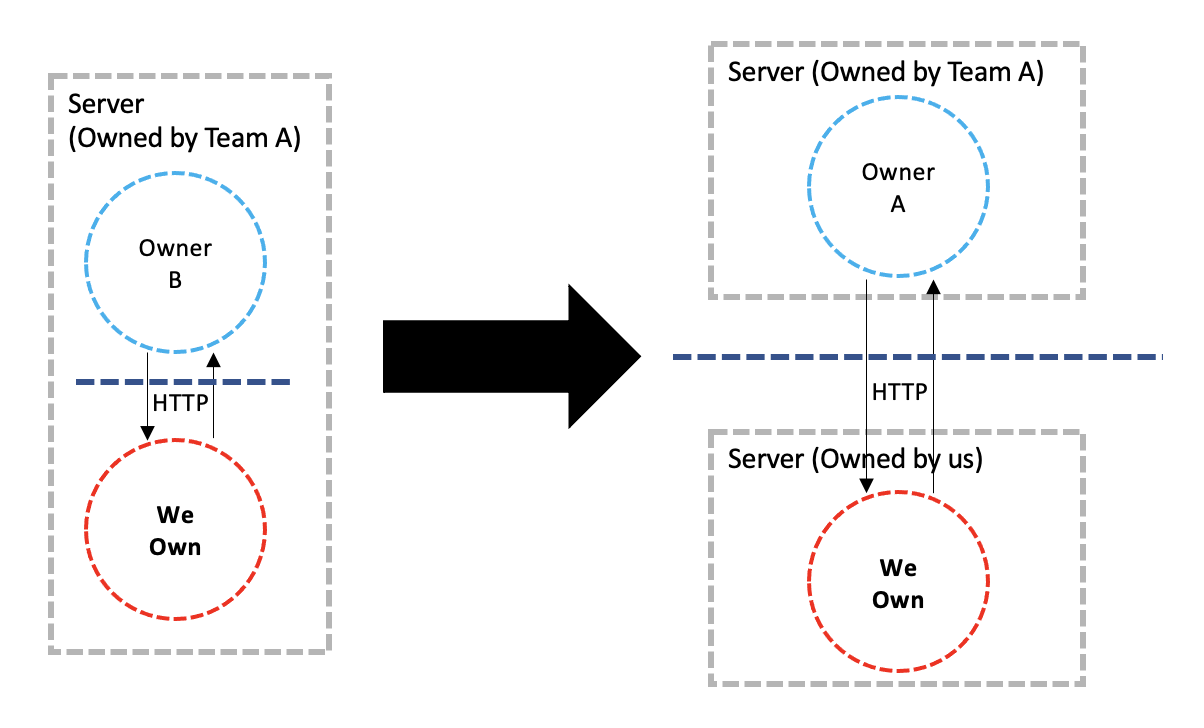
Funny thing is, server ownership is something of the past. Today we have Container ownership, that can be run on whichever server no matter who owns it. And if we have a cluster of these servers and an orchestrator and all teams own Containers – no application developer owns and maintains any servers. And that is the very definition of Serverless.
Let’s now presume something else, that we own an application and the server is owned by another company. Ever since the days of bare metal servers, nothing technically prevented one company from placing its server in another’s company data center. And it still holds to this very day, in the cloud. It is technically possible and constantly done: Company A can deploy its own EC2 instance within Company’s B cloud account.
That is exactly what AWS (and elastic.co and many others) are doing behind the scenes when you deploy one of their managed databases. The provider who owns this virtual server is continuously maintaining and updating it, although in another’s territory. Like an embassy. That is the Infrastructure-as-a-Service model (IaaS).
But there is something else we can do. We can deploy this EC2 instance in our own account, take care of lots of security issues, and deploy our application in our own servers. They will continue to communicate by HTTP, even between the virtual and physical boundaries of two companies. That is the Software-as-a-Service model (SaaS).
The ability to play with ownership and territories is what Microservices Architecture uniquely enables us to do. And there is another interesting outcome.
Reusability
A physical server ownership may no longer exist, but a virtual team/service ownership still does. Let’s presume that all of our backend applications require a layer of authentication. It can be distributed as a Package, a middleware for every web server.
To overcome Delays of ownership, we’ve decided to make and distribute it as an independent application. By doing so, we’ve overcome another obstacle. The need to code the Package in every language used by our applications (JavaScript, Python and Java), and to every kind of web server framework used (Express, Fastify, Nest.JS).
Just like any other Service, we will deploy our application as a single cluster of instances. As it is a layer/middleware, all incoming HTTP calls would pass through it. Calls for Service A would go to service A, calls to Service B would go to Service B.
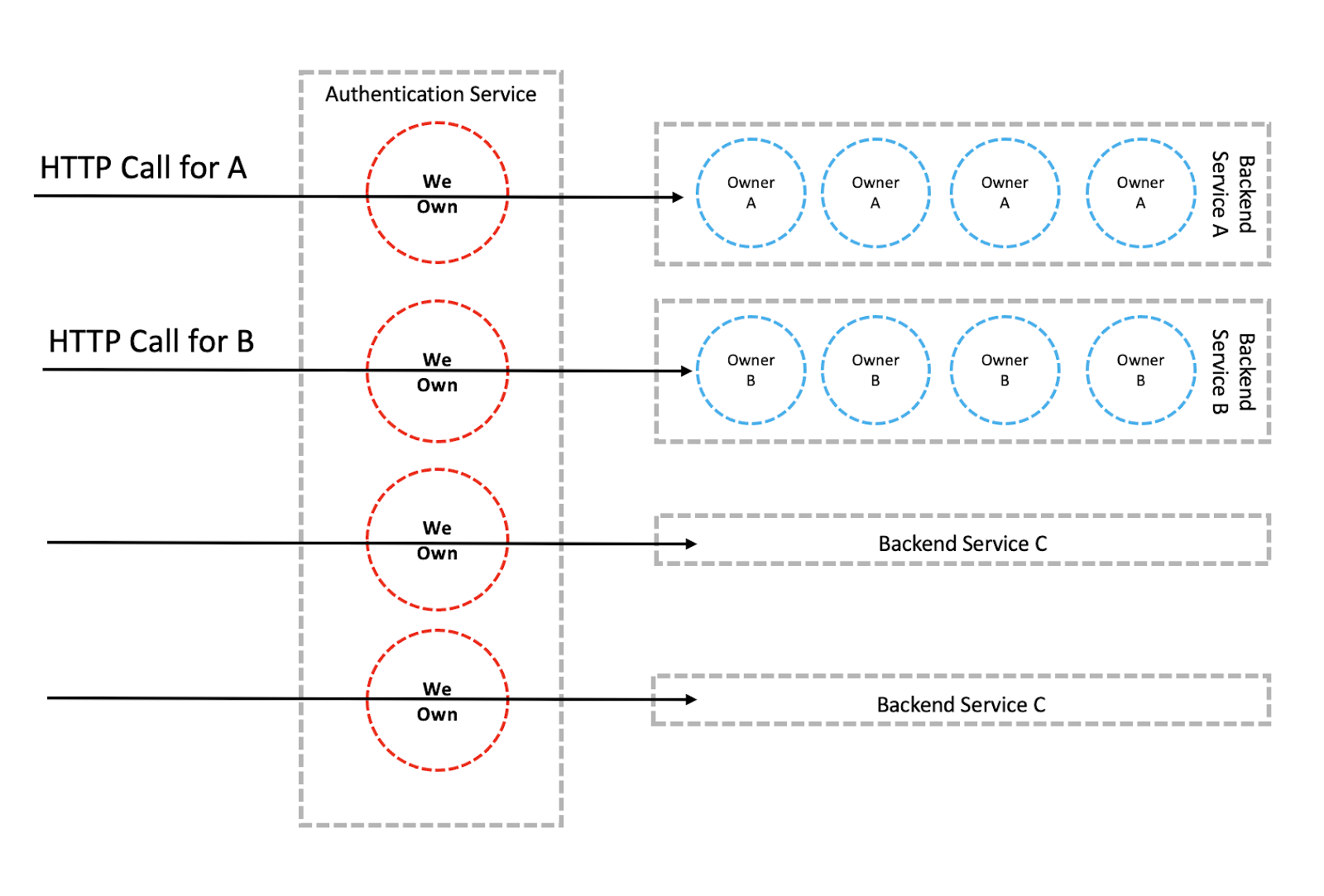
Unfortunately and unintentionally, we who own the Authentication Service had accidentally made a Change that turned out to be an Instability. A bug that causes a memory leak was deployed and all of our instances are cycling up and down. Until we resolve it, no calls whatsoever would pass through to any of our backend services. We brought down the entire company. A Single Point of Failure.
An entire shutdown can be avoided, because we are free to place our applications in foreign territories. Instead of a single cluster of instances, we deploy a cluster of instances within each Service. Which makes it into a reusable infrastructure component. If it is within another, our minds might think it should be physically smaller, like a box inside a box. Thus we named it a micro-service. But size doesn’t matter, cohesion matters.

Consequently, we allowed ourselves to do a gradual Rollout. We can first deploy to Service A wait and see that everything is okay. And only after a short Delay, we can continue to deploy to all the other backend services. In case of an Instability, we’ve only brought down one service and not the entire company. It would be even better to start at non-critical services. We’ve gained a higher Reliability, at a financial cost.
We’ve also gained a more fine tuned scalability. Each cluster of Authentication instances will scale in/out along with its backend Service. Because they both scale in/out according to the number/rate of incoming HTTP calls. On the contrary, a cluster scaling in/out according to the combined number of HTTP calls, might do so less efficiently.
A mixture of both could also be interesting. For each mission / business critical Service, we’ll deploy an independent cluster. For all the non-critical one, a single cluster for them all. Independency where it’s beneficial, codependency where it’s non-beneficial.
Not a Microservice
Our backend services are not expected to have any territorial issues, because they are specifically tailored to answer a business problem. For the same reason, there is no reason for them to be reused and each would be owned exactly by one team. If that’s the case, they may run on the same infrastructure, but they are just Services. They may share technical or business logic as a Package, which can become a reusable Microservices when it’s beneficial, but they themselves would not be a Microservice.
With these insights, let’s have another look at the non-beneficial split of the API Gateway of RapidAPI. It was not being reused and it was running only as a single cluster. As multiple teams continuously made Changes to it, it had no single owner. Maybe even no owner at all. It was simply not a microservice.
Let’s inspect it as a single application, through the principles we learned in the Change Driven Design series. It was Changing both for Technical and Non-Technical Causes. It contained Technical Modules such as Authentication and Authorization (A&A). It also contained Non-Technical Modules such as the Monetization’s business logic, which are also Behavioral Modules.
It was technically possible for the application to be used for its A&A Modules. But it wouldn’t have mattered. As long as it’s being Changed for Non-Technical Causes by the Monetization team, they would continue to unintentionally introduce Instabilities. Furthermore, multiple Changes by multiple teams would be bundled together into a single deployment, without the possibility to independently deploy and code them. We wouldn’t be able to Rollout only A&A and it alone.
In the suggested new design, A&A had been separated into its own application, acting as a layer. It would have been owned by one team, and would only have Technical Causes to Change, and an independent cut of those. It would have been completely decoupled from the company’s business logic, which are Non-Technical Causes. It would have had the potential to be a reusable infrastructure component, eventually.
In the next series, Future of Change, we’ll be reviewing an entire system and company built from scratch with all of the insights, perspectives and considerations we’ve seen and learned so far in this book.
Thank you for reading this series!