In every end of every distributed system, there exists a single application. Even if we tear apart a Monolith into a thousand smaller applications, each one would still be a single application. And each one would share relationships with others.
In the previous series of Change Driven Design, we’ve modeled single applications supposedly like others do not exist. But actually, we’ve modeled them to be agnostic to the existence of others. We’ve done it by having them better match an abstract force, which we’ve called the Change Stream, a series of Changes hitting our applications. The very same ones that fuels our application’s erosive evolutionary processes, those we covered in the series of Wasteful Application Evolution: towards a Monolith, a Bundle, a Legacy and a Refactor.
In this series, we will be learning how to model multiple applications and how they relate to the very same Change Stream. To do so, we’ll be learning about applicative splits. What to consider and what would be the outcomes of the actions of splitting one application into two. We’ll see how it affects costs, scaling, reliability, hiring and many other pure technical factors.
And there is going to be one unique perspective we’ll be focusing on, on how splits affect our development workflow. To do so, we’re going to start this series by learning about Bottlenecks, Throughput, Back Pressure and Upstream Pressure. Starting with something we are all familiar with – deployments.
Manual Labor
Sometimes I take things for granted. I’ve been working for merely 13 years which is enough time to forget where one comes from, forget how we used to work “back in the day”. Today is 2022 and Continuous Integration and Continuous Deployment pipelines are supposedly a given in many companies. It makes me think that some people never experienced manual deployment, thus maybe not know or forgot why we put so much effort into automation. Or maybe even sometimes excessive and non-beneficial effort, which we will learn of in this series.
In 2013 CI/CD was barely a concept. I was working for DealPly and we plainly called it automatic deployment. It was something we needed in order to handle deployments to hundreds of servers concurrently running our main application. And it has taken a huge effort out of all of us. It was born out of necessity. On the contrary, DealPly indexing platform automatic deployment was born out of Inefficiency and annoyance.
The indexing platform at first was deployed only to one server. I think most projects start like that. I remember having the entire deployment process written on a piece of paper, consisting of building/compiling the code, zipping it, scp-ing it to a server, ssh-ing to it and so on, and so on. If I’ve done everything correctly, the entire process could have taken me about 15 minutes. I had to be fully concentrated on it so I was unable to do anything else in the meantime. I don’t think I was deploying more than once or twice a week, but when there was a bug or if I got the process wrong, I might have had to do a few deployments one after the other. There were probably days I spent more than an hour on deployments alone.
Building and zipping was a one time operation which took about 10 minutes. The rest was another 5 minutes per server. As the project progressed and we had to index more and more sources, it needed to run on more and more servers. At its peak it was running on 20 servers, entailing a deployment duration of 110 minutes which was about 25% of my day. If something went wrong, a failed deployment or a sequence of redeployments due to a bug, that could have easily been an entire day spent.
Spending Waste
Was it time spent or time wasted is an extremely important question. We could argue that deployment is a part of the development workflow, because only code that reaches production counts and that is our definition of done. Supposedly, coding without deployment is meaningless.
On the contrary, the deployment prevents us from coding. We literally can’t because we have to keep our eyes on it to make sure everything went well. Or maybe it’s just our workstation being too slow and busy to do anything else with it. If we could have shortened the duration from 110 minutes to “just” 30 minutes, that would be an additional 80 minutes for us to code. If we could have made it run on a different computer and free our workstation to coding, that would have been an additional 110 minutes for us to code, the next task.
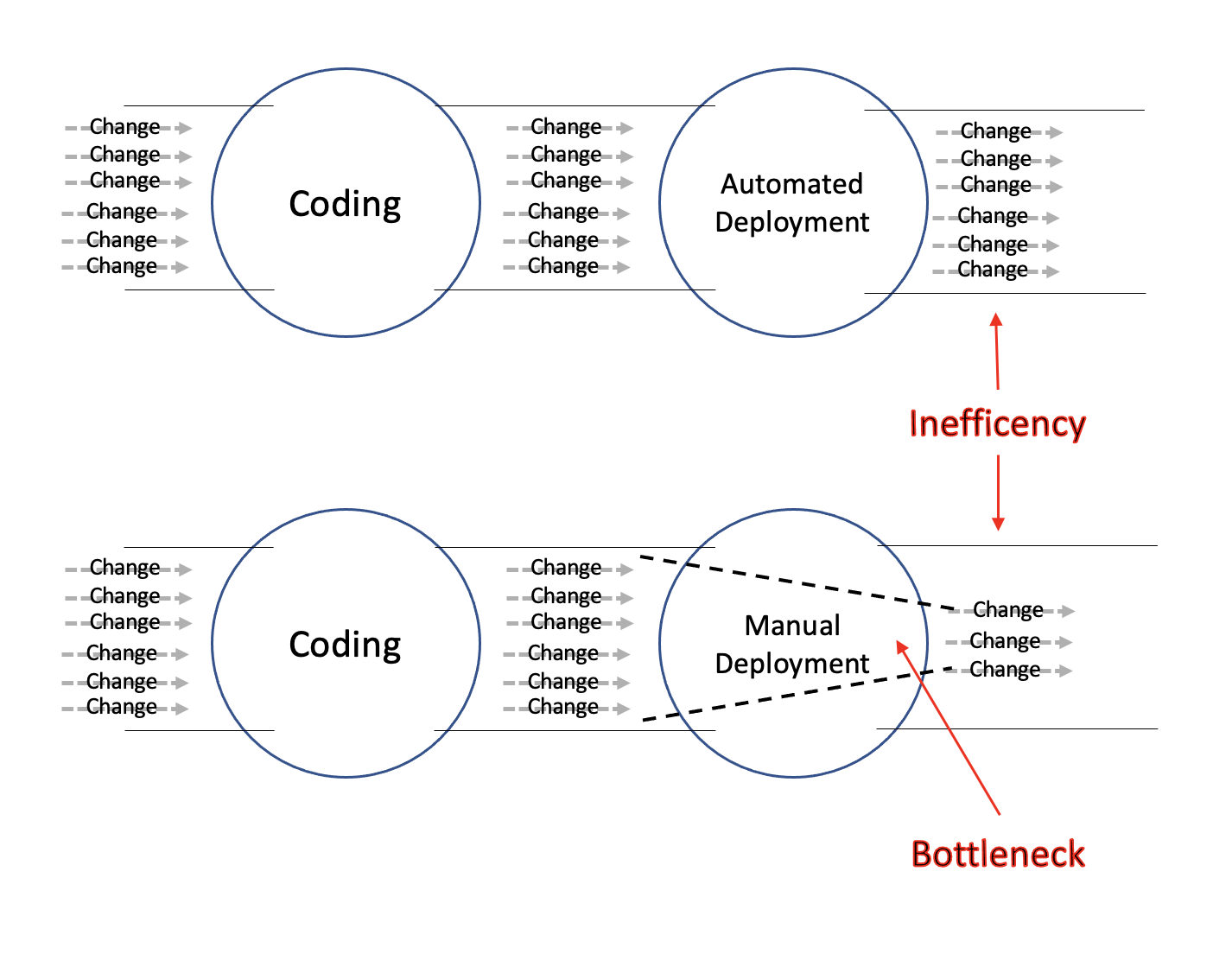
If the option exists to automate or optimize the deployment process, or any other part of the development workflow, and we choose not to do it or we are unaware of it – it is a Bottleneck. Bottlenecks are a source of Inefficiencies, because it is our time that could have otherwise been invested into moving the business forward.
At DealPly the option to do so was always technically available and always on the table, we just always chose not to automate the deployment. We were being inefficient. After more than a year of manual deployments, on my one month notice I spent about 5 days on automating it end-to-end. It wasn’t an easy task to do, but I really regret we haven’t done so sooner. We had wasted so much precious time.
The situation at Wiser (2016) was a little bit different. The entire build and deployment was automated, we had a Continuous Deployment pipeline running on Jenkins. We were free to code, but we always bounced back to the deployment because it was jittery. It failed a lot for unexpected reasons.
Although automated, it was still a Bottleneck. Indeed it was more reliable then a manual deployment, but the deployment process itself was jittery. We still had to keep our eyes on it while it was running. Although automated, it hadn’t removed any Inefficiency. Automation does not guarantee that.
Eagerness
Bottlenecks can have some various unexpected effects on our engineer’s minds, and as a result it would be affecting our application’s evolutionary processes.
When it is cognitively hard for our engineers to deploy, they may try to avoid it by asking themselves “is it worth it?”. Worthiness is not exactly measurable, consistent or similar between multiple engineers. Instead, we better think about eagerness. If our engineers have been working for a few days on an impactful Change, they’d be very eager to deploy it. No matter how long it takes, because of their eagerness our engineers would not conceive it as wasted time, even when a deployment takes hours.
But some Changes are non-impactful such as a 15 minutes effort on a bug. Our engineers might not be so eager to do the task anyhow, so due to their lack of eagerness they’d conceive the deployment’s duration as a waste. They’d go to their managers, who would agree that an additional hour for only 15 minutes of coding would be a waste of time. So they’ll deploy it later. Or they’ll just have a rule to deploy only once a week because it is too hard to deploy.
Deploying later results in deploying multiple Changes together. That would be speeding up the evolutionary process towards a Bundle. There would be more Inefficiencies and more Instabilities because it is harder to trace issues and revert when something goes wrong.
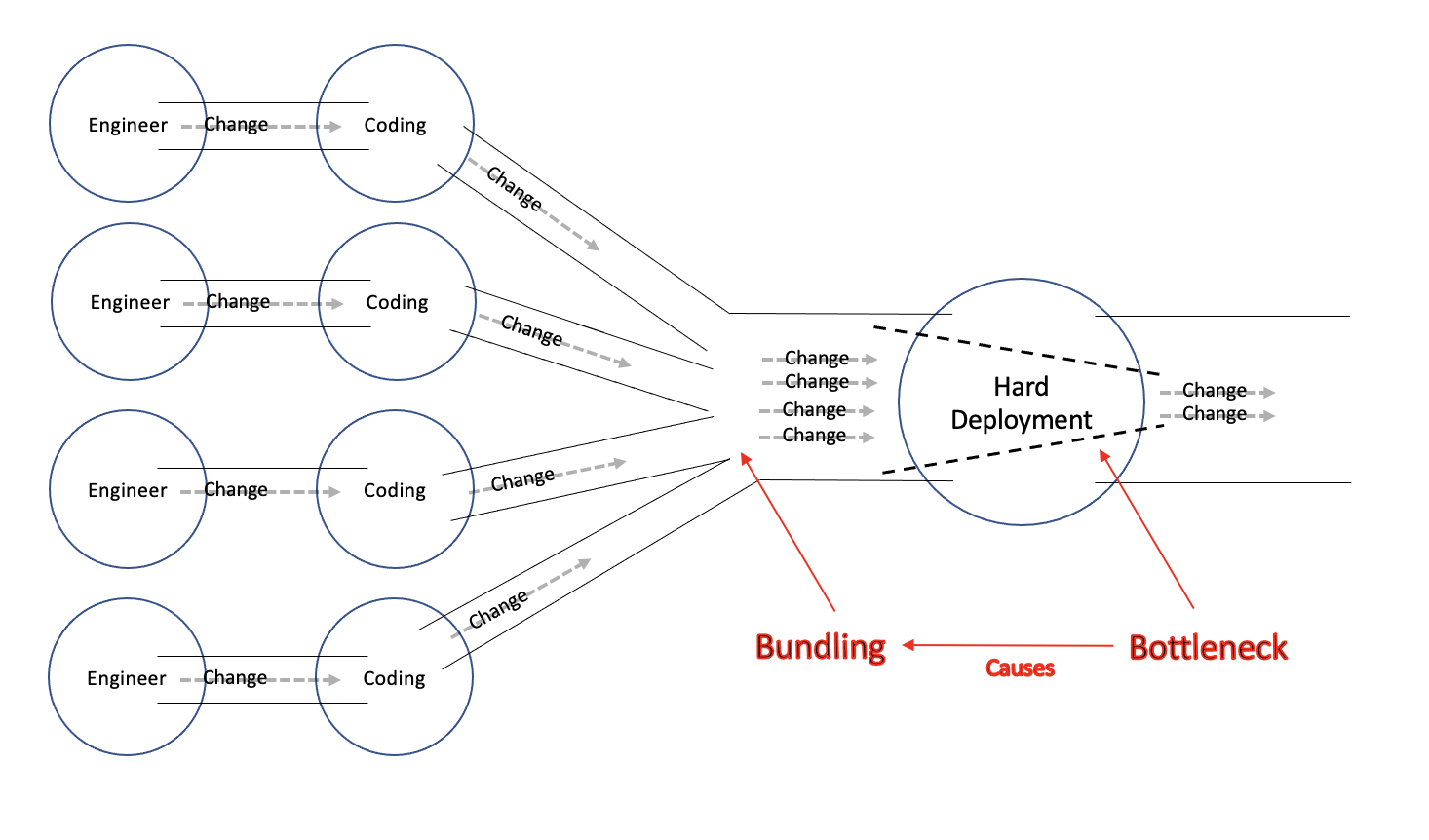
It could also speed up the evolutionary process towards a Monolith. In the previous series Change Driven Development, we’ve seen again and again how an eventually beneficial design allows an engineer to make a few smaller Changes instead of one big Change. Because our deployment is a Bottleneck, our small Changes would be merged right back into a single big Change. It would make our design become non-beneficial. There is a name to this effect, and we’ll see it better in the next chapter.
Spoiled Little Brats
At Silo (2017-2020), every project started with a CI/CD pipeline. Not necessarily because it was a Bottleneck but because you never send a human to do a machine’s job. It was to prevent Instabilities. I think the longest running one, after I made some effort to optimize it, had a duration of 7-12 minutes – and my people were always complaining. “OMG”, a prefix of my casual ranting, “when I was young it took hours and I did it manually! You are just being spoiled because you’ve never experienced anything else!”. Only two years later, I realized I was wrong and why.
At RapidAPI (2021) we had a ~12 minutes deployment and we’ve started practicing small Changes. And once again my people started to complain, but this time I knew why. One day I deployed 8 small Changes. I had no need to pay attention to any of their deployments, it was a highly reliable deployment. But I did need to make sure everything was okay once it was over. Because I knew my coding would be interrupted within a few minutes, I just didn’t start. Instead I went to get coffee or just talk to people.
We were annoyed by the continuous context switching sometimes caused by the short running deployments. If we do the math, on days like these I once again did nothing for a cumulative ~100 minutes, as I did not do any coding during deployments. Was I being Inefficient?
Coding, code review, building, unit tests, integration tests, end-to-end tests, deployment, monitoring. Each is an independent step, but all are connected into each other via our development workflow, a process.
A Bottleneck and its effects can be at each and everyone. In the next chapter, we’re going to see how a removal of a Bottleneck affects what’s in between those steps, our workflow Throughput.