There is a very interesting thread underlying and going through this entire book of The Change Factor, and it is in the story of the Monetization’s team Lambda over at RapidAPI. It was a three years old Serverless Function, worked perfectly without any issues whatsoever until one day it didn’t. Let’s reexamine this story through everything we’ve learned and tie some knots together.
In the series of Wasteful Applicative Evolution we’ve made an interesting distinction between Evolution to a Legacy and others. Out of the four evolutionary processes, it is fueled solely by Change beyond our engineers’ control and beyond our applications. The rest are fueled not only by external Changes, but with internal ones as well.
Even when none of our engineers have any Cause to Change no Change is being made, the dependencies we rely on continue to Change. We can only stop the Changes we Cause. We can not control the entirety of Change and it never stops. The world keeps spinning and so does the Force of Change.
But come on, we know this. One day out of nowhere, a Zero Day security breach was found in Log4J. Engineers throughout the entire world spent weeks rebuilding and redeploying their applications. It happened, and it was no fault of our engineers. There isn’t anyone in our team or company that could have done something to prevent it.
Same thing happened with RapidAPI’s Lambda. Throughout the years its underlying dependent Compute and OS had continued to move forward. And it would eventually happen again. But as this evolutionary process was happening externally and “in the background”, it hit RapidAPI only when an internal Cause to Change it had risen. The first Change to it in three years was a redeployment to a new AWS region, following a business-related Cause.
But prior to it, the application remained exactly the same for three years because there was no Cause for three years. In this chapter, we’re going to see what made it not Change for so long, is it beneficial, and ponder how we can design our applications to be frozen.
Just Worked
Before we ask ourselves how it has come to be, let’s ponder on the results of it being left untouched for three years – it has somewhat stopped evolving. Besides the Legacy evolutionary process running in the background, the rest have succeeded entirely. No engineers were making any Changes to it. The code stayed exactly the same. It was frozen in time. As Change fuels them, our application no longer continued to evolve neither to a Monolith, nor to a Bundle and nor to a Refactor.
It shouldn’t surprise us. An application’s evolution speed is determined by the Throughput of Change, and its acceleration rate by it meeting our application’s design. When there is zero Throughput, it evolves no further. Its evolution had been postponed for a very long time. The application just worked because there can not be an Instability without Change. Three years of peace and quiet for our engineers and our customers. A Reliable application.
Cause will eventually rise again. Once so, it would be easier to make a Change to an application that hasn’t accumulated tons of code for years and years. Consequently, as it would contain less business logic, it wouldn’t take months to write it entirely from scratch. It opens up the possibility to do so when it is more beneficial than a refactor.
Causing Responsibility
Let’s ask ourselves how it has come to be frozen for three years. To answer this, we need to recall what this application did and how it did it. It converts any HTML to a PDF. To do so, it fetches an HTML from a bucket in S3, runs an executable, and stores its output PDF into another bucket in S3 for long term storage.
There were maybe 10 to 50 PDFs to generate concurrently and in parallel. It is not much. The problem was of running these executables by the Monetization Service and on its underlying server. There would be tens of CPU intensive processes running adjacent to the Service’s process. They would constitute one noisy neighbor which could easily lead to process starvation and bring down the Service itself.
It was avoided by a job done well, by isolating it with Containers with micro-containers known as Functions. These were the intentions and considerations behind the decision to split it into a mutually exclusive application.
On the contrary, the result of three years without Change were unintentional and not coincidental. If we were to inspect it through SOLID principles, we would indeed see it had a single purpose/role. It had followed the single-responsibility principle (SRP), “every class should have only one responsibility”. But the Monetization Service also had one responsibility, over the entire domain. How come one had Throughput and the other had zero Throughput?
Every split to an application is a split to our workflow Throughput. A portion of it would continue to hit the Monetization Service, and a portion of it would hit the HTML to PDF Lambda. It is the outcome of each and every split, whether we design and intend for it or not. So for some reason, the outcome of the split was a portion of zero. Let’s inspect the potential Causes for Change, and recall that one entity’s Change is another’s Cause.
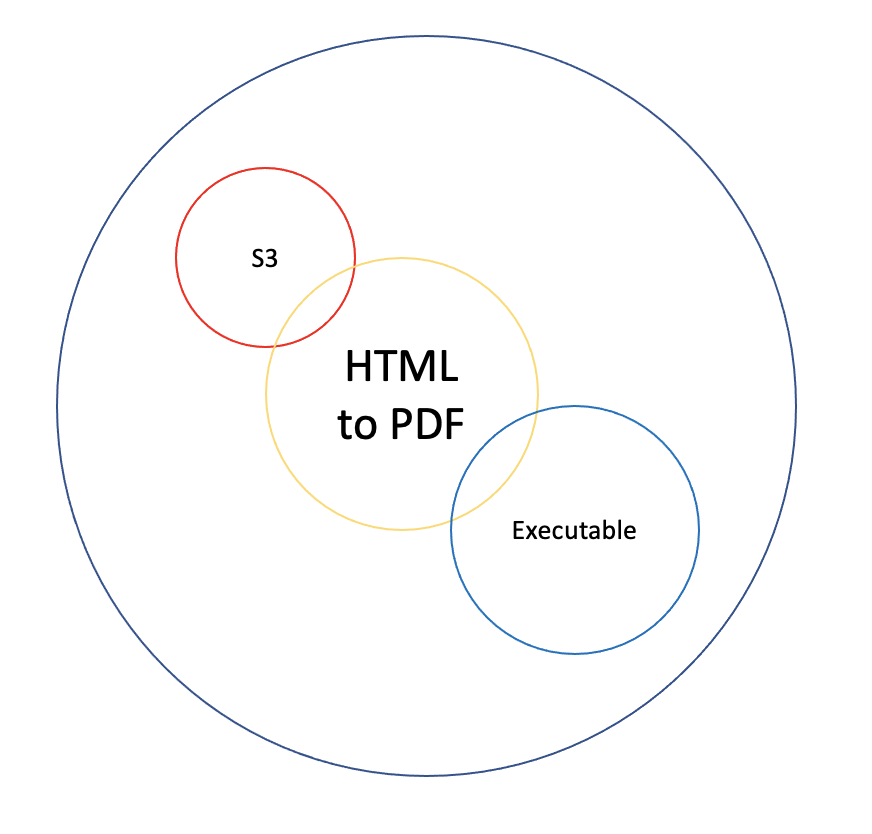
A Change to the application would be needed when:
- We’d be Changing S3, replacing it with another Object Storage
- The bucket / URL path in S3 would Change
- The executable would Change (which is what Changed due to the Legacy process)
- The HTML standard would Change
- The PDF standard would Change
If we look carefully we should notice that all of the above are highly unlikely to Change. More so, each one has its own independent Cause to Change. There is no reason for a Change to the HTML standard to entail a direct Change to S3. Even if miraculously would, it would definitely not happen at the same time.
We should also be aware that this application is only a part of a User Journey/Flow. The Monetization product issues a charge, followed up by sending an invoice as a PDF to the customers. The customer experience was indeed ever Changing, being upgraded and expanded through the years. And yet, the Lambda remained frozen without Change.
It was no wonder, because all that Causes the Lambda to Change were purely Technical Causes and there were no Non-Technical Causes. And all that Causes Charge Flow to Change were only Behavioral Causes, and the Lambda had only Non-Behavioral Causes to Change. The Lambda and the Service had mutually exclusive Causes to Change, thus had no reason to Change together. Allowing one of them to be frozen.
It was not coincidental the Lambda has been frozen for years. It is even an expected outcome, although unintentional. Can we make it into an intentional outcome, and will it be a beneficial one?
Cause for Design
Martin C. Fowler (Uncle Bob) first defined Responsibility as “each software module should have one and only one reason to change”. Only later he redefined it to be “gather together the things that change for the same reasons. Separate those things that change for different reasons”, and named it Separation of Concerns. For myself through the years, it was still an ambiguous term.
In the series of Change Driven Design we went through a journey to reach the very similar conclusions as Uncle Bob. We practiced Separation of Causes, finding mutual exclusivities in Causes. We said it could be done prior to coding because Causes are prior to Change, and Causes exist long before our application does. We also learned how to model our applications with Directions of Change, and verifying what shouldn’t Change together. Unfortunately, no matter how we ended up grouping our Modules, as long as they reside within a single application, all will always be bundled together into a single application. Affected by the same Throughput.
In the series of Breaking Change we removed that limitation, and we’ve seen how the many principles of Change Driven Design holds true and extended to multiple split applications. And it remains valid for an entire system architecture and its corresponding development workflow. In a way, it shouldn’t come as a surprise that it extends as such. Because both organizations and systems should be as aligned as they can be with the Change Stream, an abstract 3rd party Force of Change that also encompasses our development workflow.
Through modeling the development workflow, its Inefficiencies and its Bottlenecks, we’ve seen the two-way relationship between applicative splits and Throughputs. But it can not be guaranteed to last forever. It’s only a question for how long it would be frozen and when.
Succession of Change
Let’s go back to our very basic thoughts. Instabilities will not occur as long as there is no Change, and we can only control the Change we ourselves make. But as Cause will eventually rise again, it is more correct to say Instabilities will not occur for as long as our application remains frozen. To see the difference, let’s compare the two graphs below:
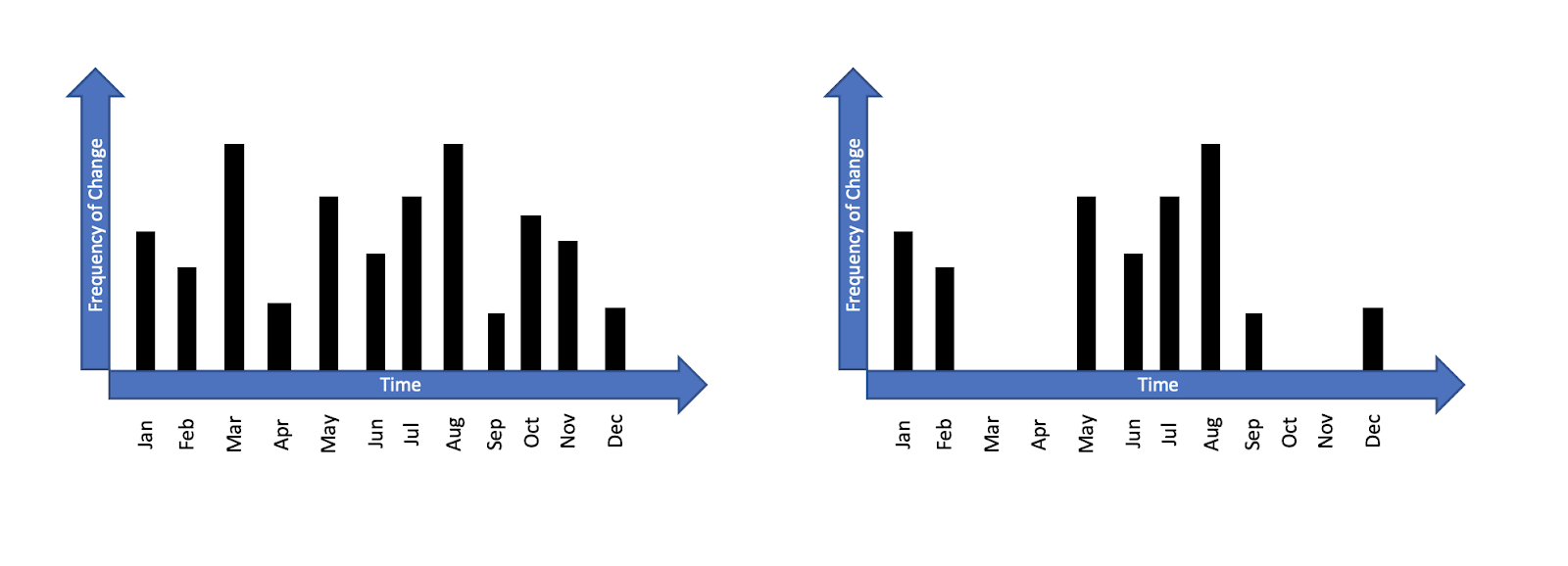
On the left, an application that had been Changed at least once every month. On the right, an application that for some reason, for a while it was frozen. During the months of April, March, October and November not one engineer had worked on it. During that time, our application was more Reliable because there were less Instabilities! We accomplished it only by doing nothing.
We can not guarantee an application would be forever frozen, as Legacy evolutionary processes are beyond our control. An eventually beneficial effort would be to design our application towards maximizing the time it is frozen. And as Causes exist before our application does, it is possible to design so in advance.
When our engineers do not work on a frozen application, they quite simply work on another one. Something we indeed can guarantee. We’ve learned how to design multiple applications to be mutually exclusive and have no Cause to Change both at once. We’ve also learned how to avoid the penalty of fragmentation. It would result in Throughput splitting between them, a technical prerequisite for an application to be frozen for a while. But maybe not for long enough to say it was beneficial.
Sense of Limitation
For an application to remain frozen for a while or even a long while, we need to look not only at the beginning and middle of its life cycle, but also anticipate the end of it. Which might sound contradictory because Change has no end, but each set of Causes is limited by something. Either by what they should do, by what they can do, or by our imagination.
Silo had a physical device in plan, one with an update mechanism. There was a limit to what that mechanism should do. Once coded and it fulfills its sole mission to update, it will be a long while until it would have any Cause to Change. As a result, the updater was split into a repository of its own, and was an executable and process running independently. To close the circle, it was also deployed manually and independently from the device’s main application. While the main applications Changes, the updater would still remain frozen.
On the contrary, the main application was more frequently Changing because Silo’s update experience was less limited than the updater itself. The product Flow, the experience was limited on its own about what it should do. Each experience is independently limited by our own imagination. Once an experience is complete, it would be a while until someone would come up with a revolutionized new way to experience it. It would be a long while until it would have a Cause for a Change.
Until that happens, the Module within the single application would remain frozen and it would ease future troubleshooting and tracing. And at some point in time, all experiences would be complete and frozen. When all of the Modules would become frozen, the application would become frozen. Because all Products are a composition of Products and Flows.
That is until one day the CEO wakes up in the morning and decides to Change the entire color scheme due to a rebranding Cause. It might happen eventually, but for as long as it doesn’t happen, everything would remain frozen. But when it does, the new color scheme would still be limited by the device’s physical coloring. We would not be able to send an engineer to each customer’s house and repaint the device. So no matter whether our imagination is unlimited, all experiences are all limited by what they can do. Because the physical device has only 4 buttons, an LCD screen and some sensors.
For some hardware is just a metaphor, so let’s take a look at Silo’s mobile application. Once again, all experiences are limited by both the mobile’s OS and the mobile’s hardware. Both are external dependencies.
The application’s main experience/tab of Food Management is limited by what it should do. And it just has nothing to do with the tabs of Shopping and Settings, and what each should do. Each tab would be a closed set of experiences, each with its own needs to fulfill. There might be endless imaginary ways to sell containers, but there just aren’t as many ways to manage your settings.
These experiences in a mobile application can be unbundled and split to multiple applications. Either by web views, or code splitting in the case of React Native and module federation. And we already know that micro-frontends entail Throughput splits. So once the Causes succeed for a single application to Change, the application would become frozen. Once it fulfills our customer’s needs, it would become frozen for a very long time.
Reliable Rollouts
Lastly, let’s not forget that every Change is followed up by a deployment. So for as long as a Change is not being deployed to a destination, an application remains frozen in its destination. Let’s also recall that every deployment is a gradual Rollout, a time Delay exists between our engineer making a Change until it reaches all of our end customers. If we use this to our advantage, we can make sure an application remains frozen for even longer.
For Silo’s physical and mobile applications, we intentionally planned a gradual Rollout. We planned to continuously deploy only to 1% first, keeping the rest of the 99% frozen for a while longer. While the 1% might experience Instabilities, the other 99% would not. Only once used by the 1% for enough time, say 2-4 weeks, the rollout will continue to the rest of our customers.
We’ve seen a similar concept when we spoke of what microservices really are. When they are used as a reusable infrastructure component by many Services, we can deploy a new version of our applications to one Service at a time. If the new one would unintentionally contain an Instability, at least its blast radius would be significantly reduced. Only one Service would go down for a little time instead of the entire system for a longer time. The other instances and Services remained frozen for longer, as they were not deployed to. They maintained their existing reliable state.
These concepts of frozen and independent Throughputs exist also in the heart of AWS Well-Architected framework. And it was also one of the core principles guiding the making of Silo’s system architecture. Part of the not so secret sauce to how to have a smart kitchen appliance, one more complicated than an Echo Dot, and for it to be as reliable as a microwave. A system architecture will start to deep dive into in the next chapter.