Functions do not have a shutdown hook, can shutdown unpredictably and can easily scale fast to thousands of instances. This will require you to consider the aspect of persistent connections while considering to work with Functions. It could also affect your application’s external dependencies / database of choice.
As always, let’s start with an example. Let’s presume that you’re using MySQL, whose default max number of connections is 151, but you’ve set it to 1,000 [more on actual max connections later]. Let’s also presume that your application’s expected incoming throughput would be also 1,000 concurrent requests, each one does a single request to MySQL at a time.
A Containerized application would have a Connection Pool Manager that will handle and reuse all the open connections to MySQL. Connections that remain open between operations are persistent (a.k.a. stateful connections/protocols), and there’s nothing wrong with that. To do a connection handshake on each incoming request is directly translated into a few hundreds of milliseconds of latency to the fulfil that request. Instantiating each connection only once and to reuse it for multiple requests is a good practice.
Dangling Connections
If properly coded, your application’s Connection Pool Manager would hang/attach to the shutdown hook/SIGTERM signal and close all of the open connections upon termination. On MySQL’s end, when a client does not properly close the underlying socket, it would leave all the TCP connections in a CLOSE_WAIT state. Your sockets are leaking.
Citing the Red Hat docs, CLOSE_WAIT indicates that the server has received the first FIN signal from the client and the connection is in the process of being closed. This means the socket is waiting for the application to execute close(). A socket can be in CLOSE_WAIT state indefinitely until the application closes it. Faulty scenarios would be like a file descriptor leak: server not executing close() on sockets leading to pile up of CLOSE_WAIT sockets.
MySQL’s server is waiting for your application to call close(), but your application is long dead. These may be recycled and closed by MySQL by a timeout set in advance or a script running once in a while. But until they are recycled there would be less or no connections available to MySQL.
Functions do not close persistent connections upon termination. With Containers, on the rare occasion in which the Container Orchestrator decides to terminate a Container instance, it would send a SIGTERM signal to your application. On the contrary, when a function instance is terminated it does not send a SIGTERM signal and it happens periodically and unexpectedly.
Container instances will continue to reuse the 1,000 available connections. Functions however, to withstand 1k concurrent requests, would require 1k function instances. After about 10 minutes these instances start to shut down, thus 1k dangling connections would be left behind on MySQL’s end. That would leave zero connections available for the newly created function instances.
This is not an issue specifically with MySQL, it is a problem with persistent connections that are also used with MS SQL Server, any JDBC driver, Redis, Neo4J and many more.
You should also be familiar with the C10k problem. In short, hell can break loose when reaching 10k concurrent open sockets. This is also a factor of the number of open file descriptors and it consists also of how many physical files are currently open and how many threads are running by all the applications on the server. [see more on this problem with scaling WebSockets in a future article]
Solutions
Don’t rush to decide that using/coding non-persistent connections is the right solution for you. If not already supported by your database (or any other 3rd party/external application), it would be hard to do. There are simpler solutions to consider.
Don’t do anything
The scenario described above was just an example, nobody says that your use case is the same. Maybe for you the quickest and simplest solution would be to change nothing to your application, to have some dangling connections. Check your throughput and check if your database can handle that. If your expected throughput is only around 20 concurrent requests per second, then playing around with the max connections available (which could cost you more server resources) or recycling the connections every 1 to 5 minutes, this just might do the trick in the minimal amount of time.
Recycle connection per request
A well known Function coding practice is to open a persistent connection on each incoming request and closing this connection after processing is completed. While a function instance is idle, it would not retain any open connections. The tradeoff would be latency, as the time for a required connection handshake would be added to each request. Consider if this added latency would be an issue to your customers at all [See Safer but Slower: Latency previously in this series].
Go with Containers
At Silo (2019) we had a user flow that required minimum latency. [See Safer but Slower: Latency previously in this series]. For technical reasons previously explained Redis was a must, which could neither be configured for more connections nor could they be recycled. Although it’s expected concurrent throughput was very low, a handshake was a few hundreds of milliseconds, each!
We decided to drop Functions and go with Containers as the other solutions described below were far too time consuming as well.
Stateless protocols
There are many aspects to choosing a database [will be discussed in a future series], but if you’re starting an entire new application/service from scratch, have a look and see if the database has an http interface (the de-facto industry standard), or another interface that allows non-persistent connections with a stateless protocol.
For example, AWS’s DynamoDB default interface is the stateless HTTP, which all the SDKs are consuming. ElasticSearch also has a native HTTP API. Surprisingly, Neo4J V4.0 added a transactional HTTP API. AWS’s Neptune also supports HTTPS both for Sparql and for Gremlin. Google’s Firebase as well. MongoDB/Atlas as well. CouchDB as well.
It is not uncommon but as the need for non-persistent connections is rather new, many older traditional databases do not expose a non-persistent interface. Not MySQL, not MS SQL Server, not Oracle SQL. Redis does not. Cassandra, for example, has an enterprise distribution that supports it, but not open source one. AWS’s RedShift does not, nor does their managed Cassandra service.
There is no rule of thumb which database has one and which doesn’t. You would have to dig into the documentations to find one, and hope there’s already a stable client/SDK that implements it in your application’s language.
My guess is that historically speaking, “old” application servers used to create a thread per connection in order to handle multiple connections. That was because each thread was blocked on I/O. As the latency of creating a new thread along with the connection handshake is high, the use of persistent connections was indeed the best practice, back then. Once async I/O started to be widely adopted, a single thread would not be blocked on I/O and could handle multiple incoming requests through multiple sockets. I guess that naturally led to dropping persistent connections as the best practice towards stateless ones as all the newer databases that have an HTTP interface are using async I/O underneath.
Solutions
Divide and Conquer
At Silo (2019) we had a need to manage data and relationships between several entities (mobile users, devices and their respected households). As we did not know how these entities would be queried in the future, we thought that a relational database (MySQL/Aurora) would be a right fit. But we had a specific flow, the login flow, that we knew would be triggered rarely, maybe a few times in a product’s life time of three years, but also that bursts can happen and it must be highly available as without it login/device provisioning would fail and our customers would be furious. From any aspect, besides persistent connections, it called for a Function, not a Container.
In order to overcome the persistent connection issue, we extracted this entire flow into its own independent service, the Login Service. As the service is now well defined and solid, not expected to change in time, now it only requires a simple mapping between 3 entity IDs which was easy to implement DynamoDB. Thus we managed to have a stateless database for a stateless Function.
There are plenty of other aspects to correctly choosing a database, not only support for stateless connections and quite frankly, it may end up being one of the least important ones in choosing one. But from a Function’s perspective, it may be a very important one.
Proxy Layer
A known solution would be to extract the Connection Pool Manager (CPM) into its own application and run it in an Container, which would act as a reverse proxy:
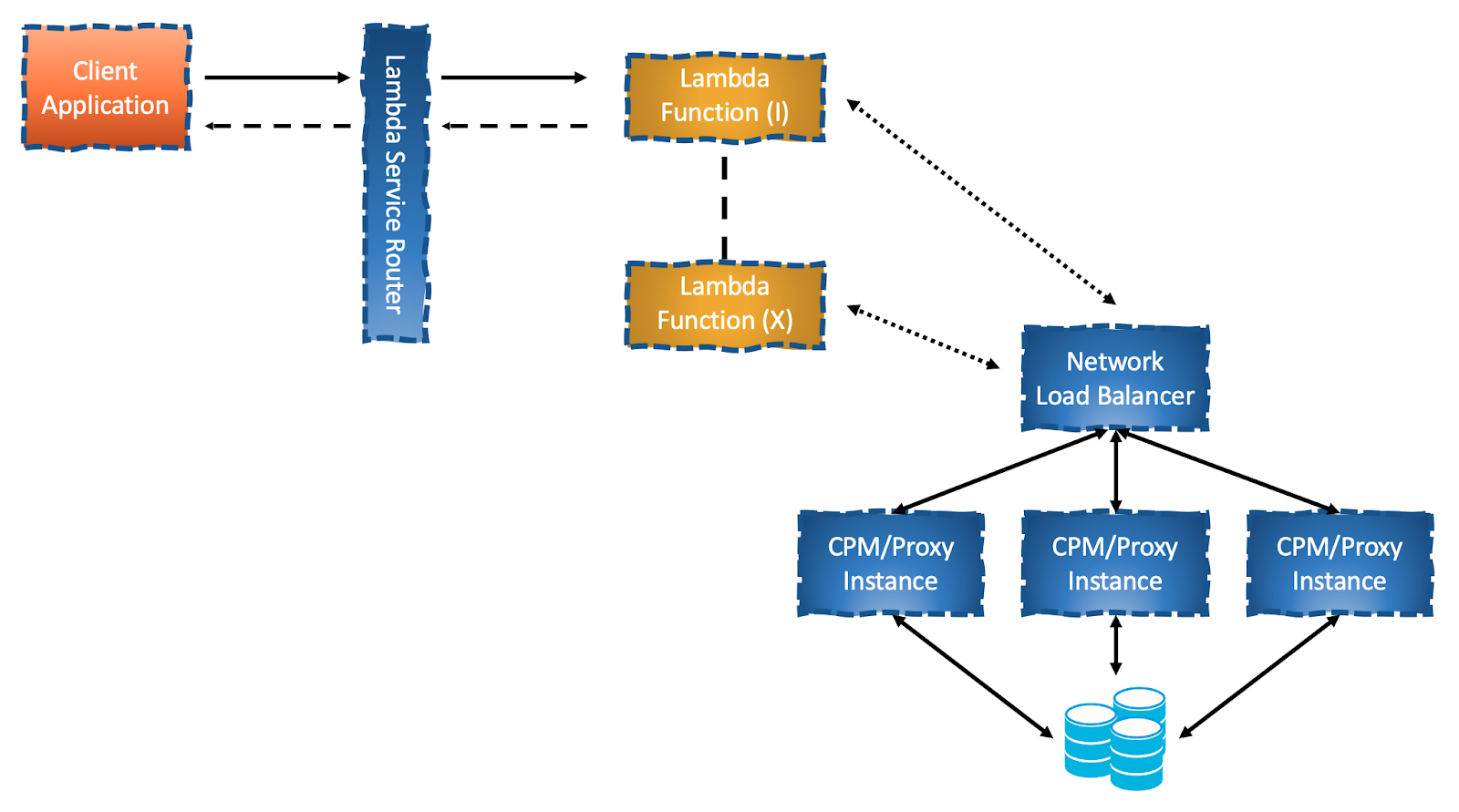
The CPM instances would maintain all the persistent connections to the database and would pass through incoming traffic to the database. Each Lambda function would open a connection, one that would appear to it to be persistent. This connection would be terminated by the CPM after a transaction was completed thus not creating any dangling connections neither with the database nor with the Lambda function.
This solution is based on the L4 transport layer. There would be no change to the client or contract/protocol. It’s a completely transparent change [As I’ve yet to implement such design, consider this to be rather theoretical]. AWS has implemented something similar for their own RDS managed databases, called RDS Proxy. Microsoft did something similar with Azure SQL with OData.
If you are thinking about coding one of your own, first search for existing ones tailored for your database (e.g. Redis has one that can also be used as a CPM) although they are rare to find.
You could also try and configure or extend known reverse proxies such as nginx or envoy, but they require some expertise.
Any way you go with, either coding one or utilizing an existing solution, you would have to deploy it in a highly available manner, maintain it and extend it. This is a lot of burden added, probably an unnecessary one. Are you sure your “simple” application requires such a complex solution? Although that’s a correct solution when it comes to separation of control and reusability, it is still only propagating the problem from one application that runs on Lambda to another one that runs on a Container. If it’s a one time solution to a single application, I may not do it.
HTTP REST Layer
This solution is very similar to the previous, only on top of the L7 application layer and not the L4 transport layer. It has several added values and one major downside [Once again as I’ve yet to implement such design, consider this to be rather theoretical].
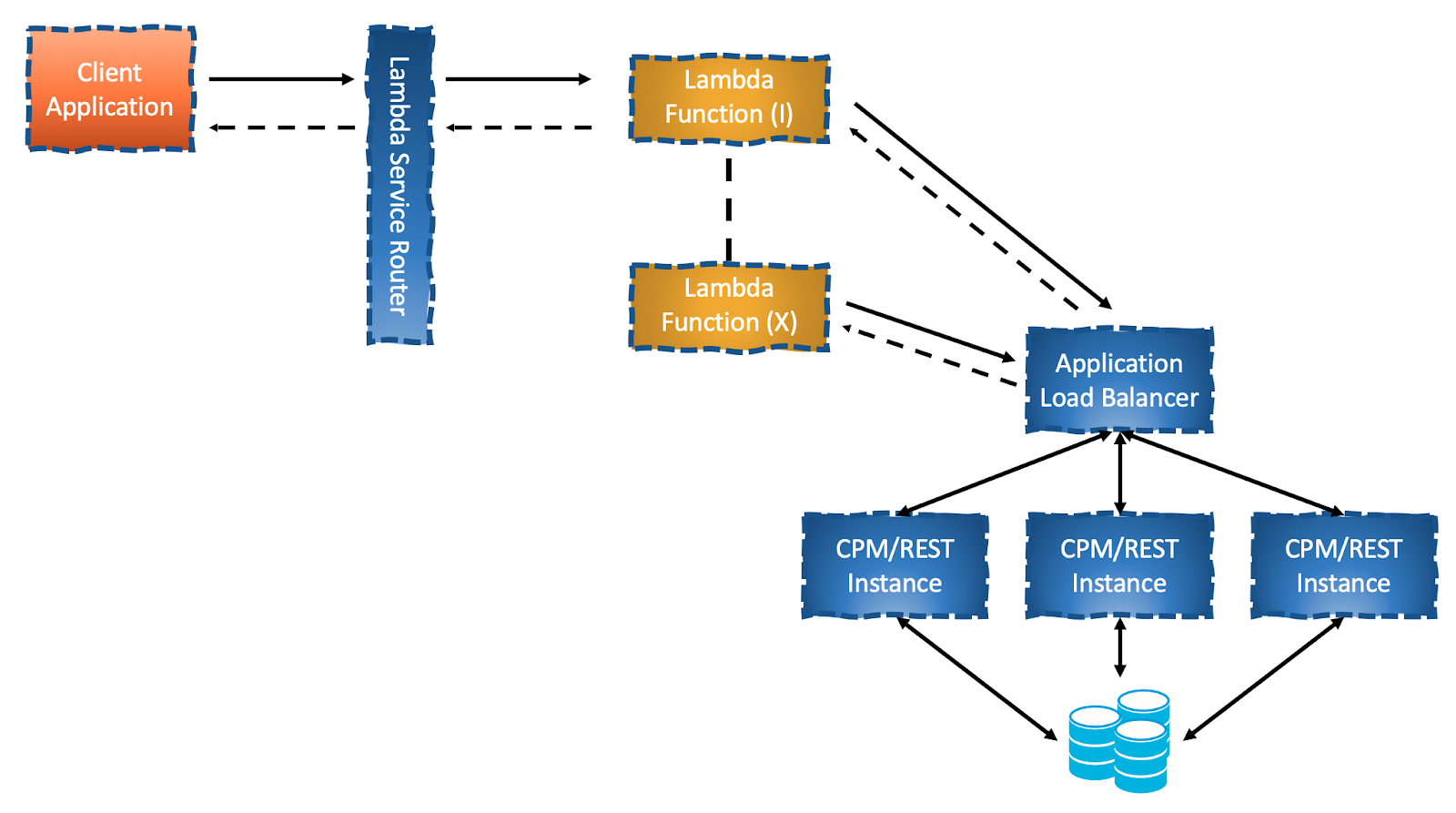
I’ve mentioned the Login Service before, which during its design phase we needed to store data and relationships between 3 entities. We thought of a relational database, a SQL one. Back then Aurora Serverless, AWS’s fully managed on-demand/pay-as-you-go SQL database (world’s first!) did not support a stateless protocol. A few months later, they came out with the Data API, an HTTP REST Layer for Aurora Serverless, which can be used to run SQL queries against your SQL cluster without managing persistent connections at all.
The benefits of a L7 application solution includes well known applicative capabilities, such as authentication and content based rules and most importantly a standard HTTP stateless protocol. The downside of a REST Layter is that it would require a change to the client, an entirely new one, as the contract and protocol has completely changed. Your application and the framework you’re working with may not be able to support this.
Luckily At Silo, knex.js the SQL Framework we were already working with was extensible enough so that a Data API Client for it was ready for us to use thanks to the open source community. It had some quirks and we helped with fixing some bugs in it, but all in all it was a seamless transition for our application to move from persistent connections to using Aurora’s HTTP REST Layer.
Coding an HTTP REST Layer for an entire database and changing all the client code is extremely hard and complicated. Just like the Proxy Layer it’s an entire new layer to manage, deploy and maintain with its own product life cycle. This is a kind of solution to consider if you’re working on something really big for an IaaS company, not for a one time small/medium project.
On the other hand, if an already existing coded HTTP Layer exists, it may be better to use it then a non-existent/hard to configure Proxy Layer. For example, the open source MongoDB has several HTTP Layer implementations. If it is battle tested it could be a good way to go. Although you’d need to deploy and run it in a resilient manner, it might be worth it.
HTTP Service Layer (The middle way)
Wrapping an entire database’s functionality is a very complicated solution, while your application might have a very specific need.
I previously mentioned before Silo’s (2019) need for a locking mechanism to bridge synchronous invocations and asynchronous executions. We’ve decided to use Redis as it is blazingly fast (in memory storage) and features a blocked pop/push specifically for this.
Its clients, our server applications, did not need to use all of Redis’s commands but only two of them (blpop and blpush) and only for a single use – lock on & release. Instead of a full REST API for Redis, we coded a Locking Microservice with an HTTP API that exposed only two endpoints. It acted both as a mediator and as a Connection Pool Manager. Two birds, one stone. Easy development. Simpler needs require simpler solutions.