Session is volatile
Many web servers / frameworks are using sessions to allow execution of consecutive dependent requests by temporarily saving attributes/context in memory. Application that stores data in memory or in any volatile/non-persistent storage is stateful. When a state is gone, it affects your end customer as his request can no longer be fulfilled.
With Lambda you can not guarantee that two requests would reach the same function instance. As there is no routing based on sticky sessions, each request is being completely re-routed to another function instance. As such it is not possible to have Sessions.
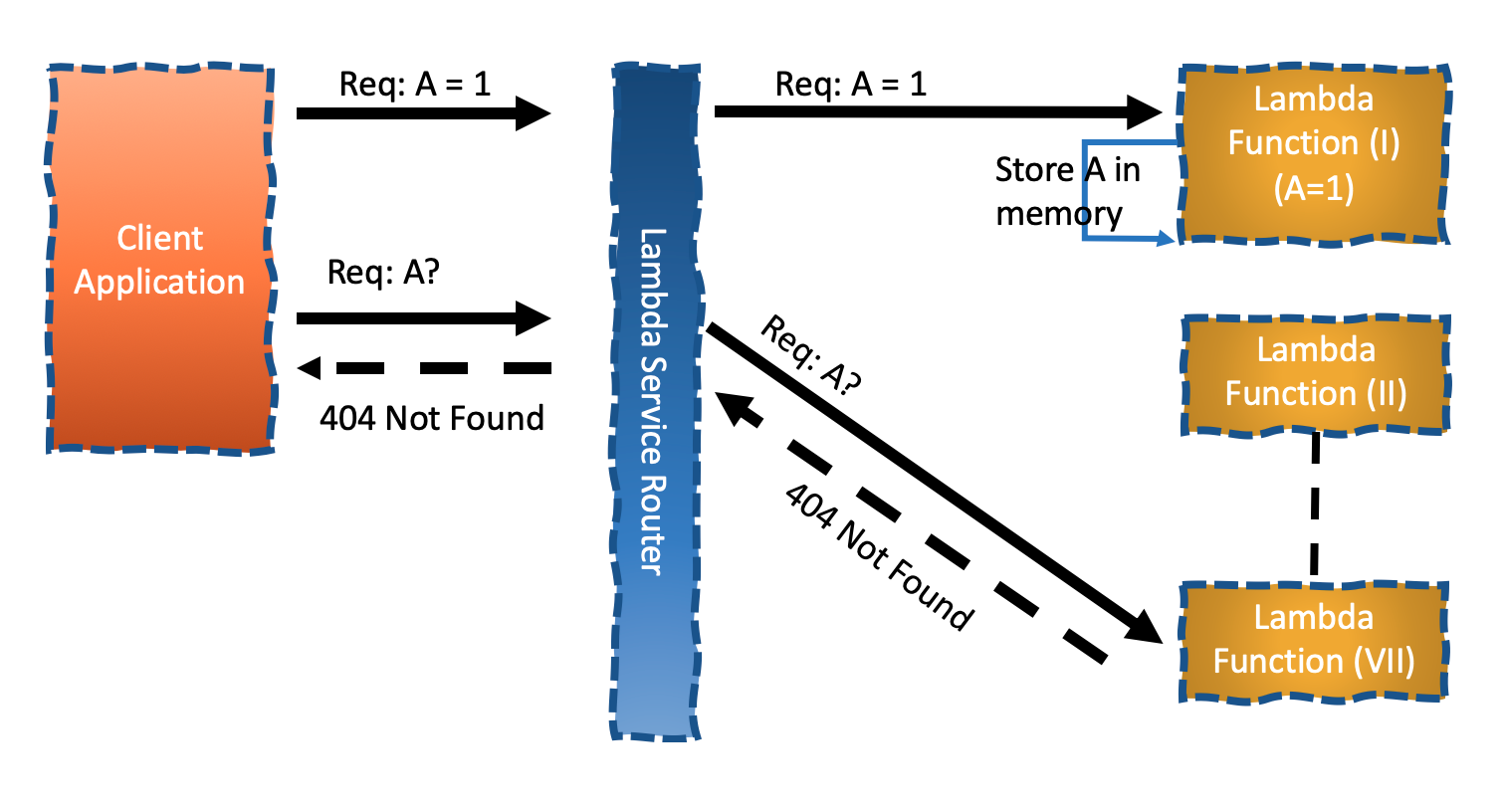
You also can not control the function instance’s shutdown timing. Think of a long governmental form to fill out, which may take a few good minutes to fill out. By the time he’s done, the function instance might be long gone, and the temporary memory storage with it.
Functions can not retain any state, thus applications running within must be stateless.
Containers can be stateful, but should not. Unlike Functions, you do have control over the load balancer and over routing so you can do session based routing. You also have control over the Orchestrator and control of the container life cycle, and it would not shut down unpredictably.
But a Container instance may be intentionally shut down either due to scaling down or due to an update deployment. Lastly, Containers can crash unexpectedly, may suddenly run out of memory just like any other application [see Design for Resilience: Isolation and Availability with Containers]. In both cases an in memory session would be gone. This is also true to storing a session locally on a persistent storage, but for different reasons that will be discussed later in this series.
Solutions
Stateless applications are more reliable and resilient than stateful ones. But depending on the use case it may be marginally. As a good practice, go stateless by default and try to prove that it’s not possible or worthy, especially if it’s a new project / application. If you’re considering refactoring an application to a stateless one in order to make it run as a Function, it may not be worth the effort [see Not all that Glitters is Gold: Limitations & Refactoring later in this series]. Containers will probably be the wiser choice.
There are two strategies that I’m familiar with to code in a stateless fashion that may also be used as a refactoring strategy.
Context chaining
The first would be to pass the entire session/state/context between chained requests through their mutual replies:
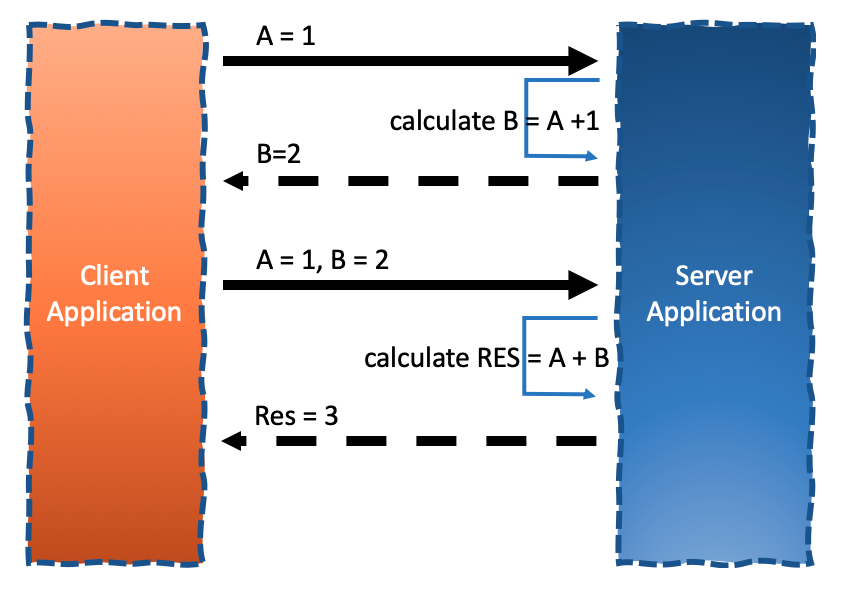
The downsides of this strategy are:
- Client dependency
- It is a change to the contract between the client and server and no longer an internal server change
- It may complicate client development
- It may propagate the session issue to the client thus not solving the stateful issue at all
- Not all information may be exposed to the client
Session storage
The second strategy is to store the session in an external stateful entity, a database or another already stateful service:
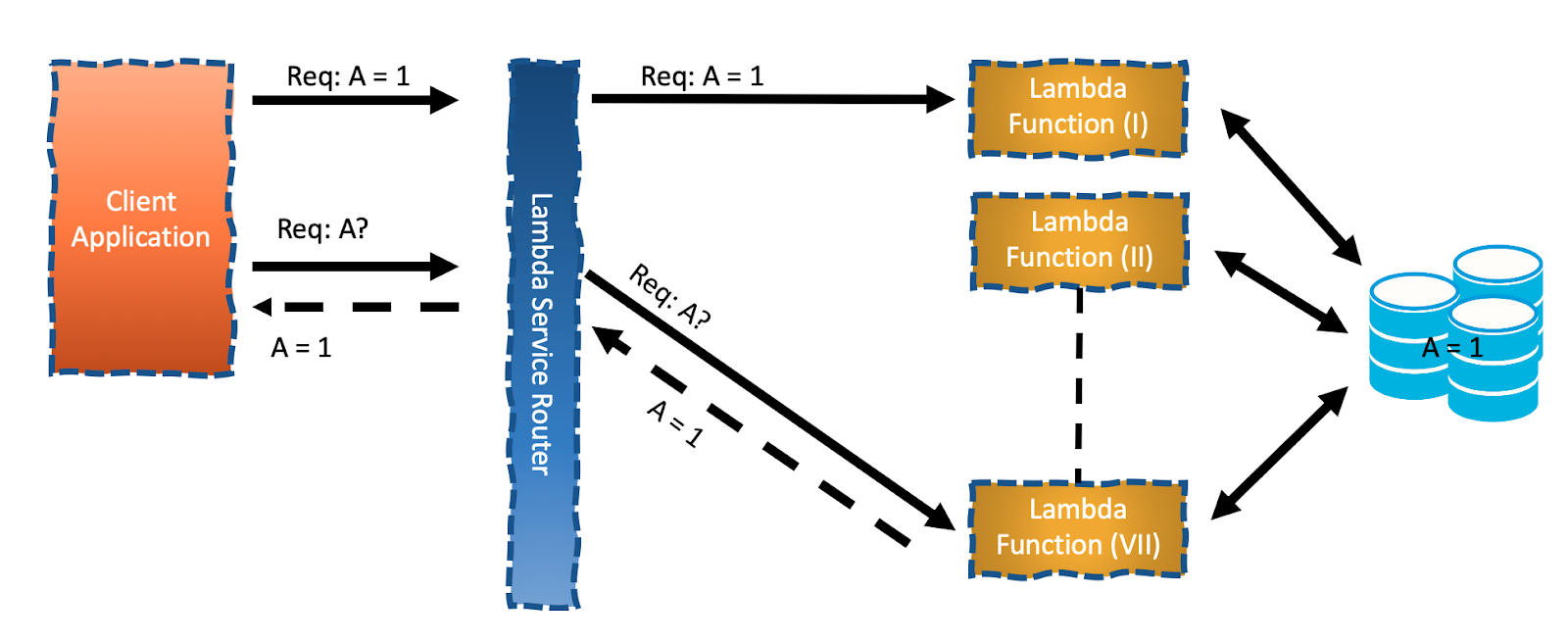
Managing an additional server side entity (DynamoDB, Redis or another custom application/service) can be quite a burden. If a managed database is available for you to then my opinion is that this strategy is superior to the. A fully managed and already resilient database would minimize the additional maintenance burden. That is true either from an IaaS provider or an already maintained one by your DevOps team. Consider a database with a TTL (“time to live”, an applicative feature that the database deletes an item after a certain time) to handle dangling sessions.
That would leave you with costs and coding the integration and maybe some latency due to a server hop, compared to the first offered strategy.
Some would say that it is not a valid strategy at all, as it’s merely propagating session storage from one application to the other. That is indeed technically true but you’d be correct to follow the separation of concern rule of thumb – if there is already an entity in charge of permanent storage it would be wise to reuse it rather than to code it in your own application. That is even more true as scaling and designing highly available applications that require permanent storage is much harder to do than stateless ones [more on scaling databases in a future article]. If someone else already took care of it for you – reuse it.
As it is very easy to save something into an in-memory dictionary/hash map, keeping an application stateless through change would be harder. It takes just 5 lines of code to break it. Stateless is a rather new approach that not all developers are familiar with, so it would require stricter code review, at least in the beginning.
It can be automated with tests. Wrap your class (use reflection if needed) so that each function call will create a new class instance, thus consecutive calls will be ensured to reach different class instances, simulating a stateless run.
Synchronous invocations in asynchronous systems
You can not control to which instance a request will be routed to and a Function instance can only process one request at a time. This will lead to a problem in asynchronous systems.
Let’s presume that you have two Functions. The first Function is invoked by a client, which expects a 200 when the process is complete. The first Function invokes the execution of the second Function in an asynchronous fashion, like putting a message into a queue, to be later actually processed.
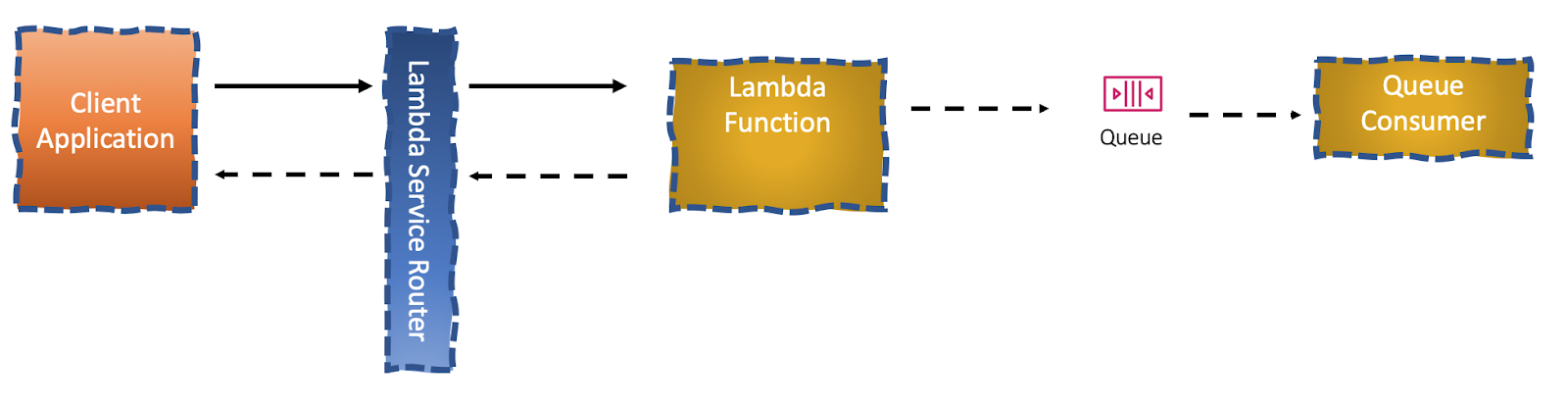
After the first Function had put a message into a queue, it would then finish its execution and return 200. That is 200 on execution complete and not on process complete. Not what the client expected.
With a Container, that wouldn’t be a problem:
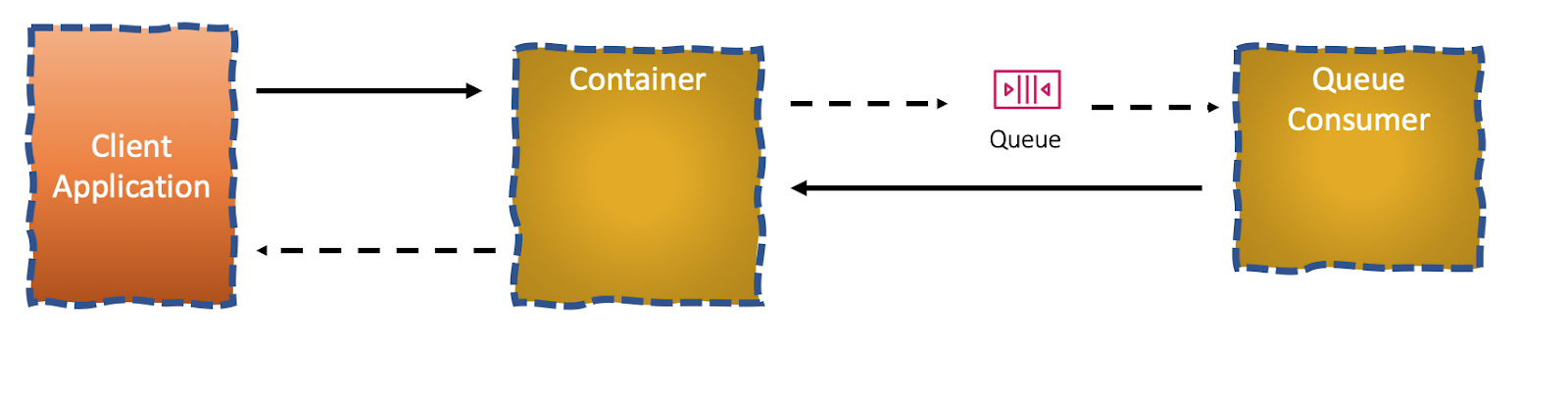
Unlike a Function, a Container can be invoked from several ends concurrently.
The Container would keep the client connection alive until it gets a confirmation from the Queue Consumer (may require an internal lock). Upon process completion, the Queue Consumer would directly invoke an HTTP endpoint on the same Container instance (or through a load balancer with sticky sessions). The Container would then release the connection (and the lock if required) and reply 200 with the process result as the payload.
This is impossible to do with a Function, As a function instance can only process one request at a time, another invocation would be routed to another function instance. As both of them are stateless and running concurrently, they do not share an internal lock so no way for one Function to hold until another’s asynchronous execution.
We’ve resolved this in Silo using an external lock stored in a Redis. As this was a rather complicated solution with a lot of tradeoffs and alternatives, I shall further elaborate on it in a future article.
Ephemeral Instances
AWS’s Spot Instances and Google’s Preemptible VM Instances are virtual servers that you can launch for a lower cost (up to 90% off!), but nothing comes for free. These instances can be taken away / deallocated from you within a short prior notice (AWS is 2 minutes, Google is 30 seconds).
Stateless applications can withstand such a short and abrupt termination. That is true both web applications and enqueued offline jobs (with a retry mechanism). Stateless applications could be cheaper to run than stateful ones!