Containers were a huge step forward for Cloud Computing. Not only did they make the developer’s life easier, but also had a major impact on the world of operations, on design for high availability and system resilience.
The “single” application problem
To understand what Containers has resolved, first we need to address what the problem is. Let’s inspect a simple 3-Tier architecture from two perspectives/views.
An applicative view of it would be:
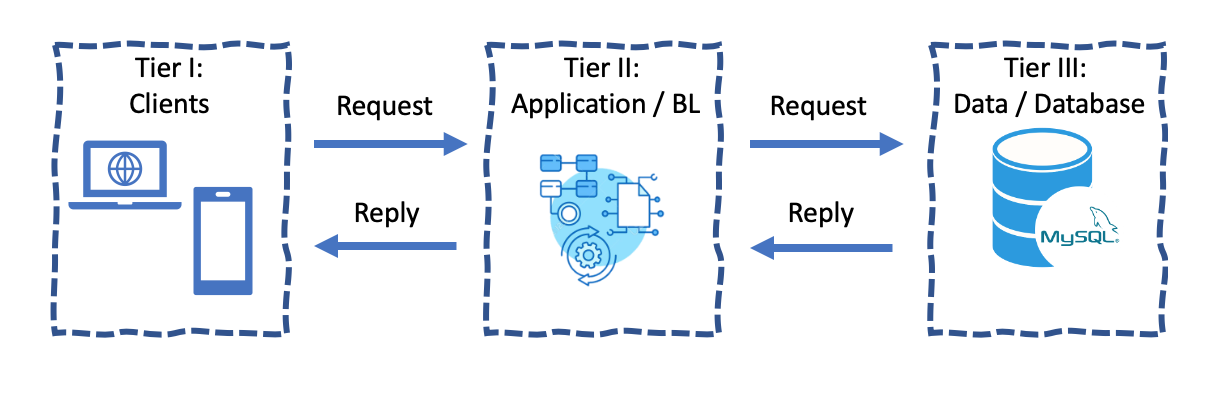
- Tier I consists of application clients such as Web Browsers and mobile applications (irrelevant for this discussion).
- Tier II currently consists of a single web application that processes business logic, where the “server code” is.
- Tier III currently consists of a single MySQL database, consumed only by our single web application.
An operations view of it would be dependent on how you’d distribute the Tier-II and Tier-III applications between the underlying servers (Note: from now on I’ll be using the term of underlying servers to describe virtual or bare metal servers).
This is an application view of the system. What is the operations/server (virtual or bare metal) view of it? How does one distribute the applications between servers?
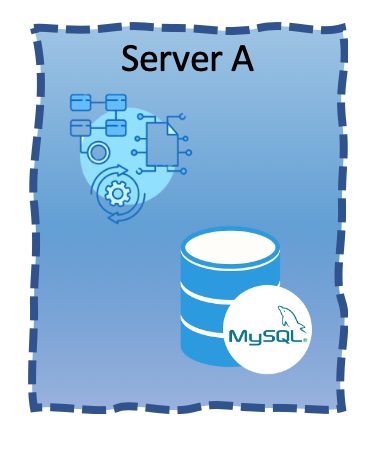
A view where both applications are placed on the same underlying server would look like:
A view where each application is placed on its own dedicated underlying server would be:
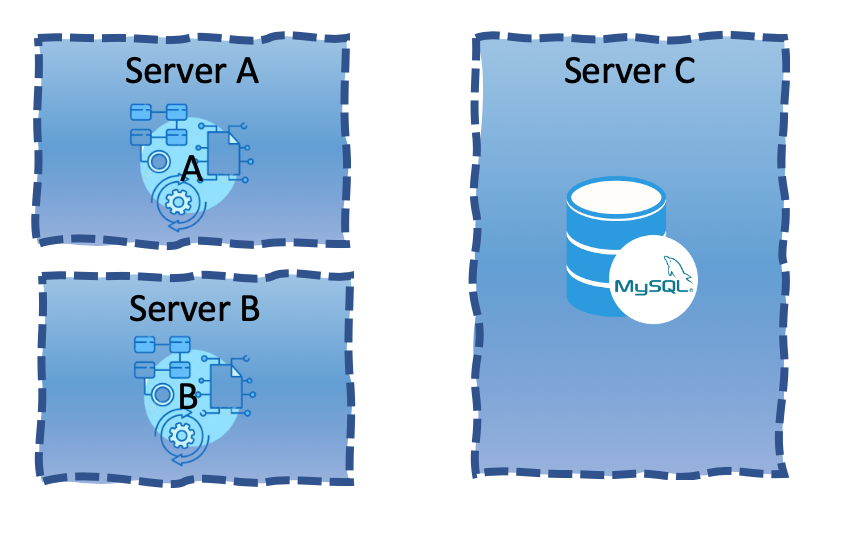
As you pay per underlying server, the first view would cost less as it needs less servers. The problem would be a runtime dependency between the two applications. If for some reason the web application crashes, it may take down the entire server and the MySQL database with it. As databases are an extremely sensitive component in any system, that could be disastrous.
Imagine the following two common issues:
- The web app logs clogged the hard drive due to a traffic spike or an error. MySQL can not write to his files as no empty space is left.
- The web app has been updated. A few hours later and turns out it includes a memory leaking bug. The entire server memory has been consumed thus crashing MySQL.
Is the second view/distributions any better? Depends.
If your application and the database are tightly coupled and the application is the database’s only consumer, maybe you shouldn’t care what happens if one goes down as the other can’t live without it anyhow. The web request can’t be fulfilled either when the web app is down or when the database is down. So maybe it’s not that bad if they crash down together.
That will not be the case at all when your company grows.
The multiple applications problem
Let’s presume you have two web applications, both requiring MySQL.
- Web App A is mission critical. It is your online retail store. The money maker.
- Web App B is your internal portal used mainly by your employees.
For starters, let’s place them all together on the same server to reduce costs.
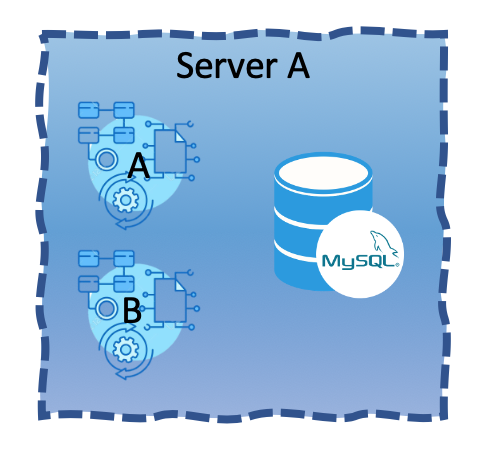
[The following scenarios are taking memory leaks as an easy to explain example. Although it is somewhat of a rare incident, remember that applications can bring down servers for a whole lot of reasons]
Consider the following scenario of someone pushing an update for Web App B with a memory leaking bug. It had crashed the server. Web App A, your mission critical one, goes down with it causing you a huge loss in unmade sales. This can not happen no matter what. There is no way to avoid distribution between multiple servers.
Question: Which of the following distributions/placements are correct?
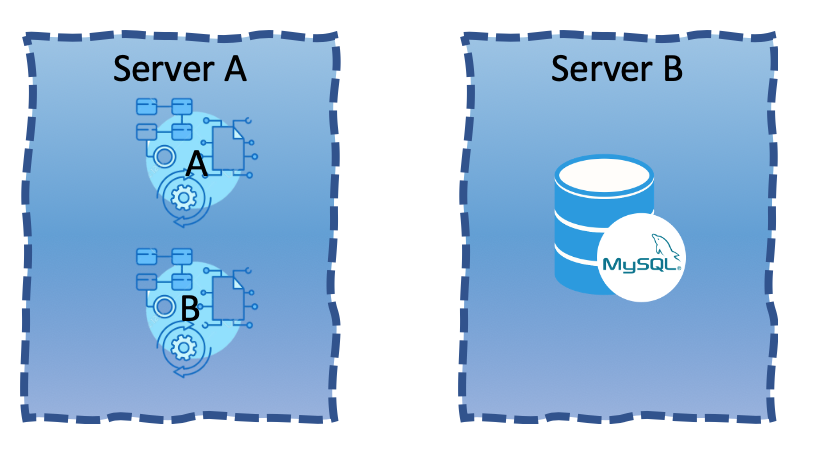
Solution I: Place the MySQL DB to a different server
Solution II: Place one of the web applications on a different server
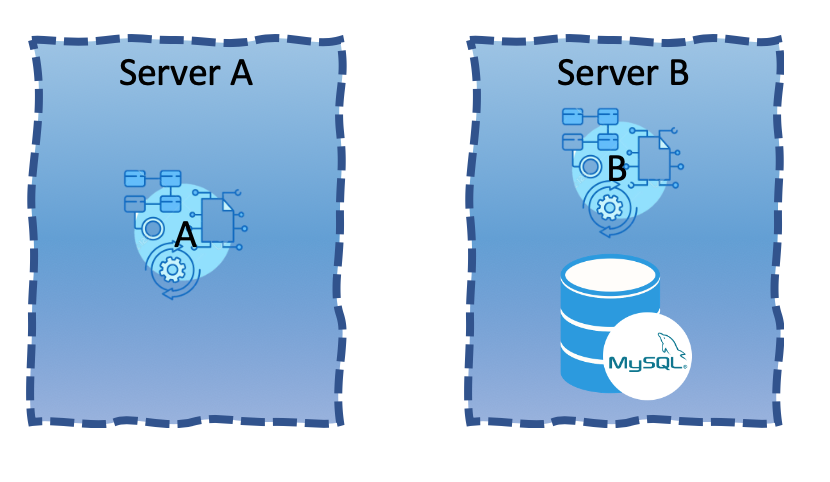
The answer is neither, as both solutions do not solve the problem. If by accident a memory leaking bug has been pushed to Web App B, it either brings down Web App A with it (Solution I) or brings down Web App A’s dependency, the MySQL server (Solution II).
A third solution to consider would be to put each application in its own server.
Scenario has been resolved with a resilient enough solution.
Consider another scenario where Web App A and Web App B do not share any data (if they do, that’s an architectural issue that will be discussed in another article). One day someone pushes an update of Web App B that runs a very resource consuming query on your database. That may/would affect the response time of your mission critical Web App A thus ending in money lost on unmade sales. There is still a dependency between the two web apps through their mutual dependent database.
It would make sense, as they don’t share any data or tables, to launch another instance of MySQL.
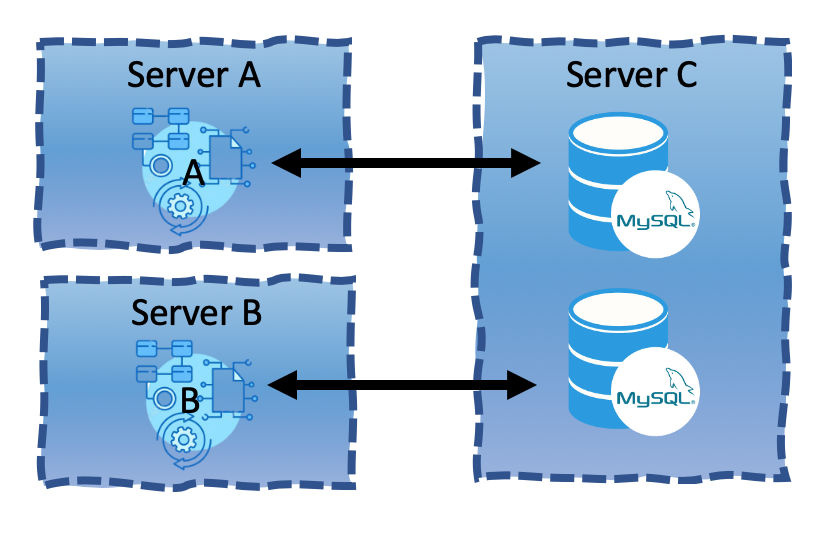
Unfortunately again we have resolved nothing. Server resources are still shared between the two MySQL instances. The resource consuming query is only being performed by another process with no more actual resources available. Adding more resources is somewhat possible if it’s a virtual server and it may be enough to resolve the issues. Unfortunately it is still not a fully resilient design as we’re back at the same problem of the previous scenario. One database can crash the other, just like your Web Apps can do to one another.
Resolving it again would lead us to place each database on its own server as well.
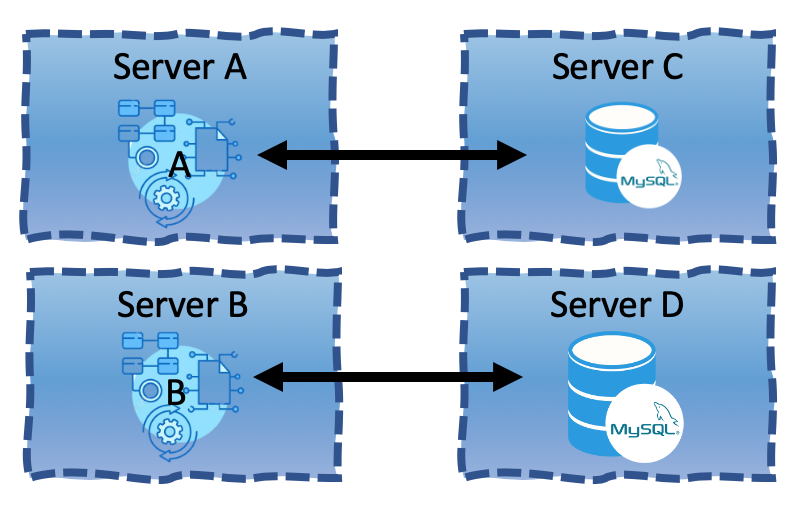
A resilient design would require four servers. No application shares any kind of resource with another. A resilient design requires isolation. Isolation requires each application to run on its own dedicated server. That’s insanely costly and highly ineffective. Each server is now under utilised as any application is far from using 100% of the server’s resources. Do not forget that each server is another server to maintain!
You should also consider that databases may not be free. You may be using MS SQL Server which requires a paid license, or a managed database where you pay per instance launched.
There is a tradeoff between isolation and costs.
Redundancy and High Availability
Isolation adds to resilience, but does not suffice it. Running only a single instance of an application is not resilient at all. If it crashes, or even if it’s just merely down for an update, it is 100% unavailable.
Redundancy is always having two instances live and ready to process. It can be in a hot/cold or a master/slave set up. That would be only one instance is processing at a time, and the other will completely take over when needed. Another optional set up is where both instances are concurrently processing, and the load is distributed between the two.
Concurrently processing instances is supposedly more cost effective as if you are already paying for it you should also utilize it. But would entail taking care of load distribution which is not always that obvious and easy to do. Even just introducing a simple load balancer, is another component to be familiar with, set up and maintain, not to mention the applicative consequences [see Irresilient Sessions: Stateless Applications]. Even if it was easy, who says you need that extra capacity at all, maybe it’s already enough and you’ll be gaining nothing?
The operations/distribution view would be:
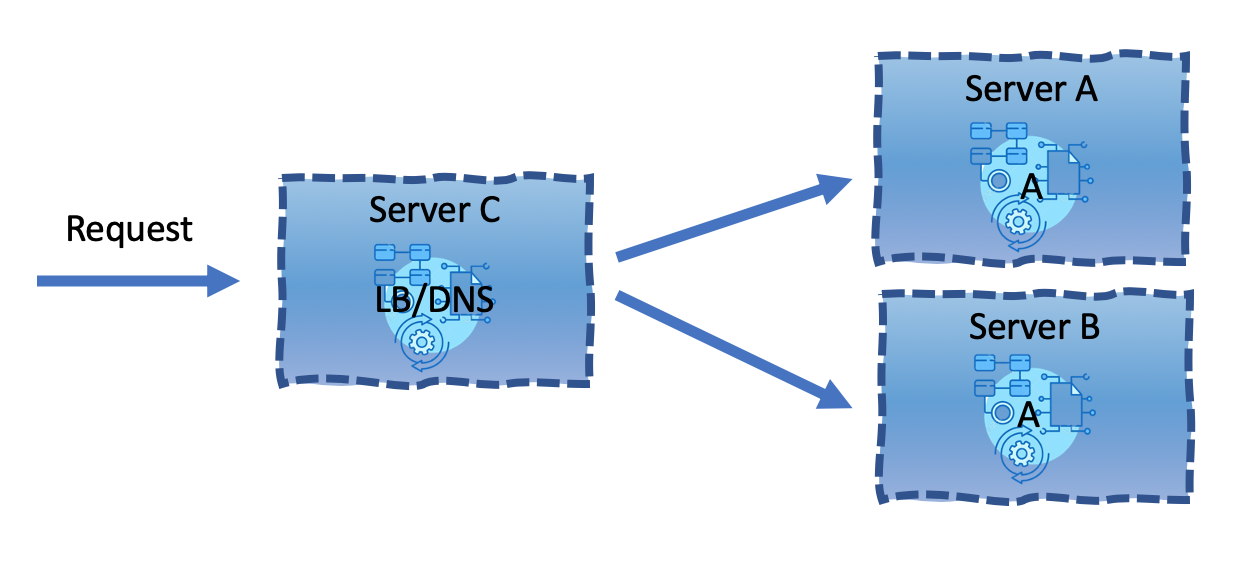
You’d notice that the above is already an isolated design. If we set aside that LB/DNS is not redundant, that would mean double the servers to achieve a redundant design for our 3-Tier architecture. The 4 servers we had before are now 8 servers.
A redundant design is still not sufficiently resilient, as it’s only in a resilient state when both instances are available. If one of the instances will go down, either for an update or due to a crash, you’ll be in a time frame where only a single instance is available, which is not a resilient state.
A highly available design consists of at least three instances available. If one goes down, you’re down to a redundant state which is still a resilient state. Yes, there are still the odds of two going down together, but they are significantly lower. If an application instance uptime is 95%, the odds of two out of three going down together unexpectedly is 0.95*0.05*0.05 = 0.002 = 0.2%. That is 99.8% percent uptime.
An isolated highly available solution would require three times the servers, that is twelve servers required. It’s even more than that, because load balancers are needed and they also need to be highly available so add another 3 to 6 servers. Trust me, it doesn’t end even there. Don’t forget that all these underlying servers require constant maintenance, upgrades, security patches, etc’. Now you also need to hire a full time DevOps engineer.
Resilience costs money. A lot of it. Now at least you understand why the Ops team needed 20 more servers. That would be an annual bill of about $36k to your cloud provider (more than that to buy bare metals) plus $200k for another engineer due to maintenance. These costs do not scale well. As the CEO you’d probably tell them to do it for half the amount and he’d be back bundling/running applications together on the same server. It could be fine you know. Maybe high availability is too much for the business and redundancy is enough. But then one day COVID-19 hits you and everything goes down the drain, just like what happened to all the Supermarkets in Israel, and many of the government’s web sites, you know the ones where I had to enroll for unemployment benefits while I was writing this.
So you may absolutely need maximum resilience and you just can’t afford it. Must there be a tradeoff between resilience and costs? Suddenly one day in 2010, Solomon Hykes, the founder of Docker, remembered some forgotten feature in Linux OS called LXC, which completely revolutionized the industry and has dramatically lowered the price of cloud computing and resilience costs, making it available for anyone.
Container Isolation
At a previous article I’ve mentioned two traits of Containers:
- OS independence – the “compiled” container comes with all the OS dependencies required
- Identity – the “compiled” container runs exactly the same no matter where it runs
There exists a third one:
- Isolation – a “compiled” container is running almost completely isolated from other containers and on top of the OS, with dedicated resources.
In terms of application distributions between underlying servers, imagine that the Container is “a shield” around the application. When it crashes, instead of an explosion full of debris hitting other applications and the server itself, the shield would cause an implosion. the Container would crash into itself without harm to any others.
If before I stated that isolation requires each application to run on its own dedicated server, with Containers that is no longer the case. as each application is a Container, a self-isolated one, there is no need to isolate each application on its own server.
The operational/distribution view would no longer be:
It would be a single host full of “shielded” applications:
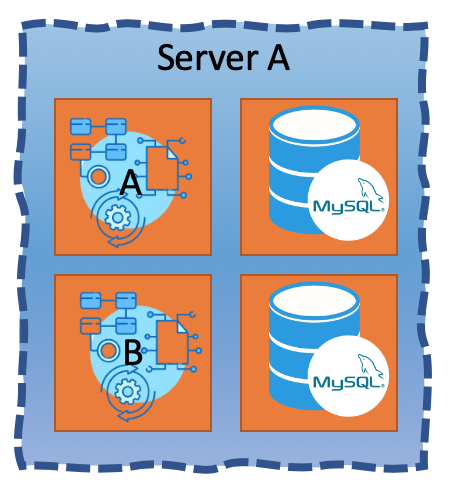
One server instead of four. If we wish to implement a design for high availability, meaning three instances of each application, we’ll end up with 3 servers instead of 12 (you still shouldn’t place two instances of the same application on the same server, as the server itself can still crash and take two of them at once). We have gained the same level of resilience with high availability and isolation, for less costs, and costs that scale.
Containers are amazing but it took a few more years for it to become a de-facto standard, as it also gave life to a whole new set of issues and problems. That and more in the next article.
Note:
Containers differ from Virtual Machines.The two technologies are complementary, but they are technically different. a Virtual Machine is an entire OS completely isolated from the host that can run multiple un-isolated applications within. A Virtual Machine requires the same OS maintenance as a virtual server.
A Container is a single application packed with its OS dependencies, but sharing the host OS kernel and is running on the host OS User space. A Container is slimmer, more portable and the application within it requires no OS maintenance at all.