Containers are so amazing but do they also present new challenges in the Ops world.
Let’s continue with the example from the previous article, two applications and two database instances. For simplicity and generalisation, let’s presume that all the applications in the world require exactly 1 CPU and 1GB of RAM and also all the servers in the world have only 4 CPUs and 4GB of RAM. Each server can host only up to 4 applications.
At your present company, the current application operations/distribution view is:
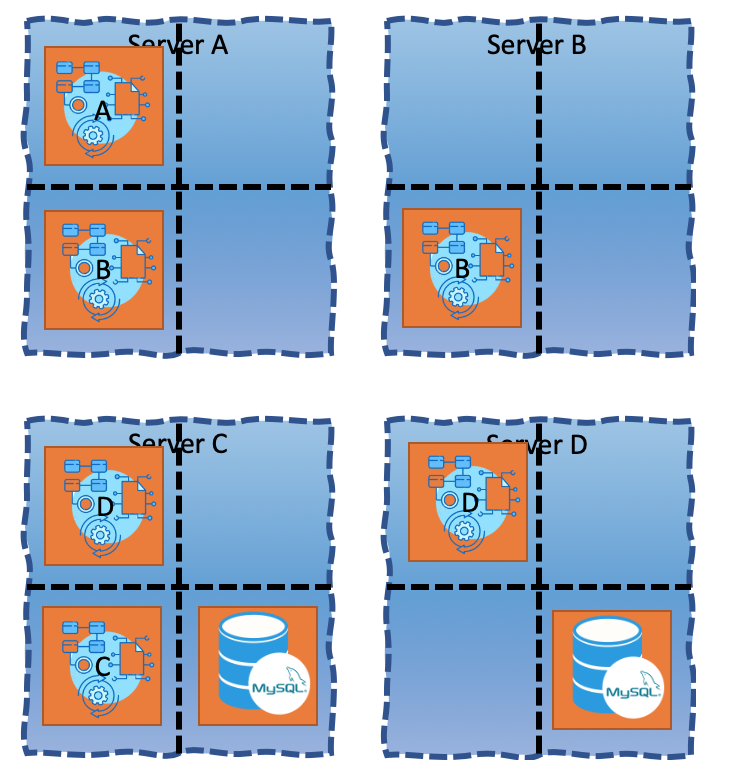
If you’d look, not even carefully, you’ll see that you’ve been paying for two unneeded servers, too many resources are available. You’d be logging in to Server B and Server D and move the containers from them to Server A and C:
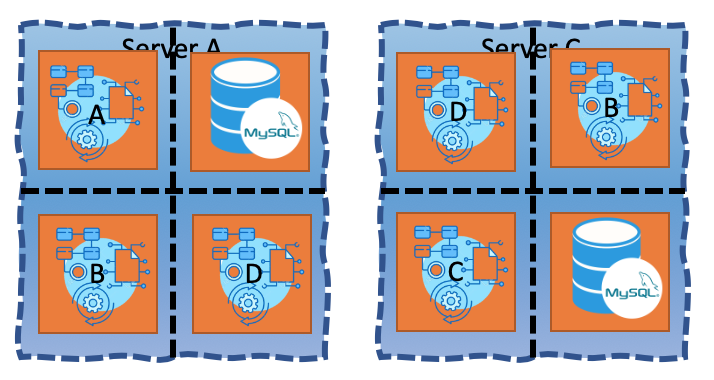
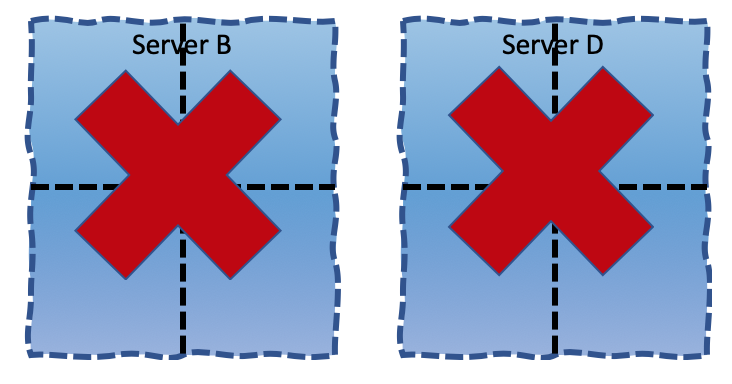
You’d even made sure that no two applications of the same kind are on the same server and you’d be taking down Server B and Server D and you’d save the company some money. Congrats, you’ve saved the company a lot of money and you are now up for a promotion!
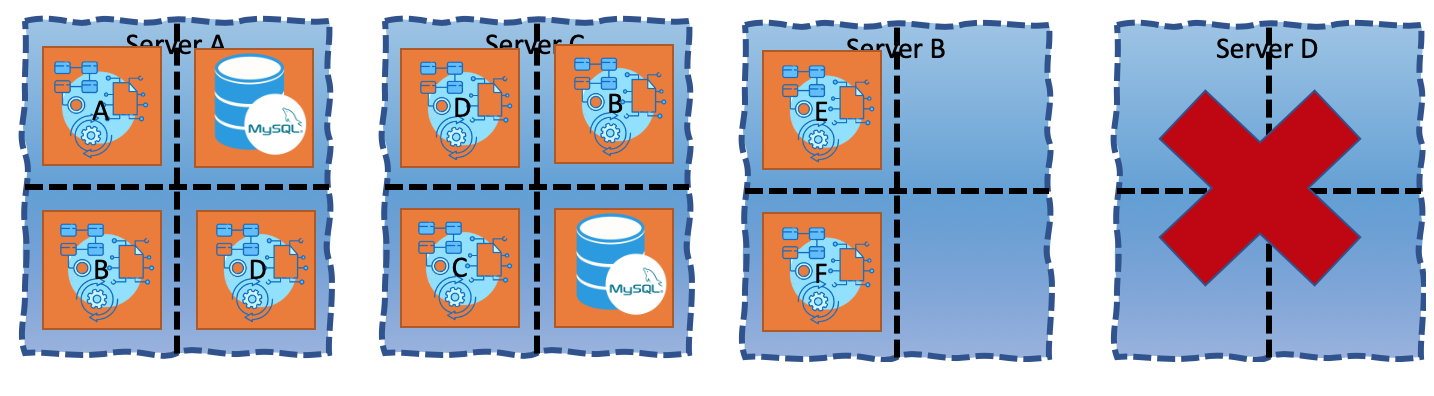
A week later you come to work to find this current view:
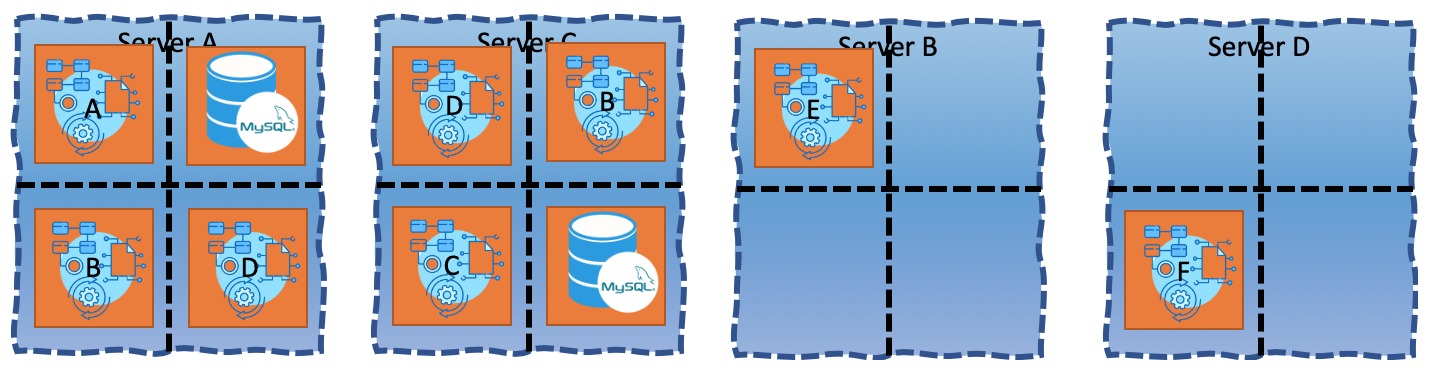
You are star struck. How can this be if you’ve just removed these two servers last week! What happens, it turns out that:
- Dave from the Dev Team I, who is allowed to launch servers, launched Server B and is now running application E on it.
- Dan from Dev Team II, who just like Dave needed another server, launched Server D and placed application F on it.
- They were both just doing their job, concurrently.
You’d be emailing them both ranting “Oh come on guys! Couldn’t you figure it out on your own to place them both on the same server!?”. Dave replies and says “Who is Dave?” and Dave replies “Who is Dan?”. You do your job and move App F to Server B and kill Server D.
The Human Bin Packer
Remember that promotion from before? You’ve been promoted to a bin packer. Your job now is to do this every morning. To make sure that no company resources are wasted due to incorrect container/resource allocations. Although it is necessary and beneficial it’s quite annoying, repetitive and time consuming.
If we’d take this simple example towards the real world scenario, we’d see that having a person moving containers around all day long is infeasible:
- Each application has various resource demands, different CPU, RAM and disk size.
- Auto Scaling: Application instances scale up and down with traffic unpredictably. Need to launch more containers.
- There’s a point where not enough server resources are available for more containers. Need to launch more servers.
- On scaling down, you’d need to reallocate containers to servers (bin packing) in order to save server costs and shut down some servers.
- There is a single application instance, a single job, running once a day at 3PM for 20 to 60 minutes that suddenly but predictably requires an allocation.
- Due to load balancing and high availability, our resilient design from the previous article requires around 30 containers at least. And that would be for one web application.
- How many web applications are there? Way more than two. In a non-monolithic architecture, there could easily be hundreds of applications running, leading to thousands of containers.
- There is a recurring job, that consists of thousands of independent smaller identical jobs (batch processing) that need to be executed at various times with various resources. It would require continuous non stop allocation and bin packing.
Eventually, when your company is big enough, you’d need to be up 24/7 or you’d hire three experts with rotating shifts in order to manage a constantly dynamic environment that constantly requires dynamic resource allocations (Auto Scaling) of thousands of containers and of the underlying servers. If you want to visualise it properly it looks something like this:
Sort this mess ————————————————————————————————–> into this mess

It is a well known problem called the bin packing problem. If only this entire burden and waste of time can be coded and automated somehow, so you’d can go back to focus on the money makers.
The Humanoid Bin Packer
To your rescue, comes The Container Orchestrator, and you may have heard of some.
There are many such as Swarm, AWS ECS, Rancher or the most known of all – Kubernetes (K8S). Each one differs in levels of abstraction, decoupling and obfuscation of the server pool from the application delivery. They differ a lot more in terms of maintenance, usability, functionality and integrability but that’s beyond the scope of this series of articles.
The most basic/low level orchestrator (Swarm) responsibilities / capabilities are:
- To maintain the pool:
- To add worker nodes (servers) to the pool
- To remove worker nodes from the pool
- To deploy an instance of a Container somewhere in the pool where required resources are available
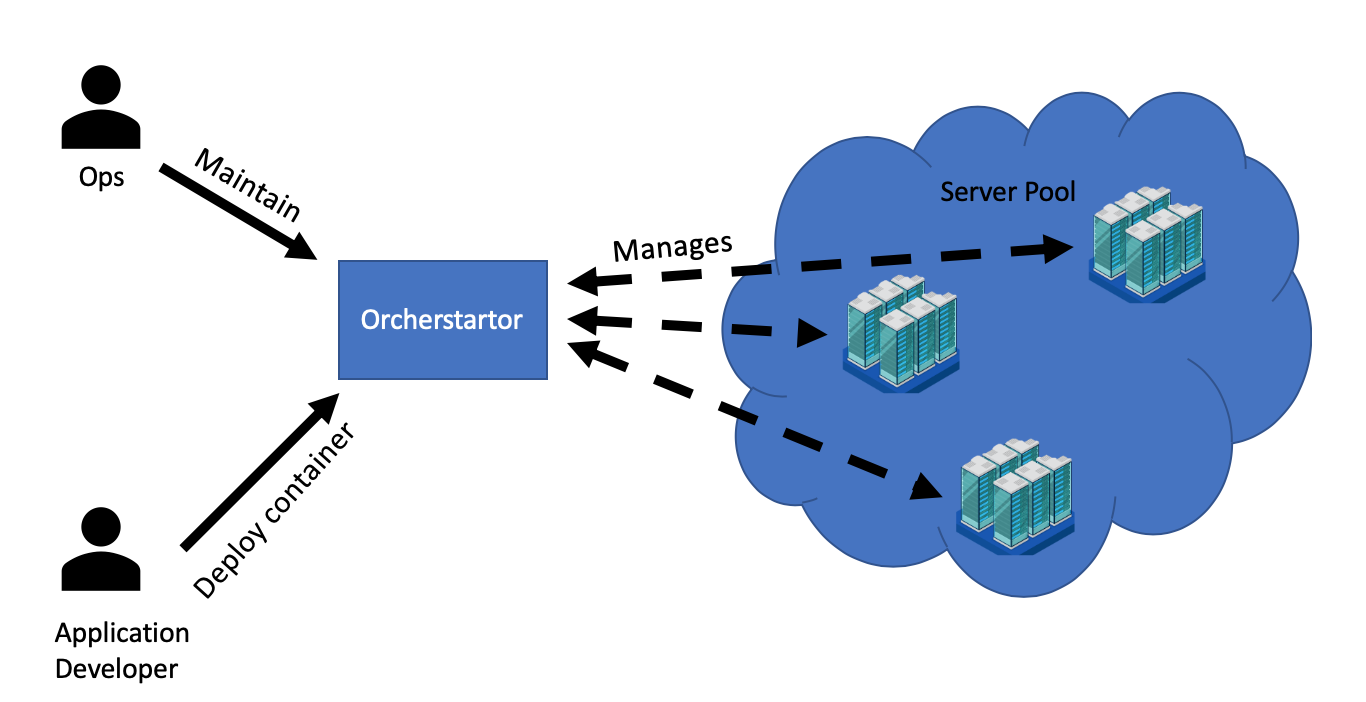
A huge workload has been lifted both from the Ops and the application developers. An engineer can deploy his containers without any assistance from the Ops. That would be a huge change in the delivery process to a far more simpler, faster and safer one.
An application developer, a scheduler or a CI/CD platform, can directly ask the orchestrator to “please take this container with Application A in it that needs 2 CPUs, 4GB of RAM – and you find the correct server for me”. The Orchestrator would be looking for a server that meets the resource demands, passes the Container to it and commands the server to run it. Later, the developer would remember that it actually needs three instances and he’d ask the same of the orchestrator. The orchestrator does his job again of looking for servers that meet the resource demands and would launch more containers – if possible.
Alas due to separation of concerns and infrastructure agnosticity, the orchestrator can not launch more servers on its own. If the orchestrator has determined that no more resources are available, it would warn the Ops guy who will need to launch a new server with enough resources and add it to the pool. Technically speaking, the server would be the one asking the orchestrator to be added to the pool.
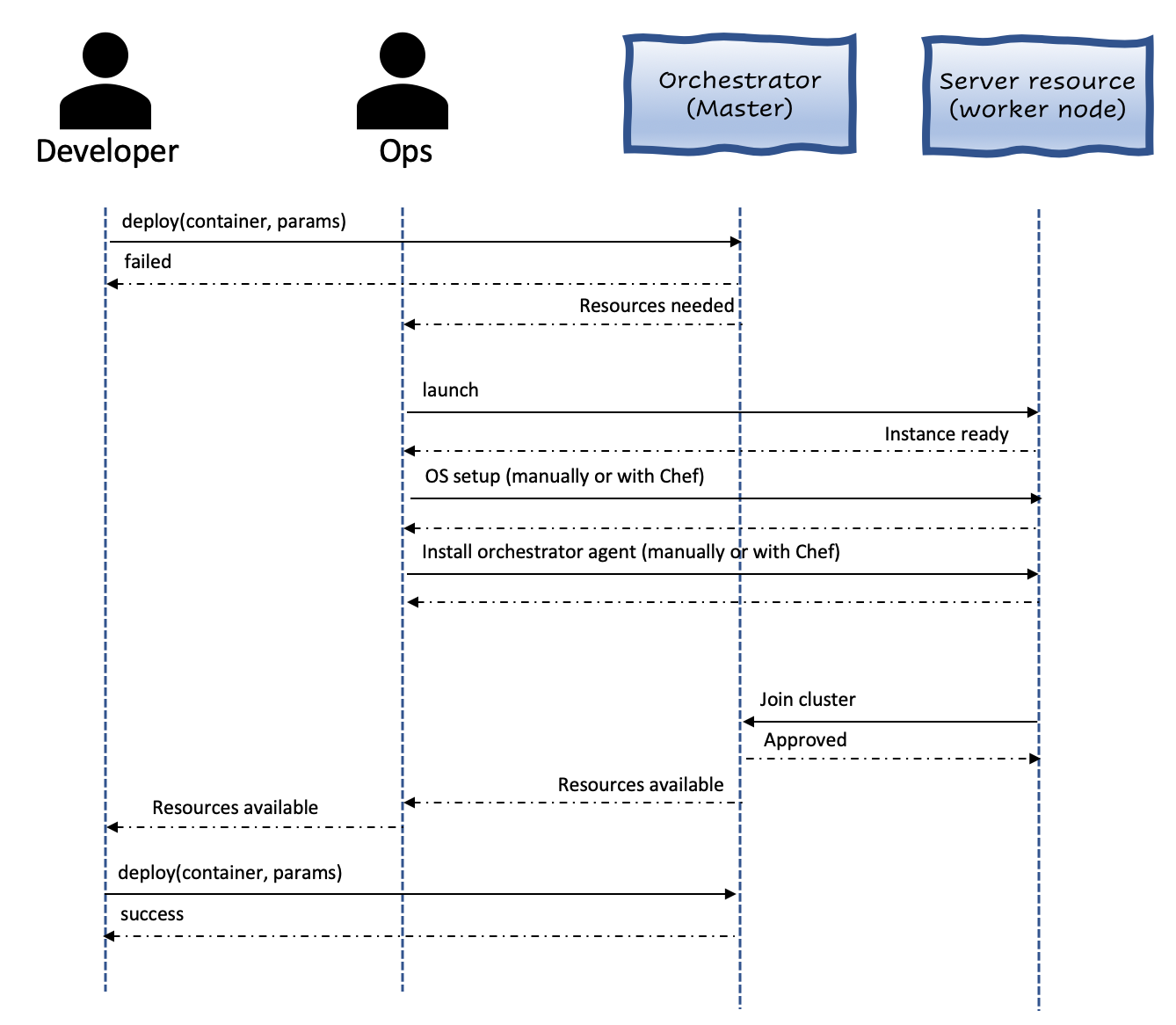
In case there are too many resources available, it would be the Orchestrator’s responsibility to alert the Ops guy to shut the server down. The orchestrator needs to be notified that the server is shutting down. Only then it will redistribute all the running containers to the remaining available servers. This is how having an Orchestrator resolves the bin packing problem.
Two steps forward, one step back
Unfortunately the Ops engineer is still in charge of launching and maintaining the underlying pool of servers:
- An orchestrator is not a “worker node”, it is a “master” application. Resilience requires an isolated server to run on, meaning at least three servers (although managed masters exist such as AWS ECS and AWS MKS, more on these later),.
- Integrate with the cloud provider’s Auto Scaling feature for dynamic launch and shutdown of servers (or to order more bare metal servers in advance).
- Each “worker node” is a server to maintain. It would need to be patched up, secured, updated and that includes the orchestrator agent as well. The could about potentially be tens and hundreds of servers. Updating an entire pool is not an easy task at all.
- Resource utilisation and costs optimization against predictability are still in need. If the orchestrator needs 4 CPUs now and only a 16 CPU server is available you’d be wasting 75% of it.
- Container Auto Scaling with traffic – still needs to be addressed
- Some application level issues remain, such as de/registering containers with the load balancer.
Container orchestration is a huge step forward in cloud computing evolution. Your bin packing problem has been resolved but has yet to reach an optimal cost solution. Server maintenance is still required, although far less as all servers are almost identical in nature. A dedicated personnel is still a must, although maybe now not a full time one.
Underlying server maintenance can be further reduced to almost zero with another leap in evolution with Serverless Compute.