
So far in this series, we’ve been building a Plan bottom-up from its small components, the Tasks.
We’ve seen how each Task is born into Uncertainty. Minimizing uncertainties, is making clear what we do, when we do, how we do and what is required to do. Effort is required to make a Task certain enough (95% certain), which would make our Plan more certain as well. We’ve seen how a Plan is affected by Unpredictable Tasks. Those interrupt our Plan during its execution. And are catching us by surprise.
On its own, a Plan has more Uncertainties to remove and Unpredictables to consider. In this chapter, we’ll explore those combined.
Things that we Know
We’re more than half way through the modeling process of Planning. Let’s take another step forward and model the relationship between Tasks and Plan via Predictions & Uncertainties. A model that would help us classify Tasks according to the last two.
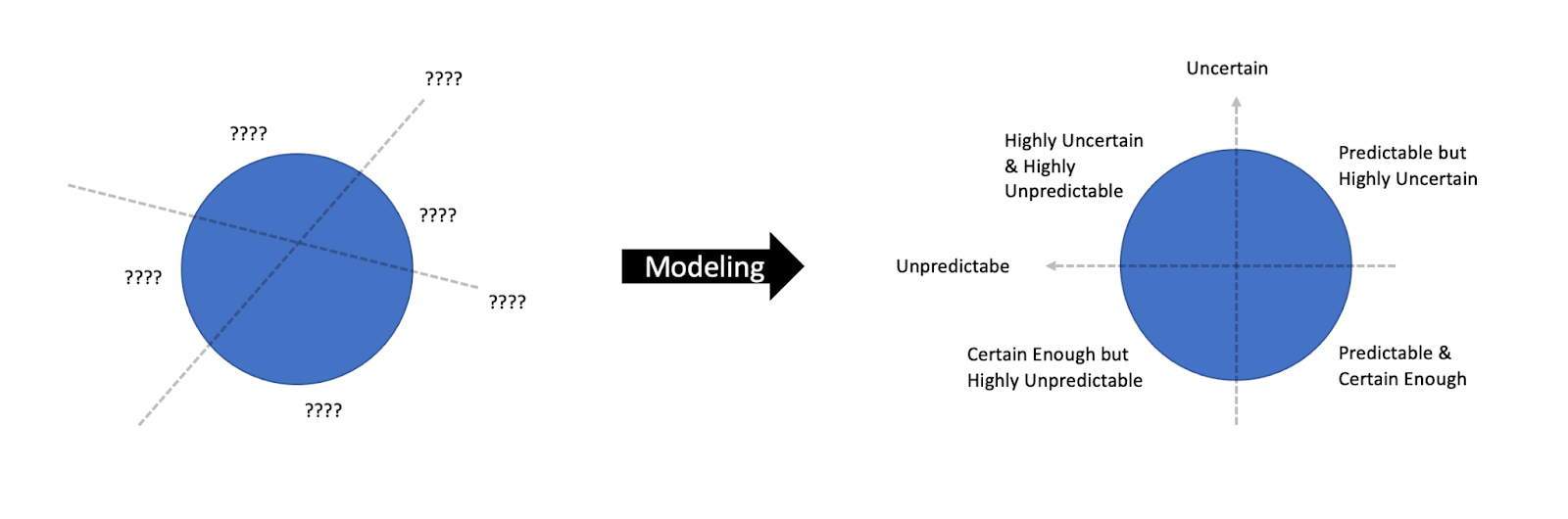
Each quadrant is actionable:
Predictable & Certain Enough Tasks
Tasks which we are as sure as we can be of. We know the who, the what, the how and the when. Nothing left but to get it done. Commit these Tasks to the Plan.
Highly Uncertain & Highly Unpredictable Tasks
We can not commit to Tasks that do not yet exist during planning. They surface only in real time. For those, we should leave a High Variance Buffer outside the Plan.
Certain Enough but Highly Unpredictable Tasks
These are the real time incidents, the down time. Again we can not commit to what we do not know. But even without knowing, we can guarantee in advance that less effort would be required. Monitoring and tracing allow us to faster catch and handle real time issues. So does Continuous Deployments.
Both result in faster recovery time, smaller means and lower variance (MTTR) in execution when facing the unpredictable. Leave a Low Variance Buffer outside the Plan for these kinds of Tasks.
Predictable but Highly Uncertain Tasks
There are Tasks that have a self contradiction, where reducing Uncertainty is the majority of the Task itself. For example, most effort spent on a Bug is into tracing it, understanding it and reproducing it. In comparison, it’s a marginal effort to fix the bug.
In these cases, it is better to not reduce its uncertainty but to Fence the Effort: “In the next Sprint we’re going to invest up to X days into fixing our top priority bugs”. Yes, I’m honestly saying do not estimate bugs in advance. It’s non-beneficial.
But that’s not the end of it at all. The process of predicting and uncovering uncertainties to each Task independently, has an effect on the plan in its entirety. They optimize the sizes of the predictable/certain quadrants.
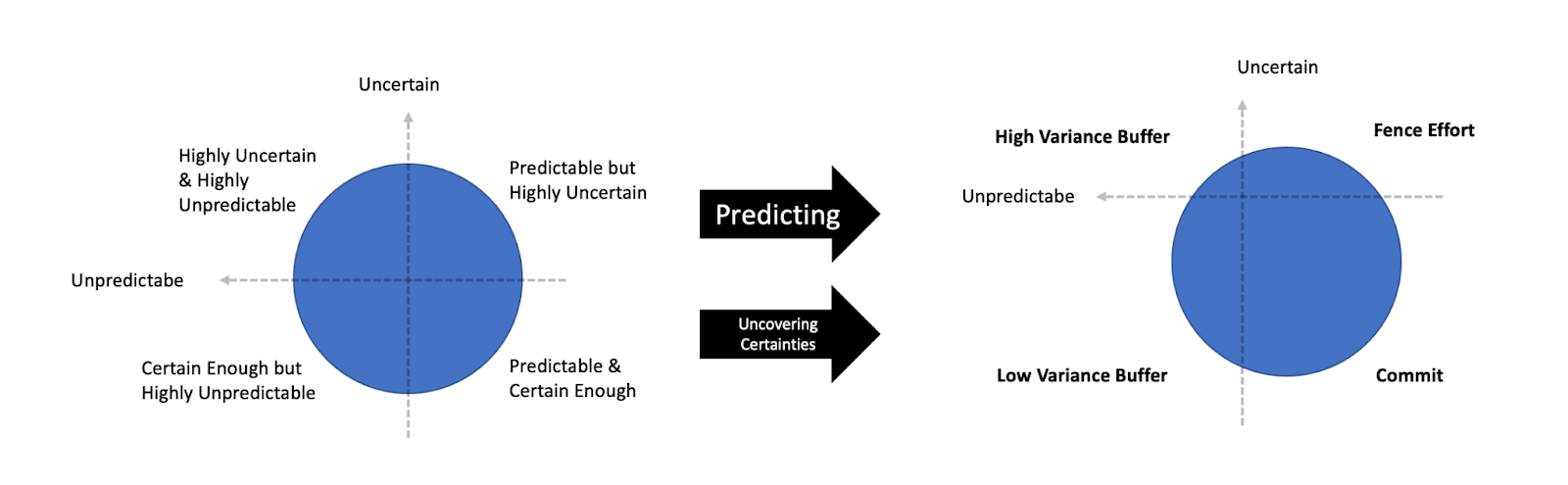
The outcome would be a less unpredictable and less uncertain Plan.
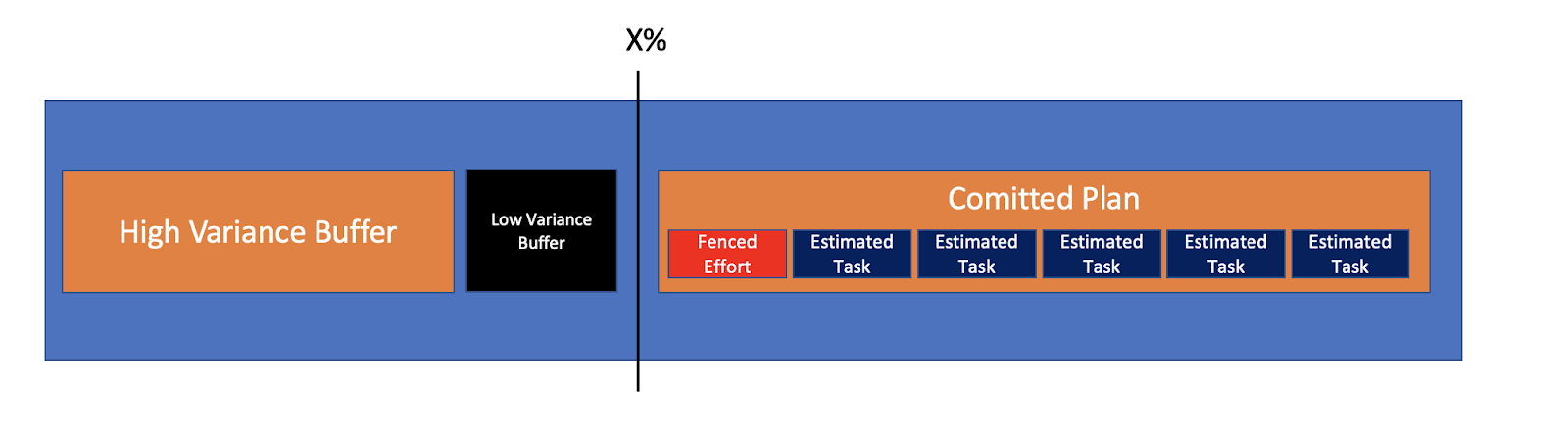
The Committed Plan is highly certain, and so is the effort required for it. The Estimated Tasks have gone through the process of uncovering certainties, and are certain enough (95%). Tasks whose uncertainties should not be reduced (bugs), are all fenced by a constant number which is 100% certain.
A Distributed Buffer
Actually, the Low Variance Buffer should not exist. Yes, we’ve made it all the way here just to say that there is a buffer we should not take. But we have to make sure we meet the conditions to do that.
If truly unpredictable incidents do occur, the act of predicting also ensures minimizing the frequency of these incidents. And we’ve seen that Continuous Deployment, Monitoring and Tracing have the potential to minimize the reaction’s effort to a matter of mere hours.
Even if we have 5 such incidents a month (and that’s a lot!), it would add up to 1-2 days. A team of 5 has 100 days of effort a month (20 per person), so these incidents add up to 1%-2% of a buffer. That is a negligible buffer to take.
Lastly, this Low Variance Buffer does exist on its own. It is spread across the Estimated Tasks. Let’s recall that each Task is a Change, and it entails a Feedback which entails another Change. To accommodate, we can plan for Change and add Sub-Tasks or more Tasks.
Let’s also recall that each Change has the potential to cause Instability. It is predictable, and each Estimated Task should already include a variance/buffer just for that.
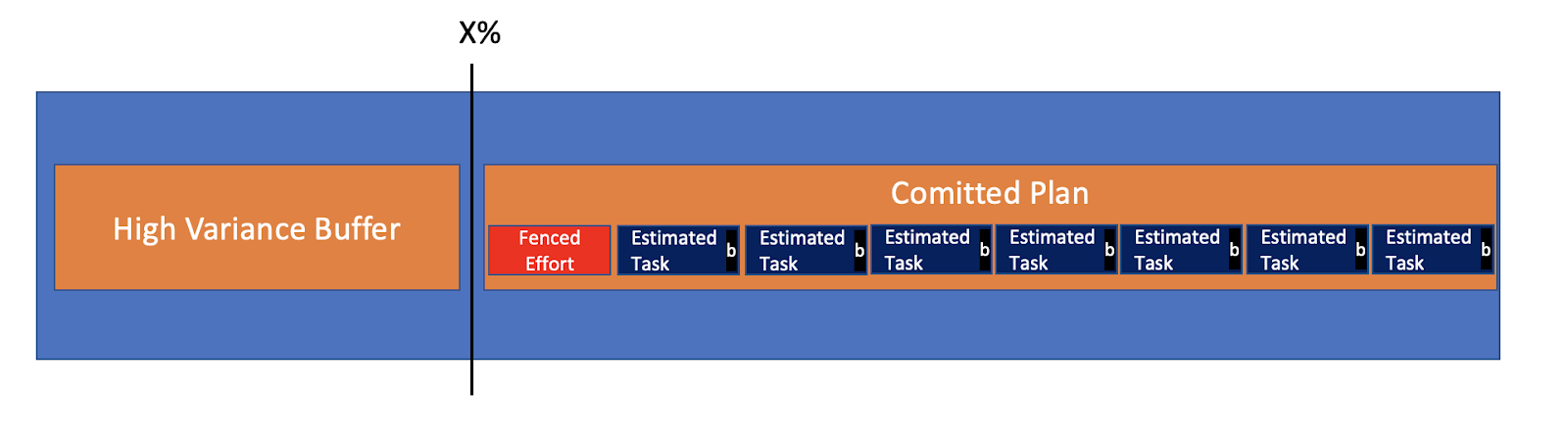
As such, we can entirely remove the Low Variance Buffer and commit more Tasks to the plan. That is a Plan that gets more job done, with the right expectations set.
We’re left with the High Variance Buffer. Maybe finally this is the once we call the maintenance buffer. But.. It isn’t!
There is no Maintenance
In order to understand what the High Variance Buffer buffer is, we need to understand first what it isn’t. Let’s classify our Tasks according to their expectedaffect on the business:
- Move the business forward – product-driven/customer facing Tasks, such as Features, User Stories, Products. Bugs that directly affect customers belong here.
- Loss prevention – Tasks that we know will cause a loss if not eventually done at the right time. Bugs that indirectly affect customers or affects the team belongs here.
- Inefficiency removal – Tasks that increase our Velocity and give us more capacity to do more Tasks.
I suspect the last two are what we commonly refer to as maintenance, but all three are predictable Tasks that affect the business. As such, they all belong to the Committed Plan, and are not a part of the High Variance Buffer. It is not work v.s. maintenance. Maintenance is part of the work itself.
That answers the question we started this series with, “how much of a buffer to leave for maintenance?”. The answer is none because there is no maintenance. What we do leave a buffer only for is the truly unpredictable incidents.
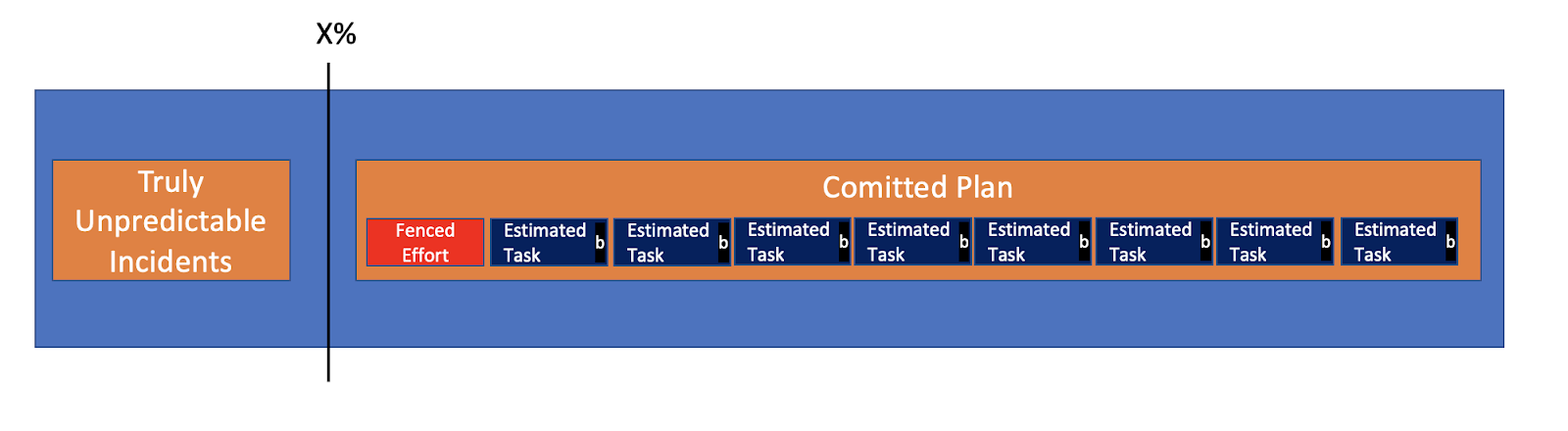
A sudden change in priorities during execution is not an incident but is also truly unpredictable. It could be “this loss prevention Task must be done immediately”, or “this feature must be done now or the customer will bail”.
Priorities change, that’s fine. But that’s not what we leave a buffer for, because they are predictable Tasks as well. Those should change the Committed Plan, as they also affect the business. The buffer is left for incidents alone until nearly the end of the Sprint.
Knowing what we should leave a buffer for, we still need to answer how big of a buffer it would be. If we want smaller buffers, we know what we have to do. The better our monitoring is, the lower the frequency of incidents happening, the lesser the buffer needed. Working on monitoring is a predictable Task with the outcome of loss prevention.
It’s highly uncertain what the next Sprint’s buffer should be. It’s 100% certain what the previous buffer was. A good rule of thumb would be to take a buffer equal to the time spent on incidents in the last Sprint, or a moving average of the last few sprints. Meaning it should be measured.
1 day more or 1 day less than expected, for the buffer is just 1% out of 100 days of effort a month and that is negligible. If the worst happens, and a week of the entire team was spent on a disastrous incident – it is what it is. We’d need to let the Committed Plan go. There is no need to prepare for it, better to replan when it happens.
Do notice that the Sprint’s length also has something to do with it. An engineer’s month would have about 20 work days. 1 day of a month would always be about 5%. If the Sprint is a week, a day is 20% of the Sprint. So the shorter the Sprint, the more likely incidents would break the Committed Plan.
We have one more gap to bridge. The gap between a Task and an Estimated Task, which is to practically remove the uncertainty of it. To properly uncover the Task’s work. On this, in the next chapter.