
“Sorry we were late on the delivery, it took us longer than expected”.
“We don’t know why we got that kind of reaction, we guess we haven’t thought this through”.
“We couldn’t expect that kind of failure”.
As creation involves both, the above could have been the words of an engineer or a product manager. These are the results of trying to execute Tasks that are highly uncertain.
Uncertainty should be minimized, much like we did with the unpredictable in the previous chapter. Let’s see how we do that.
Uncovering Certainty
“Nothing can be said to be certain, except death and taxes”. Benjamin Franklin had a point.
Our binary thinking minds are having a hard time dealing with uncertainty. Nothing is ever 100% certain, so we give up and do nothing instead. Leaving things with 0% certainty. But total uncertainty stresses us out, so we put too much effort to get to total 100% certainty, which does not exist. The Middle Way would suggest to put the right effort and to leave it at certain enough.

The result of no effort would be us being continuously surprised, never meeting any expectations or Deadlines. That would be utter chaos. Putting too much effort into reaching total certainty is non-beneficial, because execution always differs from expectations.
Certainty does exist, but not exactly the way we think about it. Everything created is masked by uncertainty. When we click on the “New Task” button, a window opens. Until we start filling out the Task’s details, the object of the Task itself is in complete uncertainty.
By giving it a title we make it a little more certain what the Task is about. By adding a summary we again make it a little more certain. When we finally click the “create” button it is certain enough what the task is about, but its value and effort are still uncertain. And many other things as well.
Certainty is the outcome of an effort done on uncertainty. But what we actually do is reduce the uncertainty by excavating through it, into the certainty that is in a Task’s core. Physically speaking, it exists in our code and in our minds. We’ll later dig into Uncovering Work (pun intended) later in this series.
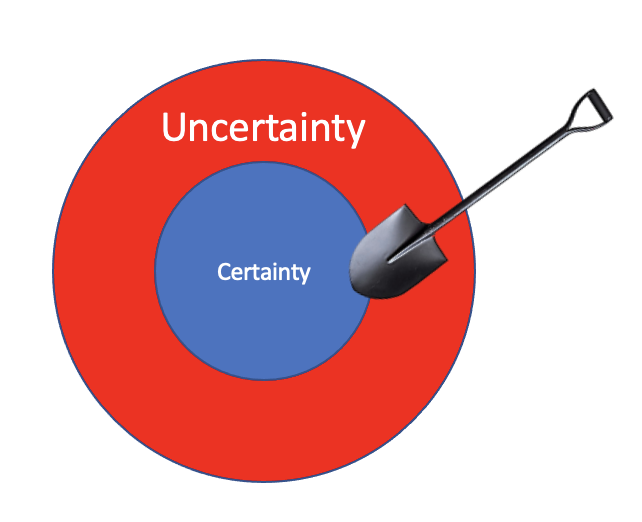
We uncover certainty. We do not “make certain” or maximize certainty, because it suggests we are trying to achieve the impossible total certainty. We only try to minimize uncertainty. The only question remains is when to stop digging. What and when is certain enough?
Variance
PM: “You said it’s going to take you 3 days and it took you 3.5 days! You’ve ruined the entire Sprint Plan!”
Engineer: “But you know, give or take…”
PM: “Give or take? Next time I’m going to need an exact effort measured in minutes!”
Engineer: “Come on.. I can not estimate it so precisely…”
CEO: “You said this feature is going to attract 100k customers and we only got 95k! You’ve ruined the entire Business Plan!”
PM: “But you know, give or take…”
CEO: “Give or take? Next time I’m going to need an exact head count!”
PM: “Come on.. I can not estimate it so precisely…”
If we were to ask an engineer and be answered with “278 minutes of effort”, the probability of it being exactly 278 minutes is almost 0%. Same goes if he’d say 300 minutes. Almost 0%. Same goes for 5 hours because 5 hours is exactly 300 minutes.
Same for the outcome of a Plan built on such Estimations. The odds of such a Plan being accurate is almost 0%. No one to blame but the Plan itself and the Estimation itself, which do not take “give or take” into account. That’s where variance comes in, to correctly give a less uncertain estimation. Let’s examine the normal distribution to see why.
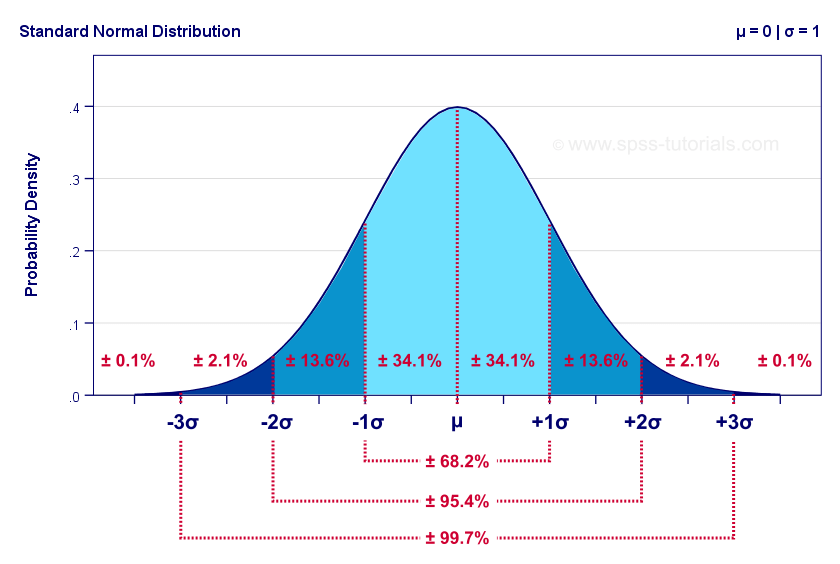
The odds of exactly hitting the mean/average during execution is almost 0%. But when we estimate, it’s what we do. And we do wish to have a margin of error, a “give or take”, a buffer. We just don’t know how.
The diagram above shows that variance creates the buffer we need. Different levels of variances (buffers) have different probabilities (certainties). In statistics, it is called a confidence interval.
When we estimate, we don’t really say “exactly 5 hours”. We do add a buffer and say “5 to 6 hours” in case something goes wrong, and sometimes it does. Naturally, we may never consider the possibility of things going smoothly, and sometimes it does too. Just by saying “4 to 6 hours” would double our odds. But our odds are still uncertain. We do not know whether they are now at 24.1%, 35%, 47.7%, 65.9% or 84%.
In statistics, 95% is certain enough. The above diagram shows that for each distribution exists a variance that gives such certainty (effort is not of normal distribution, more on that later in this series). Minimizing uncertainty is the effort to get to certain enough. We’d learn of how to practically do this later in this series, when we’ll talk about Uncovering Work and Uncovering Effort.
Not all Math
We’ve already learned of many other things that reduce uncertainty as an outcome, even without calculating probabilities. We’ve learned about the importance of having a flow of internal feedback, doing proper validations at the right time, getting external feedback as quickly as possible and understanding feedback. Feedback uncovers and reduces uncertainties of what needs to be done, and why.
We’ve also talked about the importance of the certainty of values, and of fruition, the relationship between timing and value, both of which reduce the uncertainty of the value. We would also later see that dividing our designs and effort to Deliverables and sub-tasks also contributes to it as well.
In this chapter, we spoke of uncertainty of a specific Task. However, a Plan is a collection of Tasks. Reducing the uncertainty of a Plan goes through reducing the uncertainty of each Task independently. And then some more. We’ll see exactly that in the next chapter.