In the previous chapter, we’ve inspected the two-way relationship formed between our application and its data. We’ve done so by slowly taking the data Module away from our application. We’ve started with a simple single file and made our way into multiple files and even considered the option of an application with no data at all.
No matter what we’ve done to ease our troubles and coding, the relationship has stayed the same. The persistent data’s structure must always meet our application’s expectations. And it needs to be maintained and managed throughout their life cycle.
With this relationship solid in our mind, we can now add an application that would manage the data for us. Something called a database.
Storing Data
Very similar to what we’ve seen at Wiser in the previous chapter, DealPly (2014) also had scrapers stored in files that were loaded by our main server application. Their numbers were expected to grow from 1,000 XML files to 5,000, and they eventually did.
These files too were being created manually by people. We needed to track the file’s content to make sure it actually scrapes and brings valuable business results. These files were also our way to measure our employee’s performance, as they were paid by the scraper/file. It was our way to track and validate they do their work well and as expected.
I knew for sure that in its current state, the solution is technically limited. Any query would require a multi file search and crossing it with another data source, which might be technically impossible or non-beneficial for some queries. A lot of future unknown effort, for queries I have no idea what they will be. Furthermore, even if I knew what our tracking needs are, they would Change through time.
Luckily, our XML files were well structured. I migrated them all to MySQL and added the tables with our employee’s data and cross referenced the two by employeeId. I also normalized all the tables, a process that makes sure all future unknown queries would be doable. As of this point, a lot of future coding effort was saved as querying is taken care of by the database.
That allowed us to hire a part time data analyst, a non-engineer who can query the data freely because she only needed to know SQL. And she was so much better than me at it. And unfortunately one day we caught one of our employees with a hand in the cookie jar.
Changing Data
The XML files were discarded but let’s put our finger on what hasn’t changed. Storing data in a database does not change the fact a two-way relationship exists between an application and its data. If the data’s structure would unexpectedly Change, it would break the application and vice-versa. This relationship would still need to be maintained with the likes of backward compatibility, practice versioning, and testing and maintaining contracts.
For the gain of effort saved on the query side, we paid with an initial effort on the indexing side. We had to structure and normalize our data and tables, in advance. The balance between initial effort on indexing/insertion versus future effort on querying is one of the many things that distinguish relational from non-relational databases.
In document based databases, such as MongoDB and DynamoDB, there is less initial effort to make but future queries are limited. Likewise in search engines like ElasticSearch and Solr, where the indexing and querying have a hard coupling unlike in any relational database.
A JOIN operator, which is commonly used in querying, doesn’t always exist out of the box in non-relational databases. And for some it is implemented as a filter operation which easily causes performance or cost issues. One way to overcome this is to prepare the JOINed collection in advance during indexing/insertion. Practically speaking, it would be by nesting multiple documents into one parent document. But, when it will be done, which can be months after we modeled our data, it will require a data migration. And that would entail or pre-requisite a Change to our already running application, a backward compatible one.
As such, it is also a question of how frequently our data is going to Change. Alas this frequency is unknown and impermanent. It is the same challenge any application is dealing with, the unsteadiness of the Change Stream. But we can get a sense of how it would vary.
Data that represents physical entities, is not like data that represents a state of a continuously developed Product with Features. An airplane would not suddenly grow an extra set of wings. Flights will always take-off and land in airports. However, virtual entities such as characters might grow an extra pair of hands out of the bloom, but they would still be connected to one single body. So maybe a semi structure would be more beneficial. But a Product/Feature/Flow that allows a customer to order a flight would be more frequently Changing than an entity, physical or otherwise. And it would be sooner than later.
We’ve actually done a very similar split at the end of the last chapter, with some of these considerations in mind. We had one application that owned the data, and another application that owned a stateless/pure Feature/Flow that had no data. If we’d bring in our principles of mutual exclusivity of Causes and Cohesion of Causes, we can see that the Flights Data in our database will not Change together with Ordering’s business logic, and not at once.
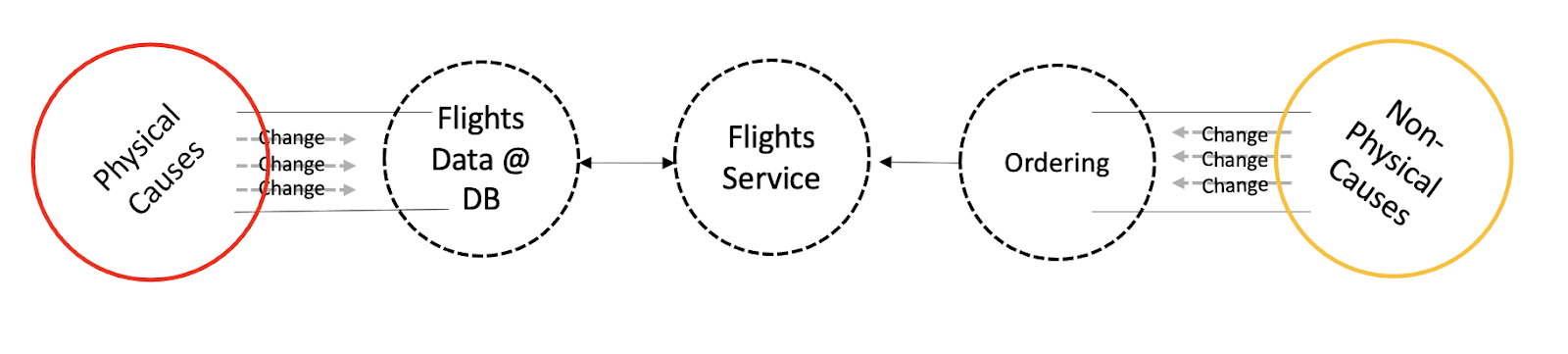
Multilayered Relationship
A database might one day need to scale, just like our stateless applications. But scaling stateful applications requires an extra effort, one beyond the scope of this book. There is sharding and partitioning data, replicating data, consistency, high availability and so many other traits we can learn of in the book Database Internals. Luckily, when we use a ready-made database, someone else already took care of it for us. And if it is a fully managed service, our IaaS provider is also taking care of some of the scaling operations for us.
However, a database is also another application adjacent to our own, both would be sharing a client-server relationship. And both would be mutually exclusive ones, as they would not share any code. It is an additional relationship to our application’s relationship with its data, with all of its gains and troubles. But a database is not the only that can stand between our application and our data. Some of our files might be encapsulated with a HTTP REST API, or any other protocol, such as an Object Storage.
As it is an independent application, a database needs to be updated to support new kinds of queries, performance issues, and bugs. There are always bugs fixed, and bugs would always be added because every Change has the potential to be an Instability. Rolling out a stateful application is far riskier than a non-stateful one. It is never done automatically or without proper warning from your IaaS provider, and might even require a data migration.
Splitting Databases
We’ve talked about how easy it was to query DealPly’s scrapers data, once it was all hosted on the same database. Lifting off the burden of coding queries also means we have something to lose. And it could be an outcome when we decide to split our data between multiple databases. And it might even create more trouble for us than before.
A common scenario is when advanced textual search over our data is needed, let’s say it is for a product search Feature. To do so, we mirror our data from our MySQL to ElasticSearch. Once mirrored, it needs to remain mirrored all the time. We now need to make our data remain consistent between multiple databases.
Consistency is an issue already resolved within a single database, even a distributed one that supports scaling with shards and replicas. When multiple databases are involved, there is no out of the box or effortless solution. It would require a lot of effort from us on the indexing side, and it is quite a big problem in distributed systems and beyond the scope book. You can get a sense of it by reading about distributed transactions, eventual consistency, 3 phase commit and saga patterns.
On the query side, even when the data is perfectly mirrored, once again we’d find ourselves in need to perform cross queries between multiple data sources/bases. The query of “Top 100 products relevant to the term ‘Amazon’ and all of their similar products” is infeasible. It requires a JOIN operation, which ElasticSearch does not support. Textual relevancy is unavailable on MySQL. There may not be a way around it besides coding, hoping that the current data structure in ElasticSearch would be able to support it.
That is under the assumption that all data exists on both databases. Sometimes part of data would be omitted from one of them. It could be due to performance, resource or cost issues. The less data indexed on ElasticSearch the less instances of it we need and the less we pay for it. It could also be due to the single responsibility principle, because in our scenario ElasticSearch is used for product search. It should hold partial data, only the product title and the product ID, which would be used to cross reference it with the rest of the data stored in MySQL.
Service Split
The above problem we’ve created is not limited to splitting the data between multiple databases. In some design patterns, it is common to encapsulate any and all data entities with a RESTful API. Instead of directly querying the database for products, we’d issue an HTTP request to the Product Service. To query for Orders, we’d issue a query to the Orders Service. Same goes for Users.
Let’s presume that we need to send an email notification once an Order is processed. That would require 3 HTTP requests to 3 different Services and cross the information between results. Something that otherwise could have been easily done with a single SQL query. Same goes for our purchase history web page, 3 HTTP requests and crossing results instead of a one SQL query. Supposedly, that’s something GraphQL and GraphQL Federation helps us with, after quite a large initial effort.
And as always, it is also a question of frequency. Creating a “Top 100” report once a year that can be executed offline, is nothing like a continuously ever evolving Product and its Features and creating new queries on a daily basis.
In the last few chapters, where we split away the UI and the Data Modules from our one single application, we’ve done so because it is a technical/practical must. Either because they are physically deployed to other playing fields, or because the task at hand requires it to be. But what about optional splits, to further split our backend and frontend? Not coincidentally, we’ve already also learned how to determine what would make an optional one into a beneficial one, or otherwise. On this, in the next chapter.