In a previous chapter, Mutually Changing: Applicative Physical Boundaries, we had splitted away the UI from our antique web application, into a modern frontend application. We’ve reviewed the consequences of doing so, of a client-server relationship forming between the two. We’ve considered this to be a technical necessity, because practically speaking any modern system consists of a backend and frontend application.
In this chapter, we’re going to review another split that is a technical/practical necessity. This time, we’re going to split away the other end of our backend application, the data. It’s going to persist. By doing so, we’re going to inspect the relationship formed between our application and its data.
One File to Rule them All
No application is persistent unless we make the effort for it. Unless otherwise done, an application loses all of its in-memory data once exited gratefully or when it crashes. For some applications, it can become an obstacle. Most commonly, it would be earlier in their lifecycle, even during their initial design.

Let’s get back to our layered application from the chapter Fragments of Change of the Change Driven Design series. Before rushing in to place our data in a database, which we will do in the next chapter, we’re going to first put our data into files. Because even today, more than 30 years after MS-SQL was first released, not all applications require a database. But more importantly, it will help us to slowly focus on the relationship formed with our data. So let’s start with our very own first file.
During a Rollout / deployment, an application usually requires a restart. Even a stateless one requires to start again at a certain configuration/settings, maybe its previous one. To ensure it, we create a configuration file formatted in JSON, TOML or others. And we also make sure it is placed on the same server with our application, either with an automated or a manual deployment. Once there, every time our application restarts it can load its configuration to its in-memory. It would be surviving a restart. Problem solved, and a two-way relationship had been formed between our application and its configuration file.
One day our Engineers have a Cause to Change the configuration file. He logs into our servers and by mistake he creates a typo in the JSON file, makes a Change to a key’s name. Or he may have accidentally Changed the file’s encoding on his local workstation, making it unreadable to our Linux servers. It might be the other way around. Our engineer might Change the application’s code that reads the configuration file, and add a typo there.
Once done, our application would no longer launch upon restart. Even worse, it might start to behave unexpectedly. It might treat the key’s value as null/undefined or fallback to long forgotten hardcoded defaults.
[Practically speaking, environment variables should be considered when it comes to runtime configurations. Some of them are also Secrets. It will make the configurations’ file deployment somewhat redundant as an application can just be simply restarted.]
It might help to track Changes to our file, and configuration should be managed, logged and tracked anyhow. Let’s put it in the same git repository as our code. A code review might catch it and prevent some Instabilities, but not all. It would not change a very basic underlying fact.
The persistent data’s structure must always meet our application’s expectations, and vice-versa. In some ways, this two-way relationship is similar to the one between two intersecting applications. An application and its files can be Changed independently and can be deployed independently. And it is not always possible for them to Change at once. As such, this relationship needs to be maintained with backward compatibility, practice versioning and test and maintain contracts.
Data Change Stream
If we were to inspect our action of split via the Change Stream model, we would see how it forced a split onto the Stream, resulting in two independent Directions of Change.
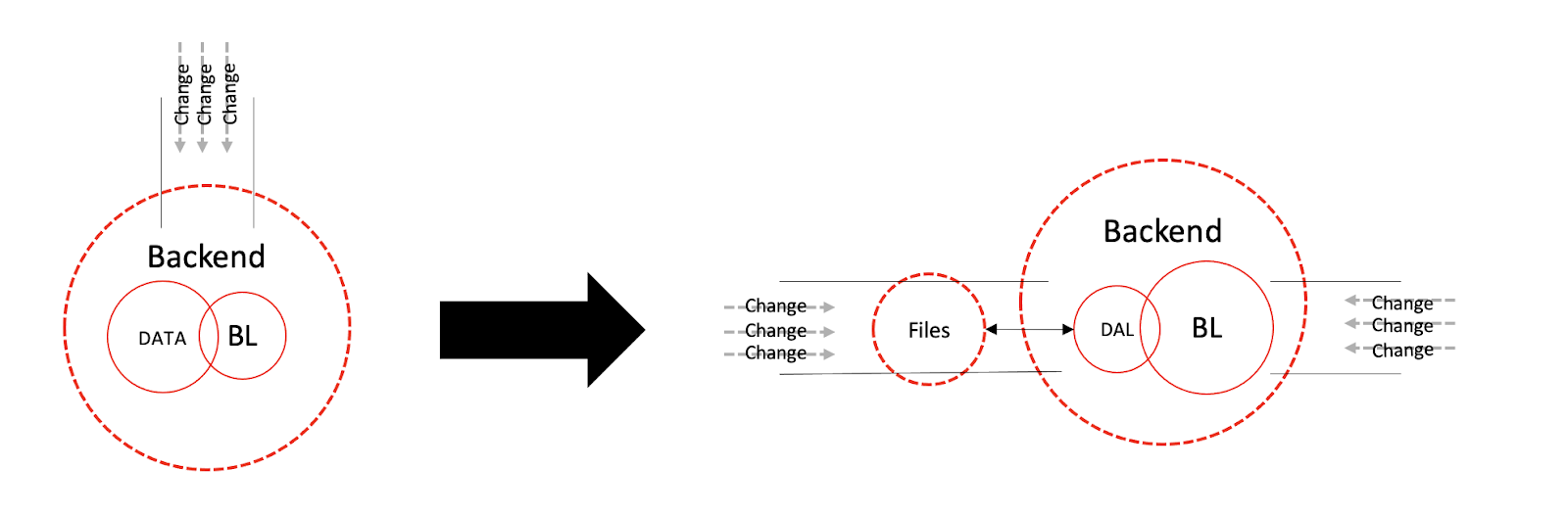
Once data is persisted outside our application, it has its own Causes to Change. It would entail our application having a 3rd party dependency with data. For our simple configuration file, it would be required to encapsulate the configuration file with a Module. It would allow us to make two small Changes instead of one big Change, which would help us maintain backward compatibility.
At least theoretically, because to maintain such a complicated relationship just for a mere configuration file might be non-beneficial. But it may become beneficial and practical, if that one file held user information of 100 customers. And it would be the exact same relationship when it would be stored in multiple files, a database or in another application. Which is exactly what we would be doing next.
Filing Cabinet
At Wiser (2016) we were working on an application that does large scale web scraping, something very similar to ParseHub. It allowed our people over at Customer Success to tailor a very specific scraping flow for our customers, through a dedicated UI without any assistance of an engineer.
Once tailored it had been stored as a JSON file in GitHub, for version history and tracking. Just like with a single file, our application had a two-way relationship to be kept aligned with these flow files. But unlike it, there wasn’t just one file but hundreds of them.
One day one of our engineers had a Cause to Change the relationship, from the application’s Direction. In order to support a new feature, all of our JSON files needed to be transformed in order to Change all the flows at once. It’s not like we couldn’t tell the Customer Success team to do it, to go and manually Change one file after the other through the UI. But it would have been a waste of their time and very error prone.
In order to get the Change done, we coded a script that would go over one file after the other, transform it from one structure to another, mutate the data stored in the files and verify the Change did not break anything. It is a process known as data migration, a process that requires coding.
But before doing so, we needed to know how many files are expected to be affected. As not all flows were stored in one big file, we couldn’t just open it with NotePad++ and hit Ctrl+F to get a simple text search done. Because there were hundreds of files, we needed to do a multi file search. For an engineer who is practiced in piping on Linux, it might be short effort to create a one liner in his console.
Unfortunately, the files stored only the scraping flows and not the entire data we had. If we wanted to know how many files each person in Customer Success had Changed in the last month, we’d have to query GitHub where it was stored. With the GitHub CLI and some piping we figured it out. The command was reusable by Customer Success, but it was an engineer’s effort to get it done for the first time.
But, if we wanted to cross information between our two data stores, the files and GitHub, that would have been a non-trivial task, something not easily done with piping and would require a few days of coding a script.
Applicative Purity
In the chapter of Mutually Changing: Applicative Physical Boundaries and its followup on Rolling out Changes: Crossing Time Boundaries, we talked about distribution of Modules between multiple applications. Data persistence has a little something to do with it as well. Let’s consider the following split to two applications:
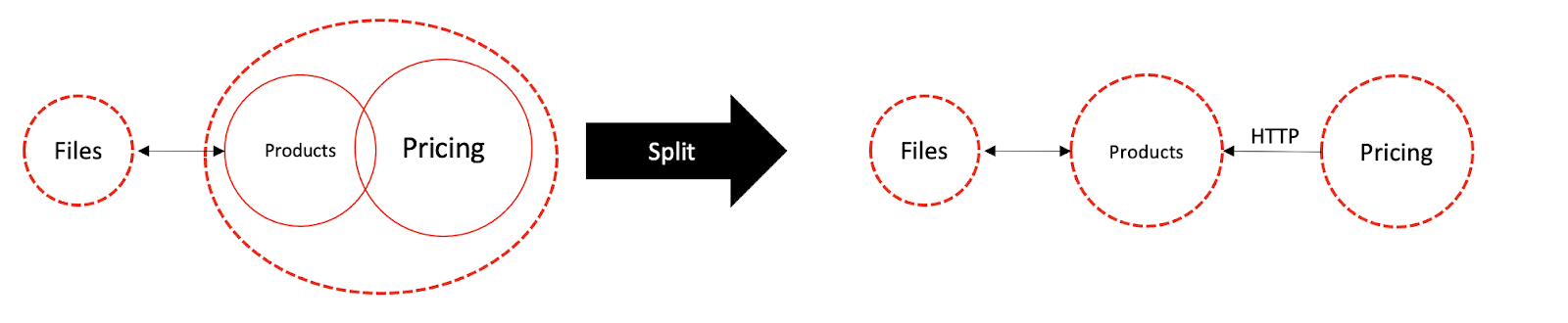
After the split, Products still have files where the data is stored and persisted. We should notice that while the Products application is stateless and sessionless, its files aren’t. We can say its state is stored in the files. If we’d need to scale up Products and launch another instance of it on another server, we’d also need to scale up the files. To copy and sync them between the two. It is no different than scaling the one application we had. Only our one application had more than one reason to scale.
However, the Pricing application now has no files. It has no data at all. It is also a stateless application but also a pure function, because it is a Feature/Flow. If we’d need to scale it up, it would be much easier and fine tuned than Products because there are no files to scale.
When it would need the price data, Pricing would use its client-server relationship and query Products via the network. Or a third application would query Products for the price data, which would be an input to Pricing.
Luckily for us, having a database eases scaling up and syncing files, it already does that for us. But scaling a database is much harder to do than scaling an application with no data at all. And a database also saves us the trouble of coding querying scripts and some of the data migrations. And putting the data in our databases, changes nothing of the two-way relationship between it and our applications. On this, in the next chapter.