In the previous chapter, we had split our first application into two independent ones. As we are taking things slowly, we’ve done it to a single application that actually had two mutually exclusive applications within it. Very convenient for us.
We’ve seen that the two remain in the same Change Stream, and share the team’s Throughput. We’ve seen how it can benefit our costs, scaling, reliability and uptime. We’ve seen how it slows down the evolutionary processes towards a Legacy, a Refactor and a Bundle. It is still left to be seen how it affects the one towards a Monolith.
We’ve finished the chapter with a new technical requirement to allow our applications to be split, and that is for them to be independently deployed. In this chapter, we’re going to see how splitting deployments affects our development workflow.
Deployment Dependency
Let’s presume our team consists of two engineers, both working on the same application. One is making a Change to one group of Modules, the second makes a Change to another group. Coincidently, they were both done coding exactly at the same time.
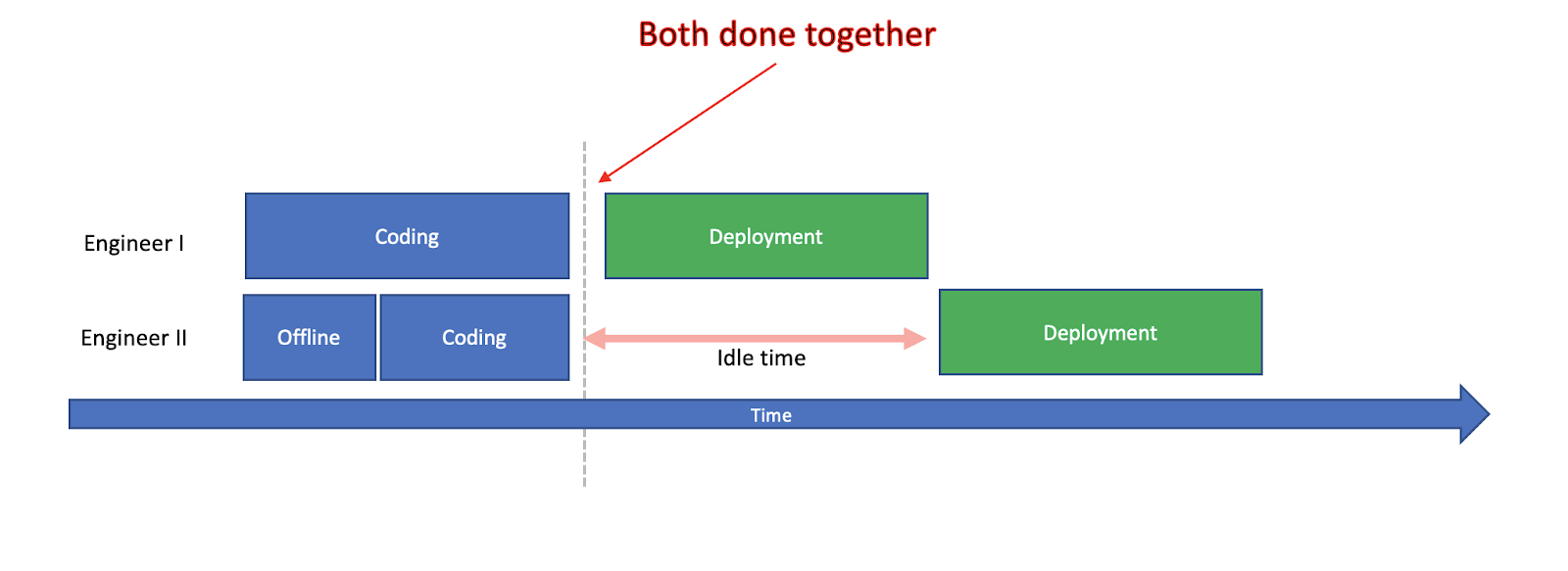
We can only deploy one Change at a time. Two deployments running concurrently can easily intersect with one another, ending with multiple servers running multiple versions. As deployments must be executed one after the other, the second deployment would start only after the first ends successfully.
Meanwhile, one engineer would have time on his hands to stare at the screen, or grab some coffee. An idle time. He will patiently wait for his colleague’s deployment to finish. When an idle item occurs, it’s an Inefficiency as our engineer could have better spent his time on coding. But there is a big difference between it happening once a month or a few times a day. And for sure it is not a coincidence.
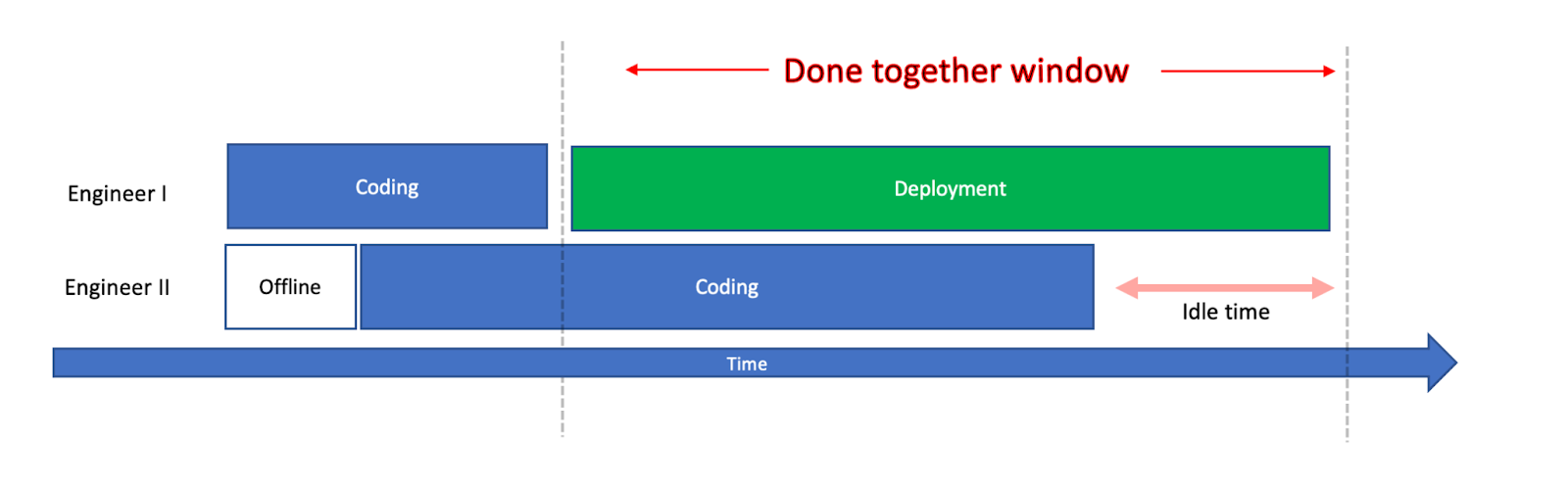
The longer the deployment duration is, the more likely an Inefficiency would occur. To grasp it, let’s put ourselves exactly when the first deployment started. It is now running in the background, it already has happened. If the deployment takes 1 hour, the odds of someone initiating another deployment is more likely than when a deployment takes 10 minutes – as the “done together window” is longer. And these Inefficiencies accumulate.
Upstream Pressure
In Throughput of Change, we’ve seen that deployment is only a single step within our development workflow. We’ve seen that removing a Bottleneck entails an increase to our Throughput. We’ve seen how Throughput eases Back Pressure on the one step prior to the Bottleneck. An increase to Throughput has one more effect, on the one step after the Bottleneck. Let’s see how this relates to our deployment.
Before an engineer deploys, he codes. He is making a Change. And he can do it much better and faster by practicing, which would increase his own Throughput. We also know that hiring dramatically increases our engineer team’s Throughput in a matter of weeks.
The higher our engineering team’s Throughput is, the higher the frequency of them executing deployments. And as deployments can only be done sequentially, a race condition between our engineers would occur. They would more frequently be waiting for each other’s deployments to finish.
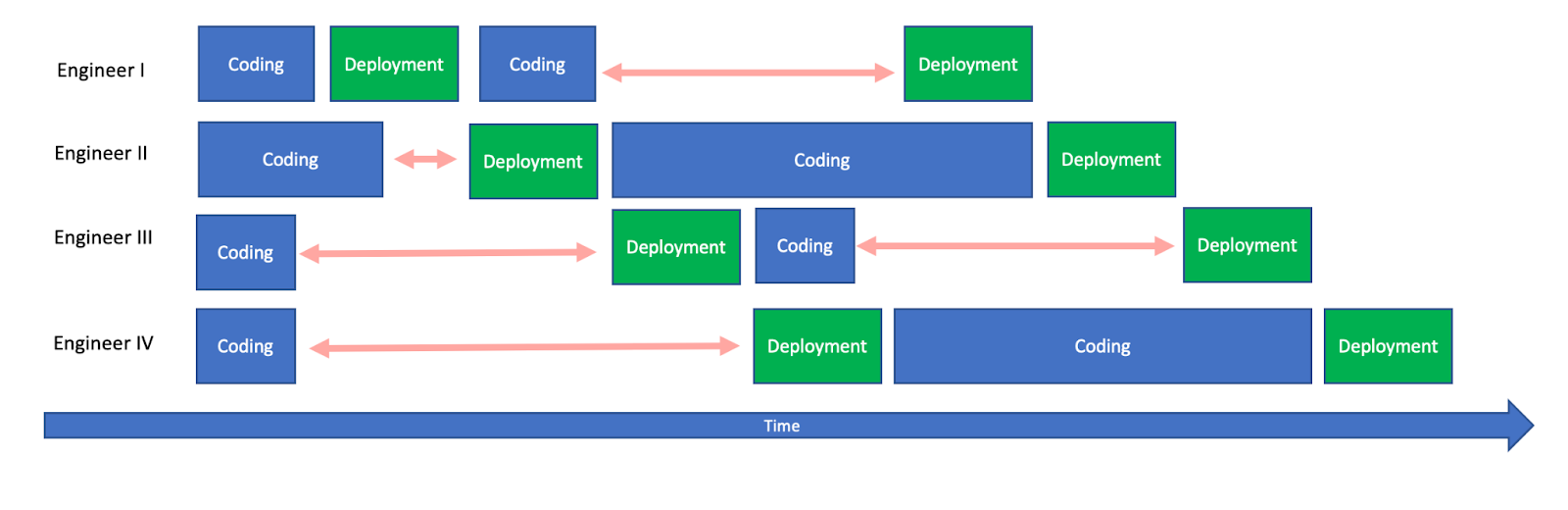
And as we’ve just seen, the longer our deployment duration is the more likely it would occur and the more Inefficiency each engineer would have.
The increased Throughput of our engineers is creating an Upstream Pressure on our deployment. The longer our deployment duration is, the less it can withstand that pressure. With both a long enough “done together window” and enough Throughput, this would become a Bottleneck in our development workflow. It would result in a Back Pressure to our engineers, which might cause them to Bundle changes together to avoid these long deployments.

Upstream and Back Pressure is not limited to coding and deployment. It can happen between any two steps in our development workflow. Exactly what makes removing Bottlenecks a continuous effort.
Splitting Deployments
Let’s presume our application is still conveniently easy to decompose or designed for Changeability. By splitting it into two applications, we can code and deploy them both in parallel.
At the very least, each application would be deployed to less servers thus our Continuous Deployment (CD) pipeline’s duration will be shortened. If our workflow also includes a Continuous Integration (CI) pipeline, we shortened its duration too, because each application would have less code to build and test. As a result, each engineer’s idle time and Inefficiency would be decreased. And as the “done together window” had shortened, the likelihood of it happening would be decreased too.
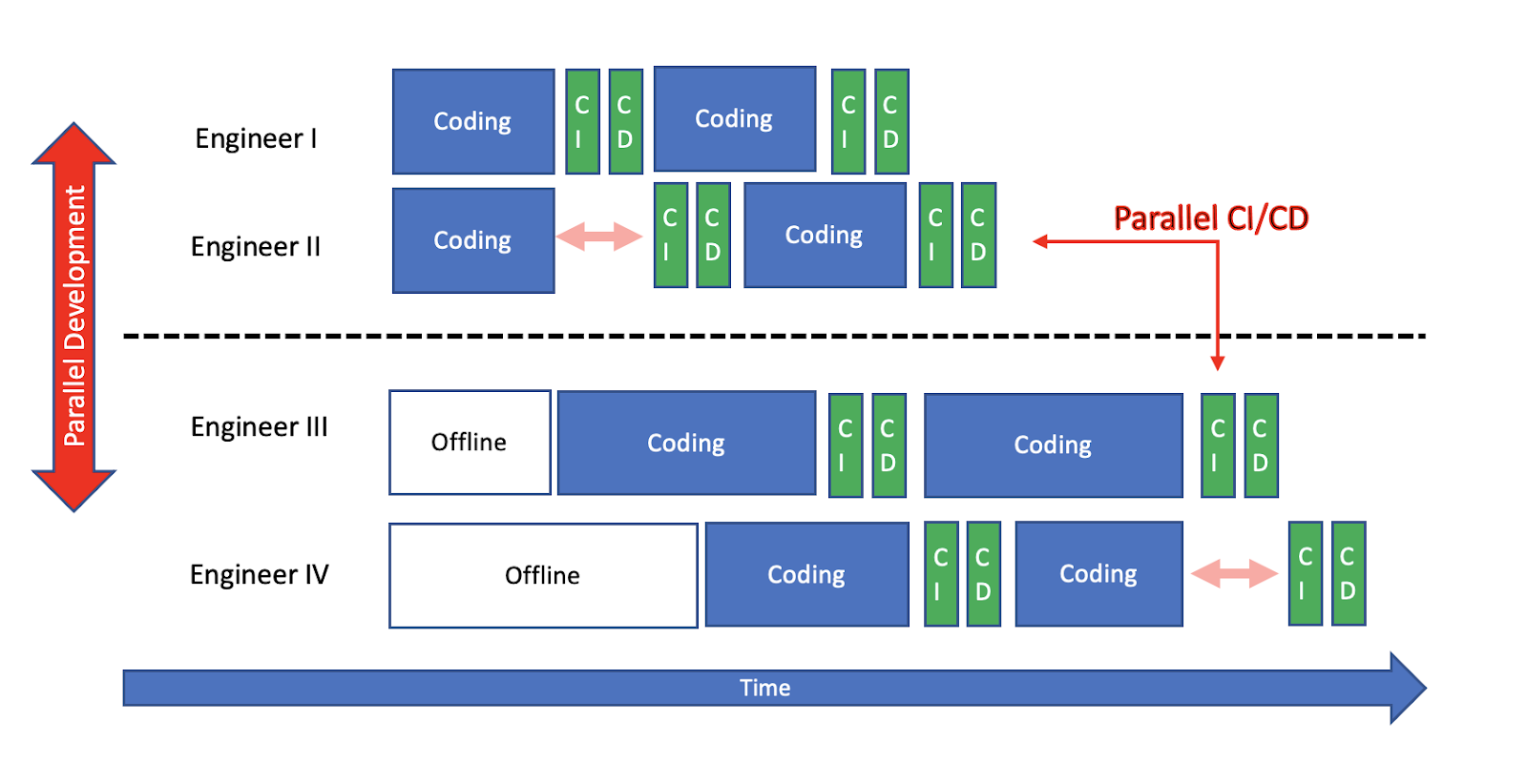
We had removed the Bottleneck, but maybe created two potential future ones. As each application continues to grow, its CI/CD duration would increase little by little. As we continue to increase our team’s Throughput, one day eventually we’d have enough Throughput and duration would be long enough to form a Bottleneck in our development workflow once again.
That does not mean we would need to split our applications again and again forever. Shortening the “done together window” by optimizing and shortening our CI and CD’s durations is always an option on the table. It may be even easier to do.
Role Model
Splitting an application is not a prerequisite to splitting a deployment. There are other techniques that would ease the deployment Bottleneck without splitting, maybe enough that there won’t be a Back Pressure on our engineers. At least for a while. One such technique is having our one single application perform multiple different roles, during run time.
Let’s have a look at ElasticSearch. It is one big and extremely complicated single application. When setting up an ElasticSearch cluster, each server node can be assigned with multiple roles. Some servers would only do data ingestion, some servers would only store data. As long as the HTTP API contract is maintained between them, each role can be deployed independently.
If an engineer had made a Change in the Direction of the data ingestion Module, a deployment that updates only ingestion servers can be triggered. Same goes for the data store servers. Practically speaking, even only a subset of tests can be executed as well (not sure how to split the build). Although it can not be developed in parallel as with two independent applications, a single ones’ CI and CD duration will be shortened, making our single application withstand enough Throughput for a whole while longer.
It may not be so feasible for a web application, but it is for a web service. If it is carefully designed, it can be made to have different roles. For example, a single application can handle multiple RESTful resources such as Customers and Orders. With some support from our load balancer, we can set up path based routing. All calls to /customers/ would be routed to Server A, all calls to /orders/ would be routed to Server B. Both servers would run the same application, only A would have the role of Customers and B would have the role of Orders.
If our engineers wish to make a Change to Customers, they would code files under the /customers Module folder. If they’d wish to make a Change to Orders, they would code files under /orders Module folder. If they’d need to Change them both together, he’d code files under /common/ Module folder. Our CI/CD would need to be set to trigger a specific pipeline per file path, each deploying to a specific set of servers.
One amazing outcome is that we’ve gained the same benefits to our costs, scaling, reliability and uptime [ref to Safety First] even without splitting our application. It makes me wonder if this could be a first step when merging applications.
Removing a Bottleneck in our coding creates an Upstream Pressure of Throughput and turns our deployment into a Bottleneck. Can something similar happen with our application? Would it turn to a Bottleneck of its own? On this, in the next chapter.