In the previous chapter, we’ve seen two consequences of increasing our Throughput: easing of a Back Pressure in our development workflow, and an Upstream Pressure created in it. We’ve inspected these effects on the relationship between our engineers and our deployments. Once our engineers gain enough Throughput, by better practicing or hiring, it turns our deployment into a Bottleneck which decreases our team’s Throughput.
We’ve seen that shortening the CI/CD duration eases this deployment Bottleneck. One way was to optimize it. Another was specifically for a carefully designed application, where CI/CD pipelines can be split into multiple independent ones that run for shorter durations. And for many reasons and for many scenarios, it may be quite enough at least for a while.
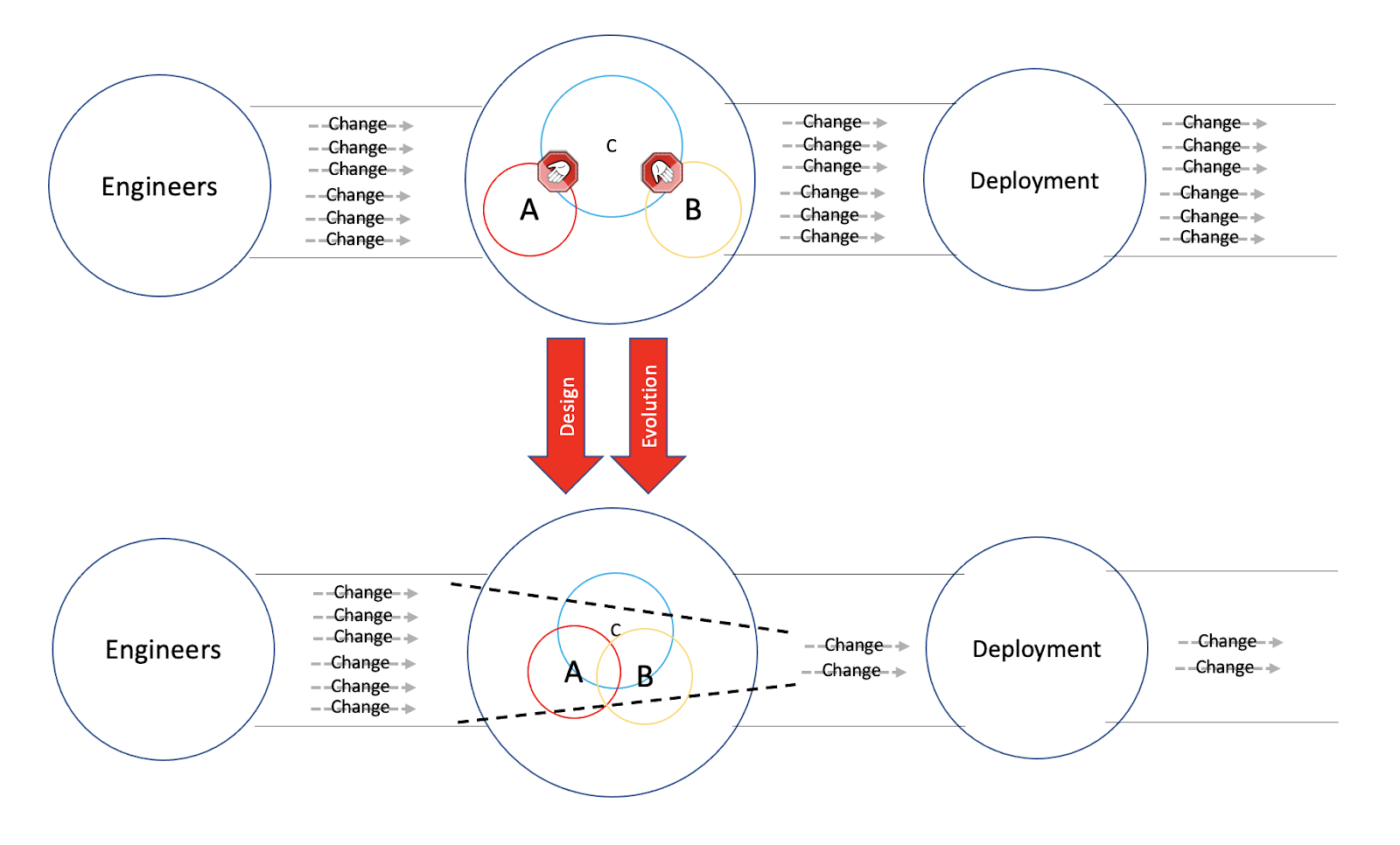
Lastly we’ve seen a way to entirely remove the Bottleneck, by splitting the application into two. It would allow us not only to deploy each independently, but to develop each one independently. Once again with enough Throughput and enough time given, a Bottleneck might be eventually created for at least one of them.
In this chapter, we’re going to see something similar. As the relationship between Bottlenecks and Throughput exists throughout our development workflow, it also exists between the engineers and their applications.
Acceleration
In the previous chapters, we’ve seen that our very own engineers can increase their very own Throughout just by gaining experience and bettering their practices. We’ve seen that by removing and easing Bottlenecks in our deployment, we increase our engineer’s Throughput. And of course, hiring additional engineers can potentially multiply our Throughput within weeks. We have to wonder, where would all this Throughput our engineering team gain, where would it end up being absorbed?
In the previous series of Change Driven Design, we’ve seen the relationship formed between an engineer and an application. From an application’s point of view, it is being hit with a Stream of Changes made by an engineer, due to a Cause. We’ve also seen that this Stream of Changes is unsteady, as the distribution and frequency of Change is impermanent.
This frequency of Change is our engineering team’s Throughput. The higher our Throughput is the more coding we do, and the more our application is being hit with Changes. And as Change is what fuels our application’s evolutionary processes, the higher the Throughput the faster they are.
In this chapter, we are specifically concerned about our application’s evolution towards a Monolith. The higher our Throughput is, the faster our application grows. The faster it grows, little by little it is harder and harder, and it takes longer and longer for our engineer to code. Our Throughput decreases. Exactly why we said these evolutionary processes are erosive.
Given enough time and Throughput, our application would become a Bottleneck for our engineers. As with each of these processes, it is a question of how much time is given. We may not be so concerned if our increase in Throughput shortened it from 5 years to become a Monolith/Bottleneck in 3 years. But if we shortened it to one year only, we should be at least aware of it.
Throughput alone does not determine it. It is also the application’s design that determines how it would evolve. Throughput does determine how fast it would be, but it is the application’s design that would determine at what rate, the acceleration rate of it becoming a Monolith and a Bottleneck. And it depends on the design choices we made many years before, those we also take every day, whether we were aware of it or not.
In the entire series of Change Driven Design we’ve learned how to design applications in a way that slows down these evolutionary processes. For exactly this reason, to postpone our applications from becoming a Bottleneck, at least as much as we can for as long as we can. We’ve learned to be agnostic to the unsteadiness of the Change Stream. To set and discover Directions of Change, to find mutual exclusivities, understanding what products are and many other methods. To make our applications able to withstand future increases in Throughput that would eventually happen.
Unfortunately, this Bottleneck would form up at exactly the wrong time, when the company needs to enter its growth phase to fulfill its value and promises. Because in order to do so, we hire additional engineers which increases our Throughput.
To ease or remove the Bottleneck formed is to refactor our application. As such, its success criteria is whether we were able to increase our Throughput. A process otherwise known as regaining or maintaining our Velocity.
But, supposedly there is another way to decrease the Throughput an application is being hit with. To split it into two.
Splitting Throughput
If we were to split our application into two, each would have its own independent evolutionary processes. Furthermore, each application would evolve slower than the two combined. It is the result of splitting the Throughput between our applications. A portion of it would be hitting one application and it alone, the other portion of it is hitting the second application and it alone.
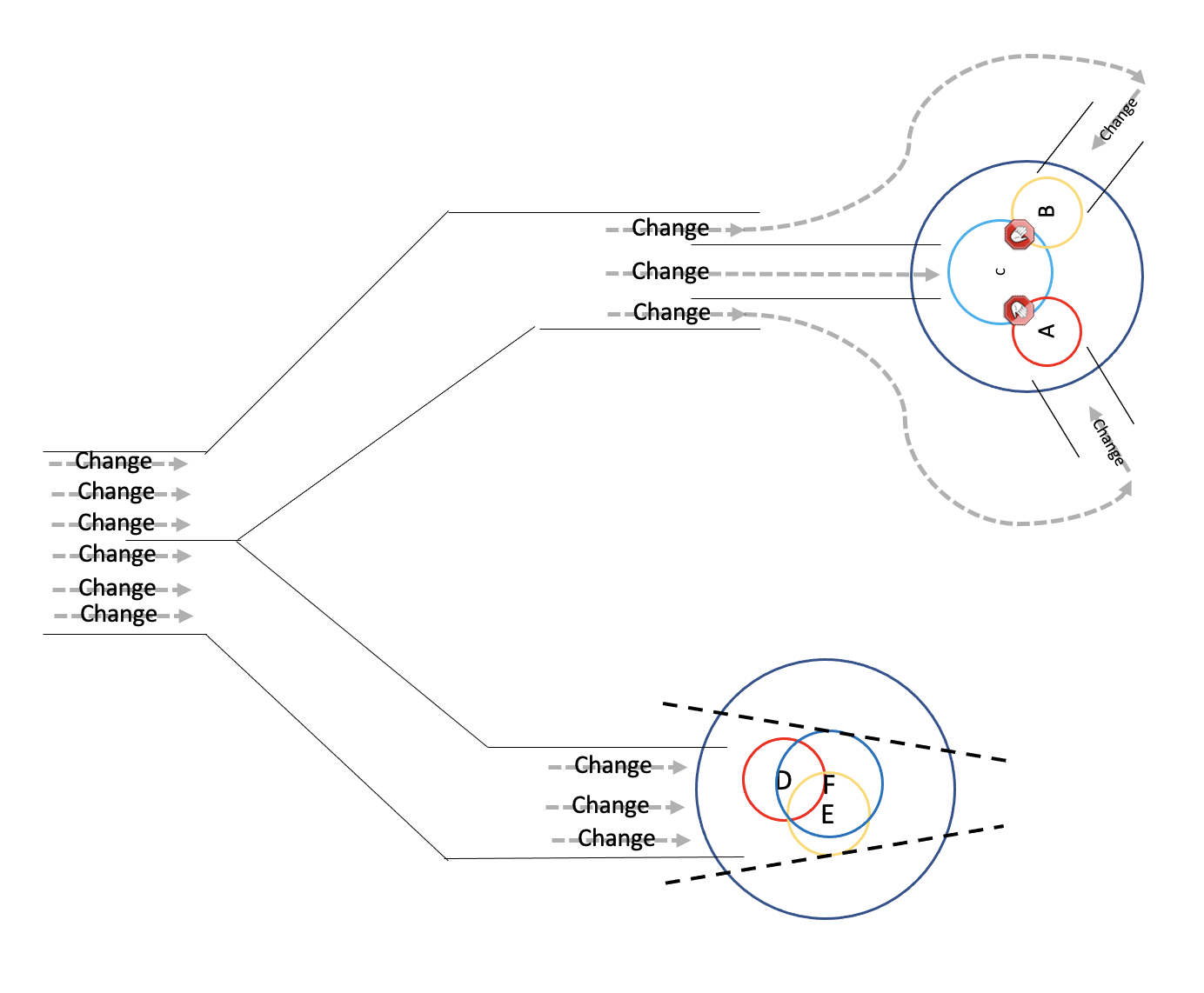
Just like we can not know if an increase to Throughput would shorten the evolution from 5 to 3 or to 1, we can not know if a decrease in Throughput would postpone it to 1, to 3 or to 5 years. It would still be Throughput meeting an application’s design, which would still determine its acceleration rate to a Monolith. An application that was poorly designed, would still evolve at a faster rate than an application that has been properly designed to withstand an increase in Throughput. But until the new Bottleneck would form up, we had indeed removed one. At least for a while.
Any increase in Throughput would be hitting our applications. Whether it was because this Bottleneck was removed or others throughout the development workflow. Whether it was bettering our practice or hiring. Once again as always, given enough Throughout and enough time, each application on its own would eventually become a Bottleneck.
Danger of Ease
It can be dangerous to presume in advance that a split guarantees an application would not become a Monolith/Bottleneck or it would be postponed enough. It might lead us to consider design less seriously, or even completely letting go and forgetting its importance. We’ve just seen how and when design determines the acceleration rate. Without one we will just skyrocket the acceleration rate of the evolutionary processes. And as we increase our Throughput, they will become Bottlenecks sooner than we ever anticipated.
It is something we experienced at RapidAPI (2021-2021). Many years before I joined the company, it seems like past engineers had correctly followed through with a domain driven design, and had an application per domain. Indeed that helped the architecture match the organizational structure, and in turn removed some Bottlenecks and increased the various team’s Throughputs.
Years later, I could have seen how each application evolved at a different rate in correlation to how they were designed. Some had no design to begin with. Some designs were being neglected, because it was never the right time to preserve or refactor it. Some were really well designed, but just at one point could no longer withstand an increase in Throughput and different actions were needed such as containment and isolation. Later this series, we’ll be reviewing those in order to determine what makes a split into a beneficial one.
In these last few chapters, we’ve been removing Bottlenecks by splitting applications. We’ve done so in order to see its effects on our development workflow, and as a consequence we’ve actually learned a lot about Bottlenecks and Throughputs. But, we’ve done all of the above under the assumption that a split would be made to two applications that share no relationship. In the next few chapters, we’ll see how it gets more and more complicated once a relationship between the two exists.