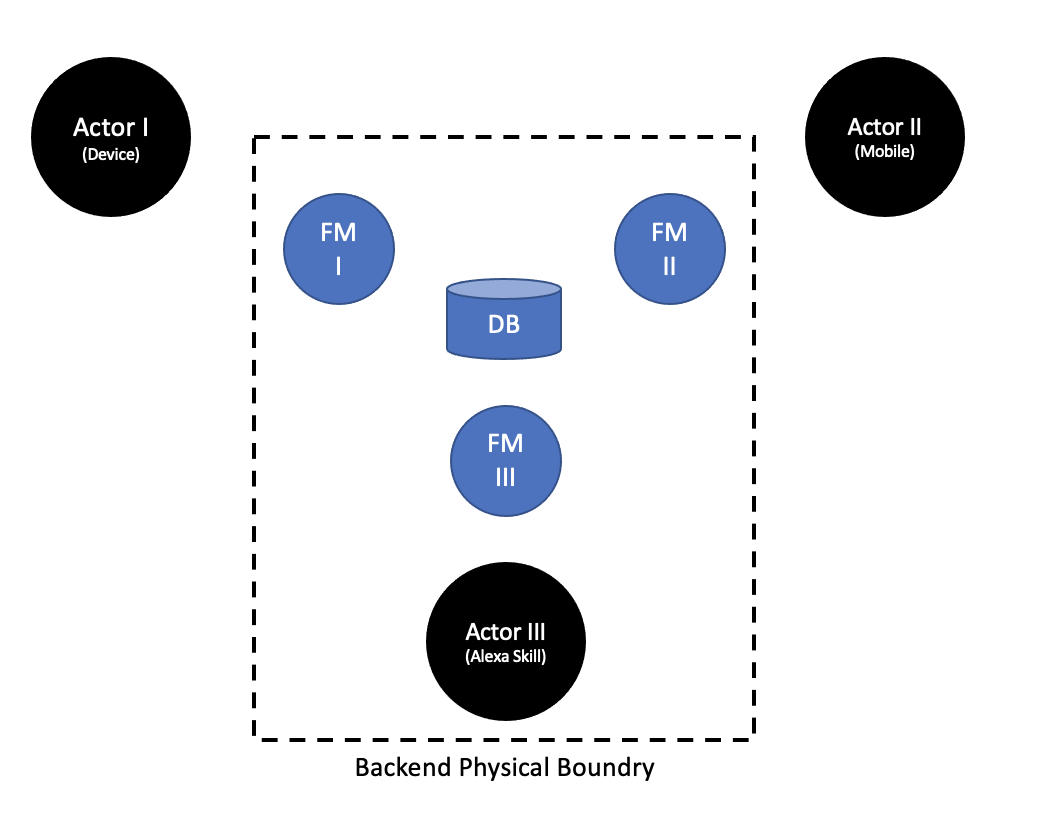
In the previous chapter, we’ve taken a first step in redesigning our backend applications. We’ve taken the Alexa Skill, a customer-facing Actor, and splitted it away to its own independent application. Just like all other Actors, our physical device and our mobile application.
Afterwards, we split away Food Management from our one big Monolith, as it is a closed set of independent User Journeys. Alas, it still servers three mutually exclusive Actors, each one a Source of Change of its own to the backend application. At this current state, an Instability in our backend has the potential to bring down all of our three Actors together.
We’ve encountered three main problems in our design:
- All Actors are bundled together via our backend Food Management application.
- All Actors are bundled together via the backend’s dependency on its database.
- Our Food Management application is an ever Changing product. It would eventually evolve into a Monolith and would never be as Reliable as a frozen application.
In this chapter, we’re going to apply further actions on our design. To dive deeper into the root causes of them and try to overcome the problems discovered. And to fail doing so.
Disperse
If our Food Management backend application serves three mutually exclusive Actors, it would make sense for the first action to split it into three applications. One application per actor. But as our data of Food Inventory is shared between all User Journeys, we’d still be persisting it in one database. For the time being.
Through an operational perspective, we’ve gained a lot by splitting to three mutually exclusive backend applications. Each application will scale up and down according to the incoming traffic solely from one Actor, as such it would have the potential to scale more efficiently and correlative with each customer’s usage. It would also result that a surge in usage from one Actor/customer, would have no direct effect on another. A more Reliable experience and design. However, we can already see the indirect effect through the shared database still exists.
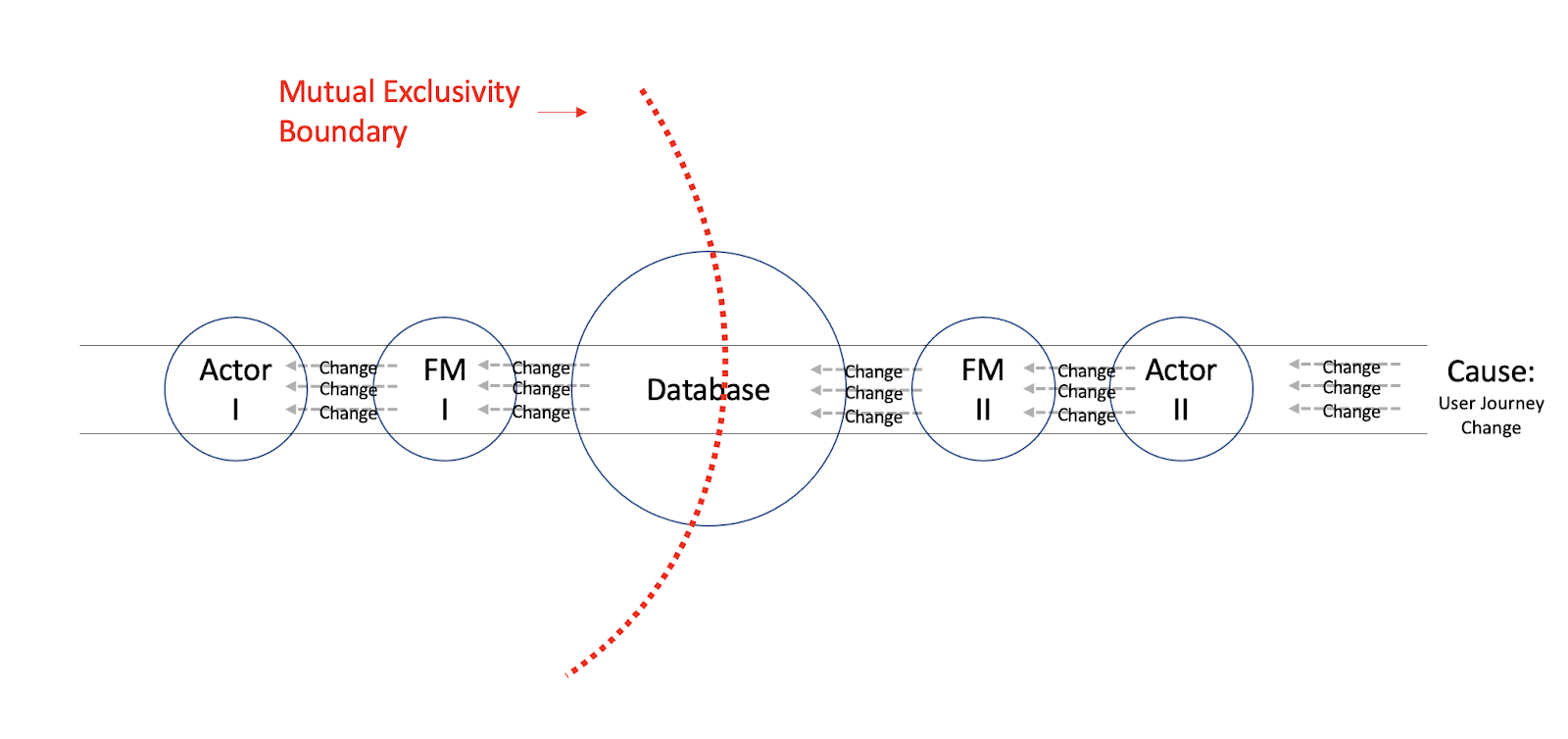
Through a Change perspective, we no longer have one application with four mutually exclusive Sources of Change. Instead, each of our three applications would have just two. It’s Actor and it’s database.
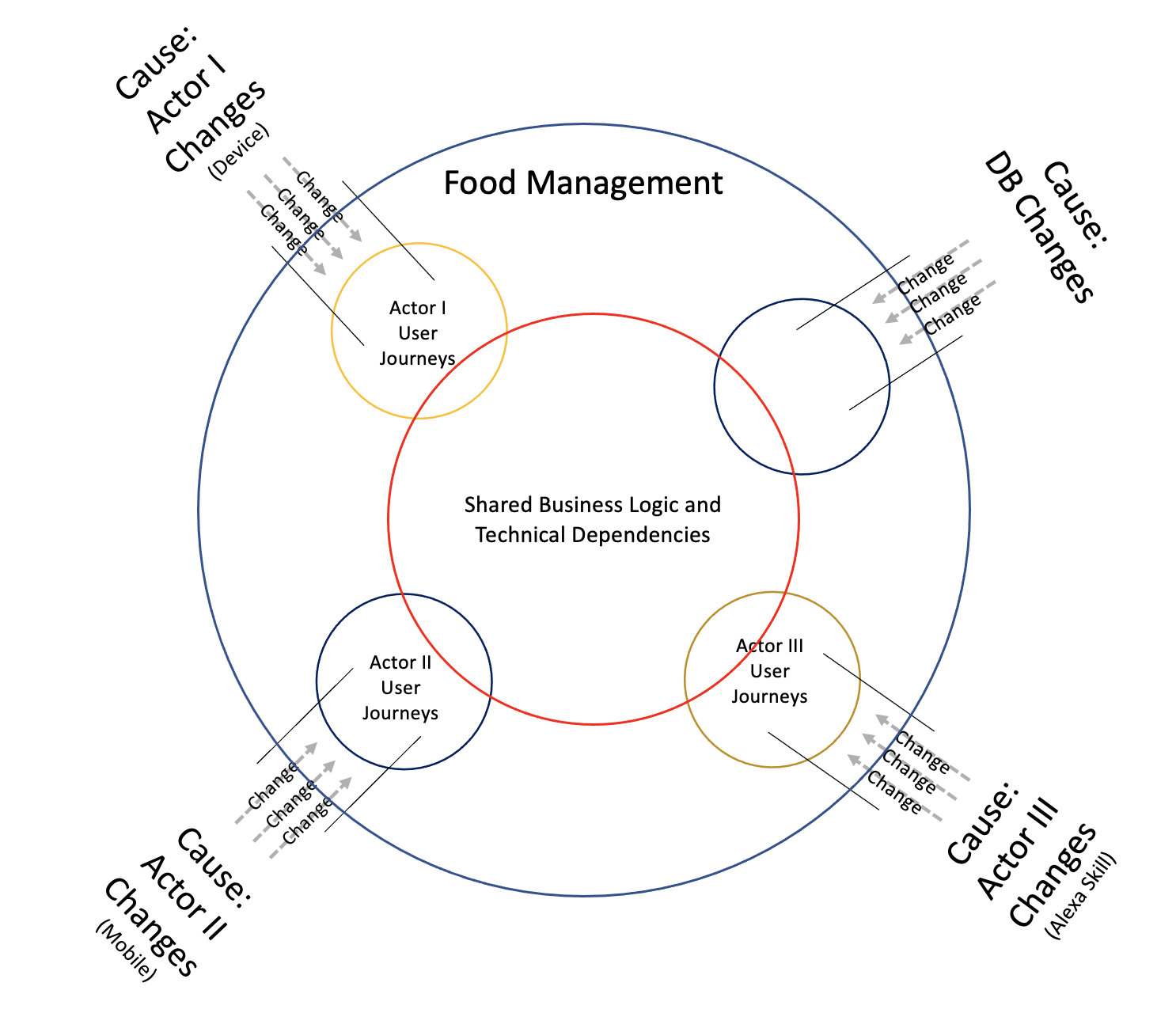
Above: One single Food Management application. Four Sources of Change.
Below: One Actor’s inexact copy of Food Management, Two Sources of Changes.
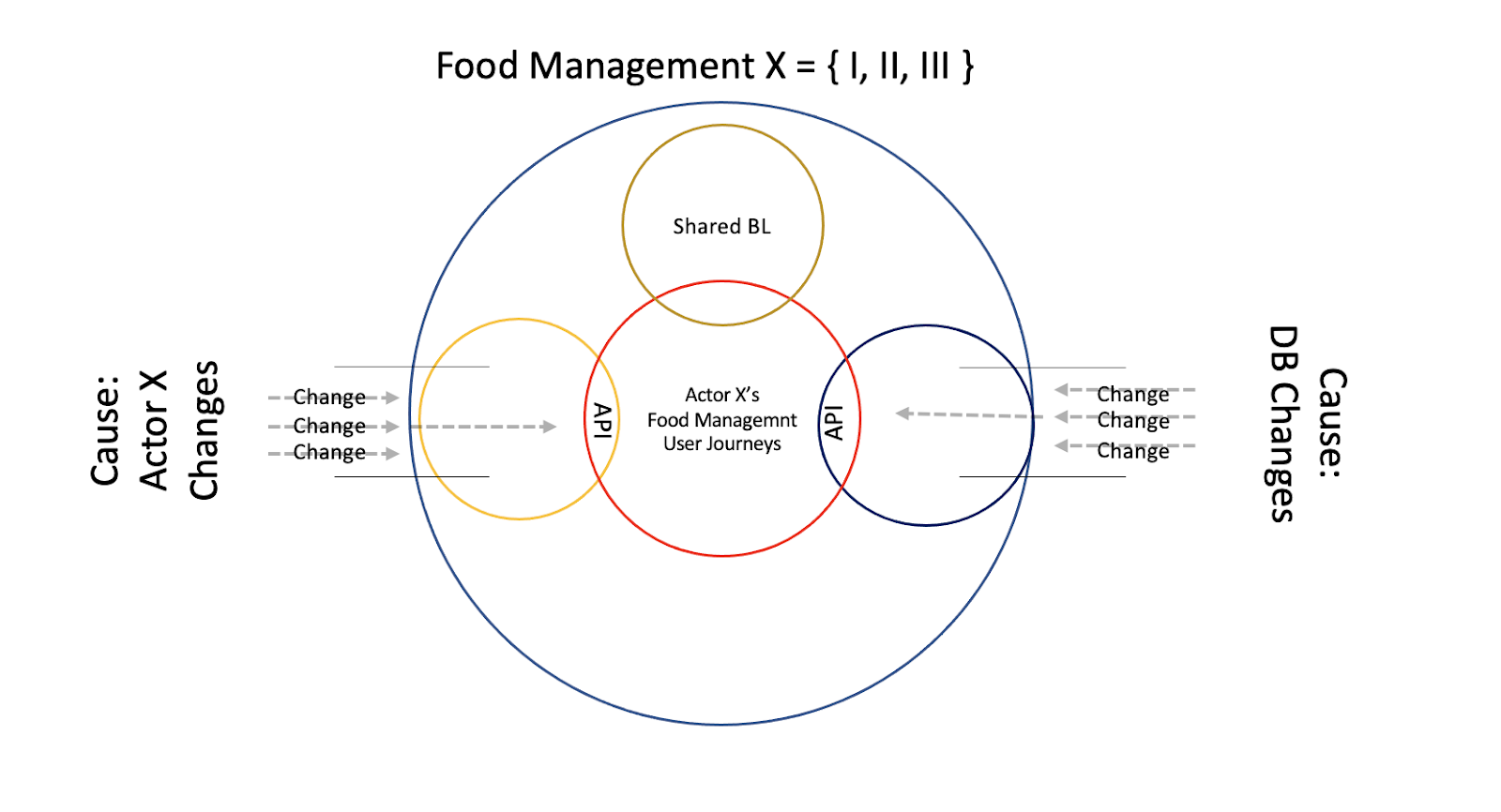
We can check whether the split was an eventually beneficial one. We already have a method to measure that, by examining the penalties of an optional split. We need to consider the Cause, the frequency and the ability to Change all the three backend applications together. To make sure it indeed does better match the Change Stream.
When a Cause rises to Change all three Actors together, we’d have the Shared BL Module. It would be an external package used by all three of our backend applications, within them. The package’s Rollout would be an easy and quick one, as all of them are hosted on our servers. Change will be in effect within minutes, if everyone together gets their hands on it. It is technically possible to do so, but do we want to?
Together Apart
When it comes to frequency, let’s recall each Actor is its own independent product with its own independent User Journeys. Both really shouldn’t Change together. It is not guaranteed for the same Behavioral Change to be a beneficial one for all of our three Actors. Considering the product experience may be hurt, we better avoid doing so and gradually improve the customer’s experience with only one Actor after the other.
Lest we forget, our Actors themselves can not Change at once. Each has its own gradual Rollout, the one for the physical device may be measured in months. If they do not Change together, no reason for their backend correspondent to Change together.
As it is barely possible or needed at all, the frequency of all of our backend applications to Change together is extremely low. We can easily predict there would barely be any penalties paid. It would be a beneficial split.
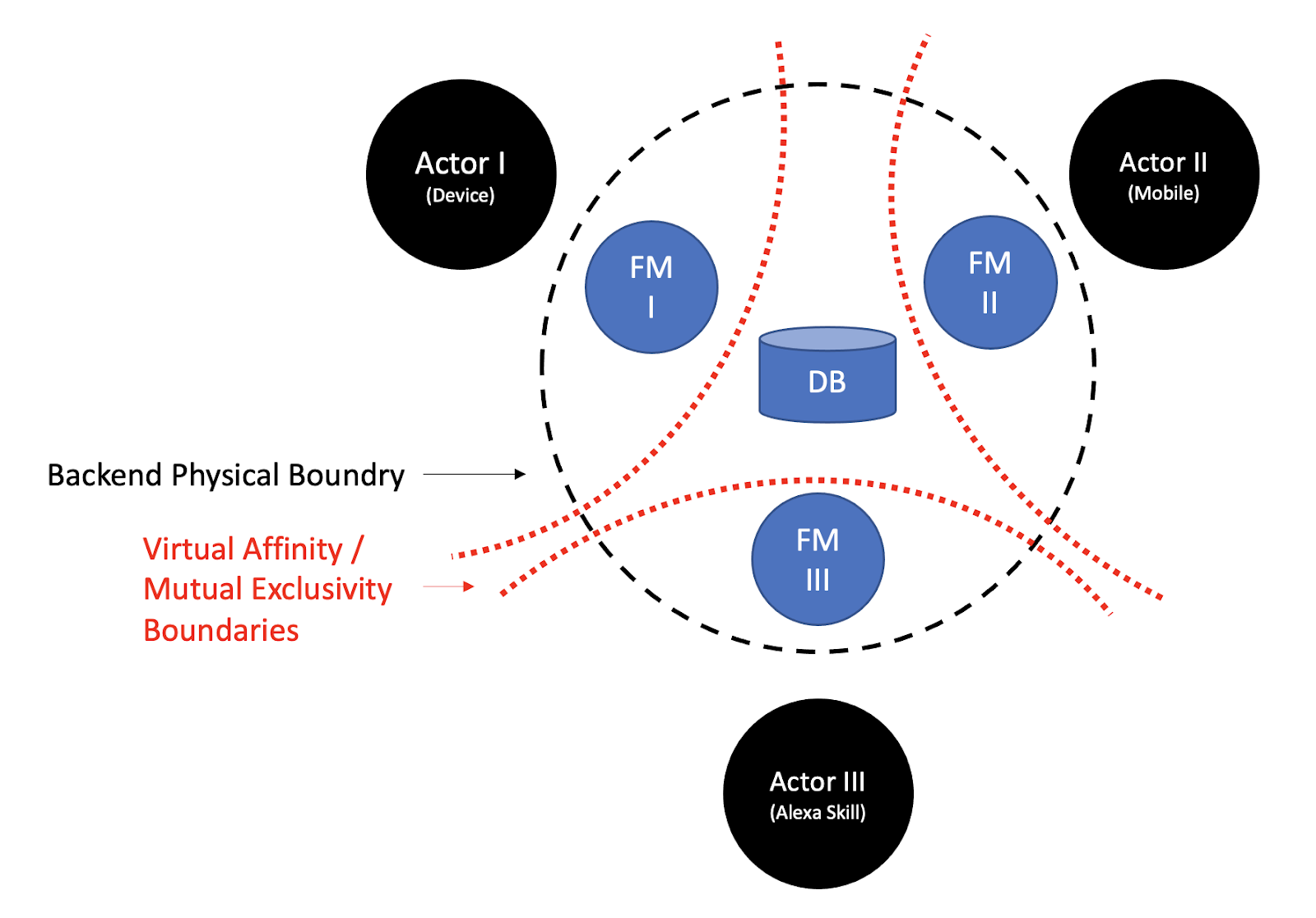
Splitting our Food Management application per Actor, had created a strong affinity between each Actor and its corresponding backend application. And as our Actors are mutually exclusive from one another, so their backend correspondents will be from one another. And each tuple of Actor-backend, would be mutually exclusive from another tuple.
Hitting Rapids
Everything in between our three mutual exclusivity boundaries, like a database wrapped in a Service, would cause a dependency between our backend applications. From an operational perspective, we can overcome our Reliability and Availability concerns. With enough effort, enough shards and replicas, or with a fully managed IaaS service, we can make it into 99.999% availability. Unfortunately, once it would eventually fail, it would bring all of our Actors down together.
An Instability can occur due to a Change to the database. The question is, what Causes a Change to a database? What is the right-hand Source missing in the diagram below?
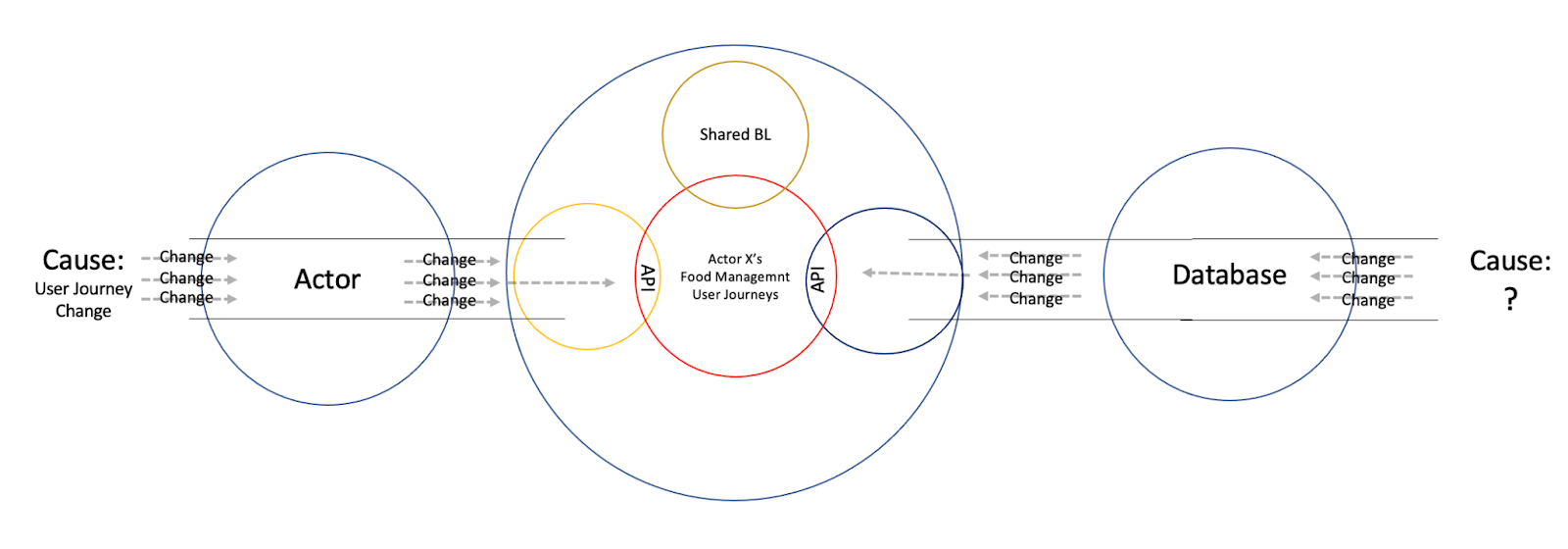
The first set of Causes would be direct Technical Causes, such as a need to upgrade or replace the database. The second set of Causes would be of indirect Technical Causes, such as Changing the data structure due a Behavioral Cause, a Change to the User Journey. Which is okay, because two small Changes are better than one big Change.
But there’s a third one, less obvious. One that originates from a Change to another Actor. A Cause more highly likely to be frequently occurring than replacing the database. It is the Force of Change in effect, and a mutual exclusivity border broken.
From a bird’s eye view, it would be a collision of Causes between two independent Actors/products who are continuously Changing. A Change to one has the potential to inadvertently and indirectly Change another. The bundling of Change in the database, is a potential source of future Instabilities.
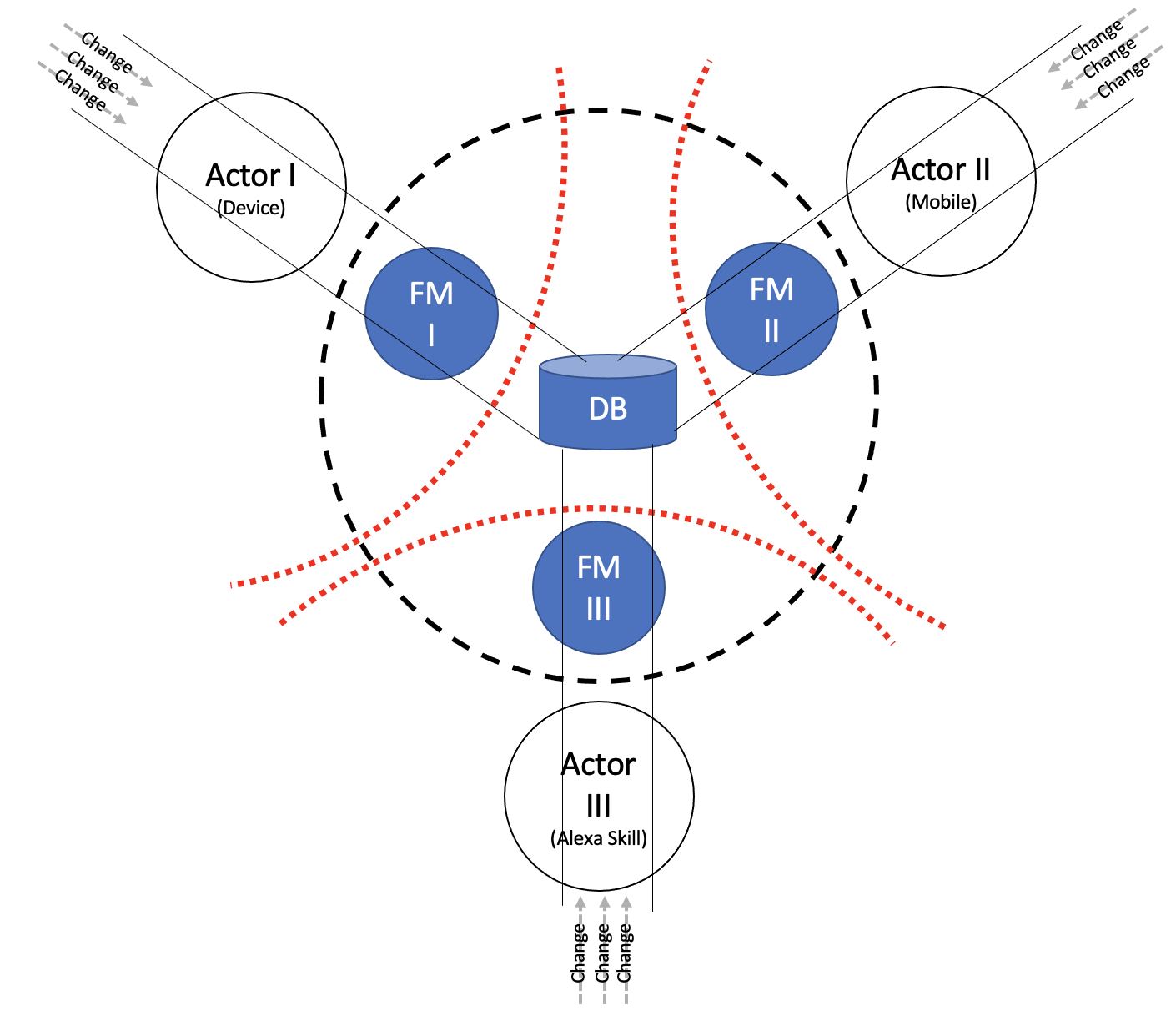
The problem gets bigger, the more Actors we have. So we better adhere to Cohesion and Reliability and somehow avoid it. Let’s try to make sure that whatever is in an Actor’s Direction of Change, would solely be Changed by only one Direction.
[Note: in a way, the above design is extremely similar to Backend for Frontend design pattern]
One solution would be a microservices based one. In the series of Breaking Change, we spoke of the main differences between a Service and a Microservice, and it has nothing to do with size. Microservices help in crossing physical and virtual boundaries and crossing organizational ownership boundaries. Done correctly, as a reusable and gradually Rolled out component, it might solve all of our problems. Let’s add a Food Inventory Microservice to our mix of applications.
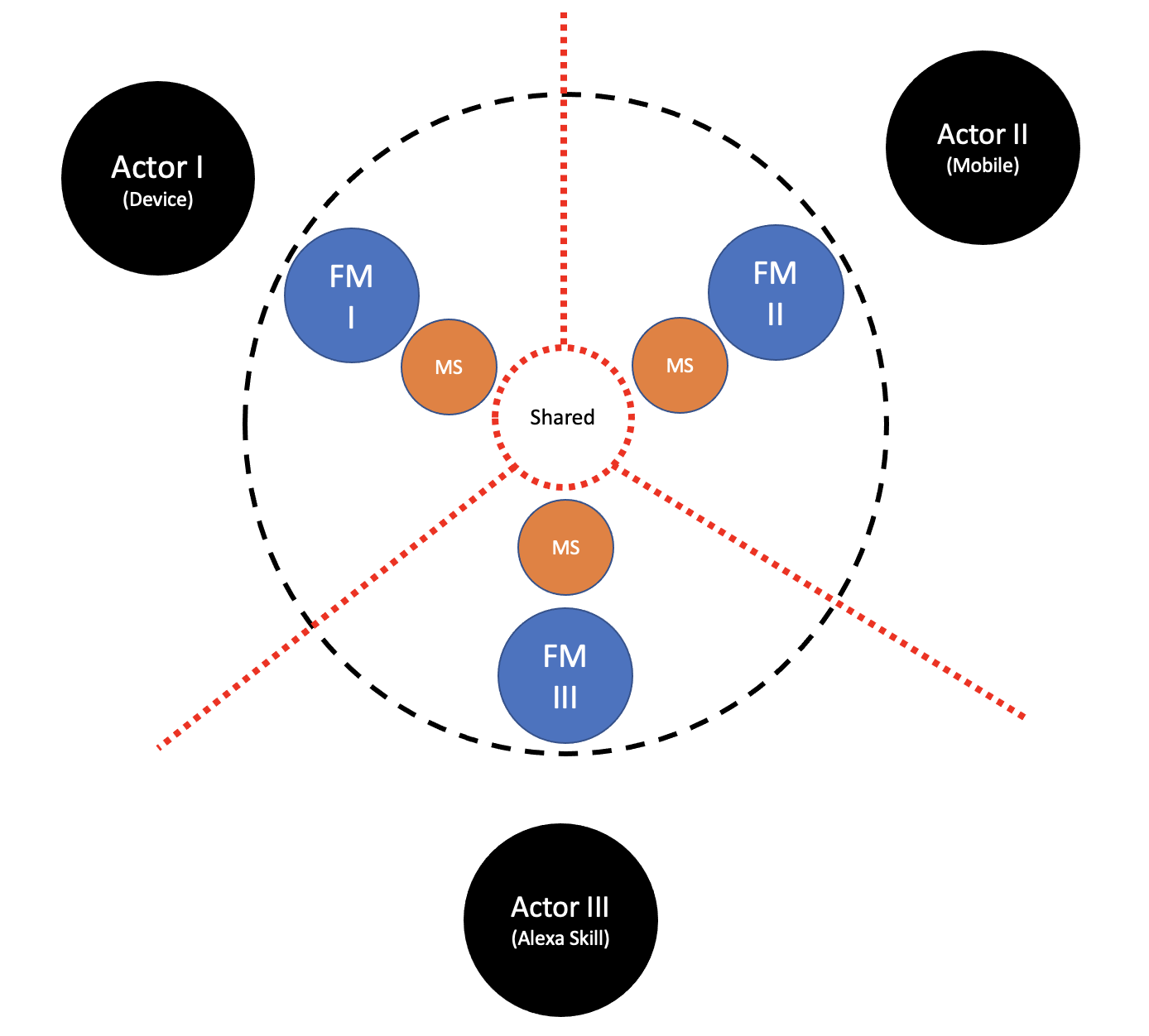
We’ve previously defined a pure application, one that has no sessions, has no state and nothing to persist after a restart. We’ve also speculated it would consist of nothing more than pure functions. Let’s assume our Food Inventory Module is one made entirely of those, and is easily convertible into an independent application, one communicating via HTTP.
From an operational perspective, this new application can be scaled up and down independently and probably more efficiently. It may even use a different kind of compute. If it would require some AI based heavy lifting that needs a different kind of parallelization model, it is now possible for it to be a Serverless Function. It might be beneficial.
From the Change perspective, it fits as well. At the end of each Direction is something not shared. As it gradually Rolls-out, we can Change only one Actor-backend tuple after the other.
Problem is, once data needs to persist we’ll be back to square one. Either the Microservices share a database, or we need to mirror the data between multiple independent database instances. Something we’ll inspect and do later in this series.
Alas, our Food Inventory is data persisted. But it also seems like a step in the right direction, because one of our Actors actually requires a different database. Something we’ll start exploring in the next chapter. Before that, let’s try to unshare our database.
Decentralizing Fitness
Practically speaking, an application with multiple instances communicating with one another, could do the trick. Peer-to-peer based applications have no single master, no one instance to be shared.
It has taken me a hard time to find a database as pure as a Microservice application, one that has no master and has no persistence. Riak KV, if we set it up to be entirely in-memory with no persistence, plus a multi-master/cluster replication. I had also found a framework for our own pure Microservices to use, a distributed masterless in-memory object store called Hazelcast IMDG.
Decentralized solutions are not far fetched. The Riak KV masterless solution was indeed on the table over at RapidAPI, to overcome a consistency problem we had in a multi-region setup of a zero latency Proxy/middleware.
It was dropped due to networking cost issues. Or better to say we realized that a strong consistency would lead to a financial loss. It would have prevented losses summing up to merely a few dollars a month for the company. But the design itself would cost a few thousands of dollars a month plus an effort measured in weeks, worth tens of thousands of dollars. It would have been a non-beneficial design.
Design v.s. Architecture
A decentralization may be plausible for our Food Inventory, the problem we are trying to solve for Silo. But it also isn’t the problem we are trying to solve for Silo. Even if we solved the Food Inventory problem, we can not take it as-is and force others to solve their problems with this design.
The design is a too tight fit. Facing future problems, our engineering team can not be Restricted to a P2P/masterless based designs. To force everyone to only code those kinds of applications for any small problem would quickly end up being non-beneficial. I’m sure our colleagues would be extremely angry if the system architecture would prevent them from using even the simplest SQL database. Wouldn’t we agree with them?
That’s the difference between a design and a system architecture. One solves a problem, the other Restricts solutions. A too strict system architecture, and it would be a Blocking one. It on its own would be non-extendable, which would also eventually be a non-beneficial design.
As such, this design is far from even being a candidate for a system architecture. We did however catch a glimpse into how important architecture is. In the next few chapters we’re going to work towards a design with a potential to become a system architecture. We’re going to keep both these masterless and Microservices based designs in our pocket for a while. We’re going to use those later to make sure whatever architecture we come up with, it would not be blocking us from solving problems.