In the previous chapter, we’ve tried to untangle the bundling made to our Actors through the backend. Naturally, we went ahead and split our Food Management backend application into an application per Actor. As a result, we’ve created tuples of Actor-backend applications. Unfortunately, we’ve only gone half way through.
Our User Journeys are based on our customers’ data, their Food Inventory. Data shared and consumed by our multiple tuples, who are now bundled by the persisting database. We did come up with a design with a peer-to-peer/masterless database or custom applications, where no single instance is shared by any backend application.
Although a viable solution to our very specific problem of our Food Inventory and Management, it is too tight of a design to be a candidate for a system architecture. If we were to force it upon our colleagues, it would Restrict them from finding solutions to their problems.
In this chapter, we’re going to take our first step towards a suitable candidate for a system architecture, by keeping our tuples of Actor-backend as mutually exclusive as can be. Doing so, we’ll learn of many more design concepts and considerations. Those not only shouldn’t be neglected, but also can be a shining light validating our designs.
Survival
In the previous chapter, we’ve started applying a Microservice based solution. We’ve met a dead-end and reached a conclusion that once an application requires persistence, it circles back to a shared database. Because once persisted or retained a state, it would no longer survive a restart, either purposely or inadvertently. But what if somehow we can make it survive one?
Just for fun, let’s say our application’s data is about 50Mb, the size of the entire Merriam-Webster dictionary in PDF. It is small enough to be placed inside a Container along with our application. Once restarted, our application would process the entire dictionary and thesaurus into a graph based data structure dedicated for auto completion based on Lucene. It would now survive a restart and is still a reusable gradually Rolled-out component. We can deploy one instance per Actor-backend tuple, retaining their mutual exclusivity.
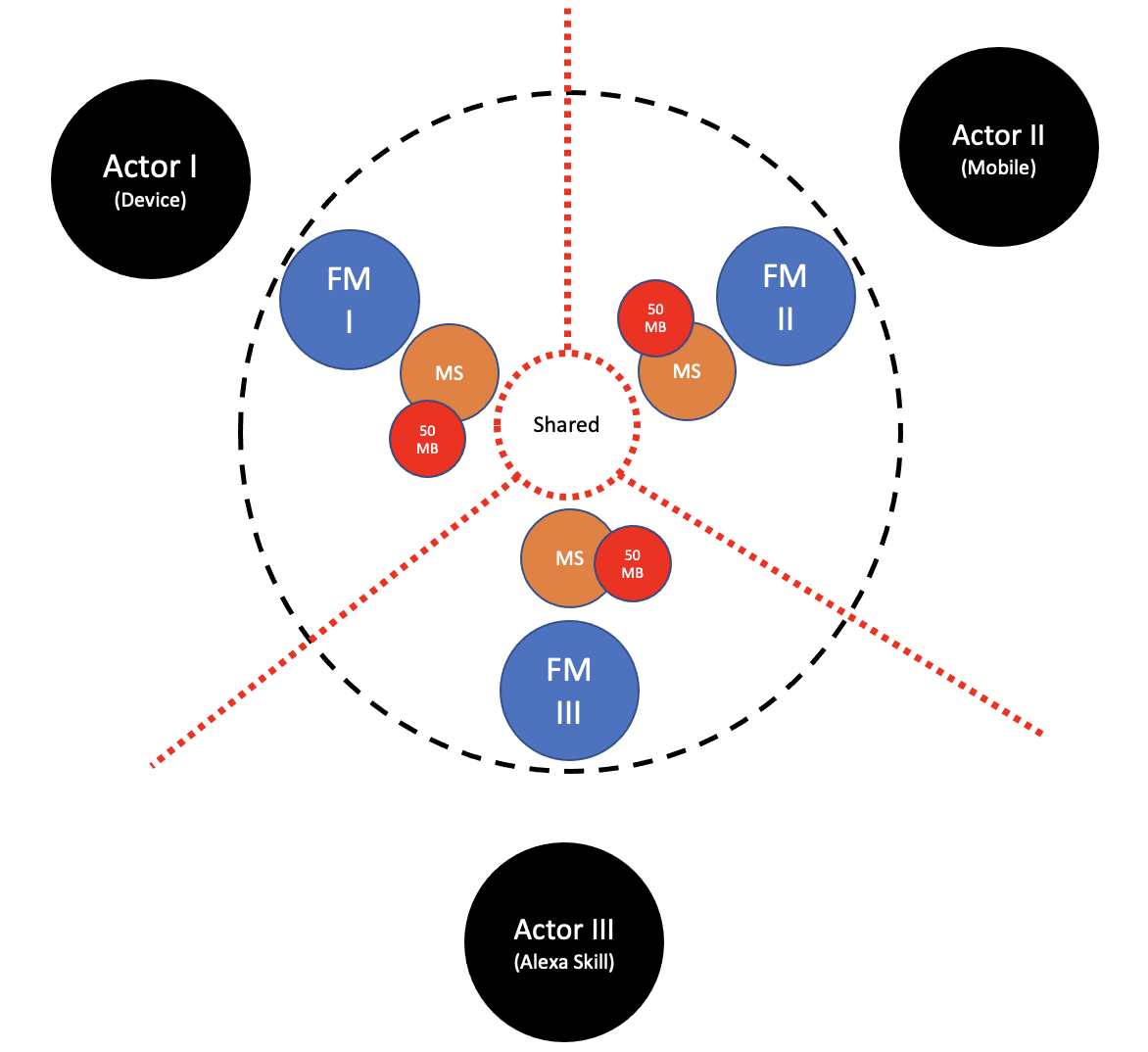
We’ve presumed that processing the entire Merriam-Webster is a matter of seconds. Long enough, it would hurt our scaling capabilities. When it takes our application too long to boot up, it wouldn’t be fast enough to launch more instances to handle unexpected surges in traffic. Instead, we’ll skip the entire processing during boot up and store not the original, but the processed dictionary in a binary format.
Would placing it somewhere like an Object Storage (AWS S3) to be fetched from it, would it make any difference? As long as our Object Storage is highly Reliable and available, it is just as good. Our application would continue to survive a restart.
At Silo (2019), there were several future features designed as such. One would indeed be the auto completion required for our web and mobile applications. The other would be the did you mean required for when speaking to Amazon Alexa.
Reliably Restarting
We cheated a little bit. We did place something in the shared zone, exactly what we were trying to entirely avoid. Have we reached a contradiction, or maybe sharing nothing is too harsh of a requirement? Neither and both.
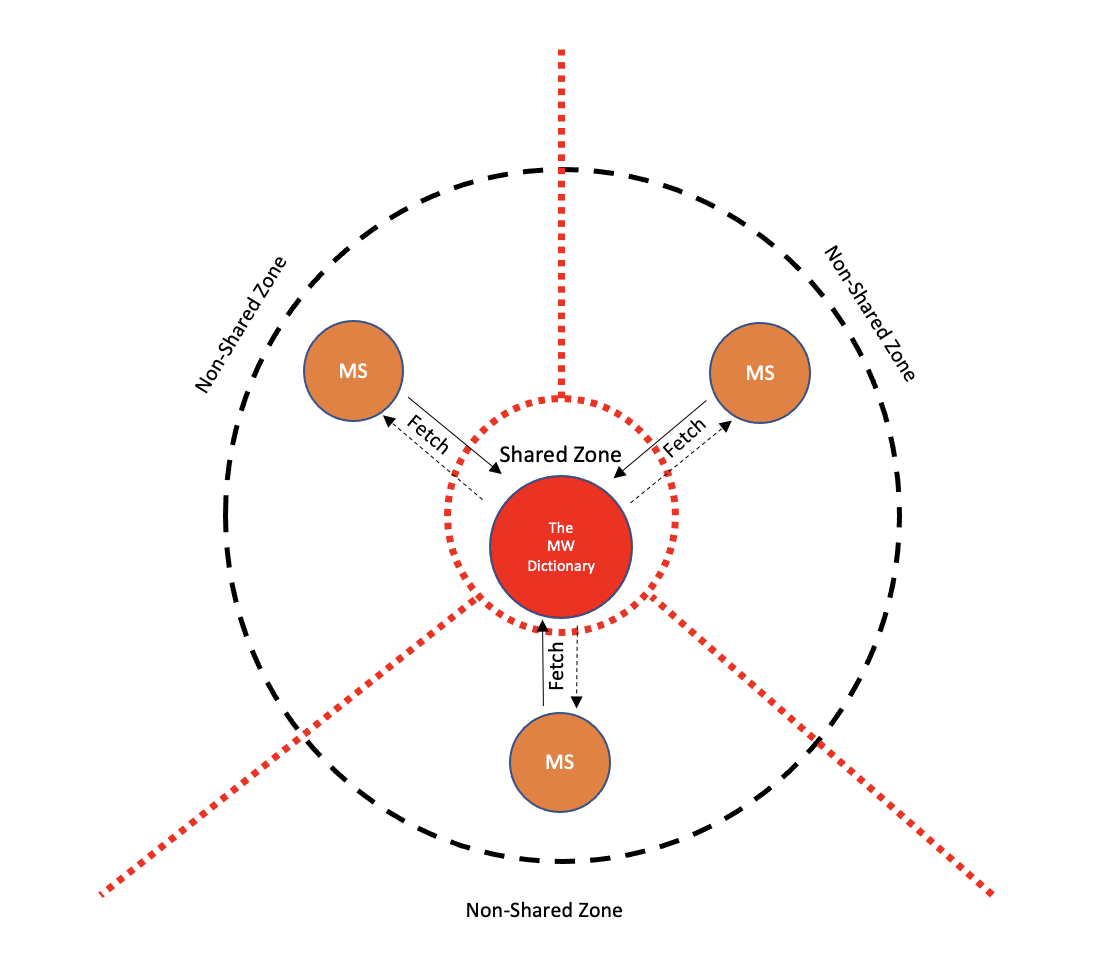
AWS S3’s SLA is 99.99%. According to AWS Well-Formed architecture, this service Change frequency is at most once a month. During that month, it is frozen due to its gradual Rollout. Our data itself, the Merriam Webster dictionary is also infrequently Changing. While it isn’t, it is frozen too.
The combination of the two requires S3 to be available for our application, only during an infrequent restart. Not during run time. The odds of restarting exactly during an unavailability are extremely low. And those can be further reduced by validating S3’s status prior to a planned restart. Making an effort towards a higher Reliability than this, might be a non-beneficial effort.
Unfortunately, we’ve made another presumption here. A far more critical one.
Double Frequency
Merriam-Webster has an ongoing commitment to continuously update their dictionaries. It is completely re-edited and revised every 10 to 12 years, and propagated annually. For us, it entails to rebuild binary files and restart all of our application’s instances only once a year. We can definitely say it is an infrequent Cause and Merriam-Webster is a Source of Change, a mutually exclusive 3rd party dependency.
It seems like we presumed our data to infrequently Change, but I would also say it is a likely scenario. For example, in the discipline of Machine Learning and/or Deep Learning it can easily take days and weeks to train a new ML model. Any applications dependent on it can also be infrequently restarted for an update to be in effect. It might be the case for AI Art companies, such as Midjourney AI and Stability.AI who update and distribute a new ML/DL model only once in a while. An effort towards a more complicated design for these cases, might be non-beneficial.
There are actually two frequencies we should be aware of. How frequently the data Changes, and how frequently the Change of data propagates.
Silo’s Food Catalog was a data set to be continuously updated by a company’s employee, another Actor. He was expected to add more and more food items to it, for 8 hours a day, 5 days a week. Something that can be done offline. For the latest Changes in data to go live, it could have been only once a week or a day because the delay would matter less to our customers. It is also safe to assume that more food items would be added earlier in the product’s life cycle, and would dramatically succeed within a few months.
On the contrary, at DealPly (2015) and Wiser, (2016) the data of the Web Scraper models was continuously updated, but very slowly. Maybe a fews tens of scrapers a week. But every delay in their propagation was a money loss, as each updated scraper performs better than the previous one. At both companies we’ve done a lot of work to hasten the propagation.
Time to speed up those two frequencies. As some customers have an expectancy out of freshness.
Failure to Restart
Let’s review the case of applicative configurations. Our Microservice’s data is an aggregation of all of our customer’s configurations. And it is within our customers expectations for the configuration to be in effect within a few minutes. For simplicity, let’s say it is 5 minutes.
Although our Object Storage is highly available, our data is no longer frozen. As the data is no longer frozen, the odds of it breaking is non-zero. It could be someone putting a typo in our stored file, or maybe an unexpected Change in the dependent data structure. Restarting all of our instances together, we will potentially create an entire system shutdown when the restart/update fails. A restart we now frequently do every 5 minutes, to meet our customers’ expectations.
In order to maintain our Reliability through Cohesion, we will gradually Rollout and restart one instance after the other. When the first instance would fail to restart, the Rollout would stop and the rest of instances remain operational. Which is exactly our intention. Unfortunately, the Rollout might be too long. With enough instances to restart, it might take us more than 5 minutes to do so and we won’t be meeting our customers’ expectations.
Consistent Experience
Our Microservice by definition has multiple consumers. Such was the case over at RapidAPI. We were expecting to have hundreds and thousands of customers, all living in the same multi-tenant environment. One feature was the Monetization and it was big as an entire business domain, and had a dedicated team on it. It was also something only a portion of our customers wanted turned on. Once its flag was on, it supported multiple modes.
These flags and modes were a part of our customers’ configurations, consumed by both multiple backend Services and multiple micro-frontend applications.
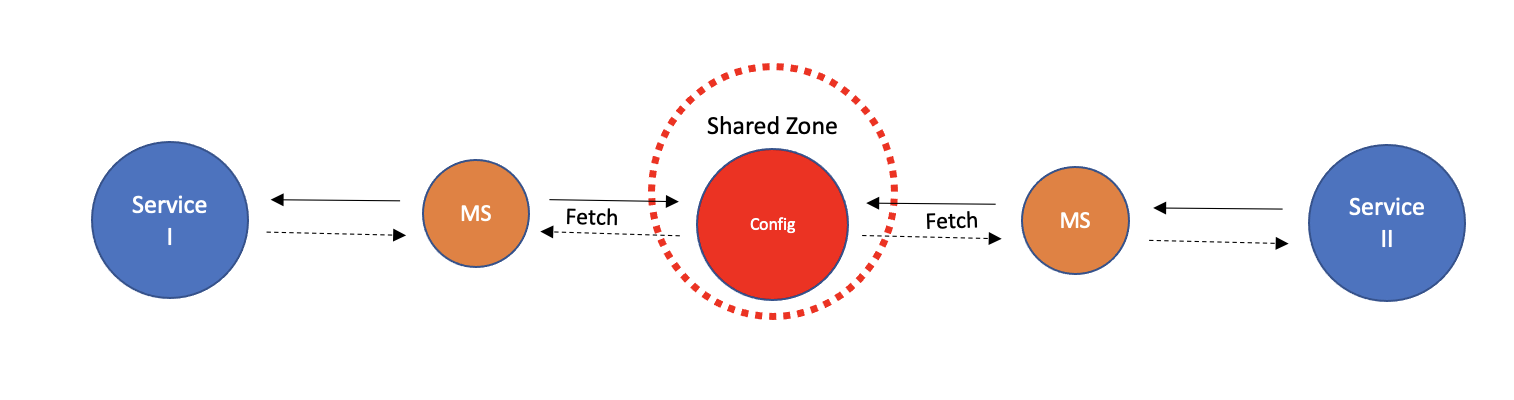
Our customer wouldn’t mind if it took 5 minutes for the configuration Change to propagate and be in effect. But as a configuration would affect multiple mutually exclusive micro-frontends, it had to Change for all of them at once. The experience for our customers must remain consistent across all of our applications. It includes both our customer-facing applications, our Actors, and their supporting backend Services as well.
If we were to gradually restart our configuration microservice, it may create a big enough time gap where its data would not be consistent between the multiple instances. Some would hold the fresher data, others would hold stale data. It would create an inconsistent experience for our customers, at least for a little while.
So there is a threshold set by our customers’ expectations out of freshness, where our restarting strategy would no longer fit.
Pulling Prices
Let’s try something a little different. Instead of a restart, our microservice will re-fetch the data from S3 every 5 minutes, by presuming all of our instances would be pulling it exactly at the same time. Unlike before, when the fetch fails, our instances will remain alive and unharmed. And as long as the data is available and intact, our application would survive a restart as well. Doing so, we made sure our propagation both meets our customers’ expectations out of freshness and provided a consistent experience. The thing is, RapidAPI’s customers are infrequently Changing their configurations. Meaning most of the fetches would be redundant.
In the practice of software engineering making redundant network calls is a bad practice. Fortunately for us, we go beyond good and bad. More fortunate for us, everything we do in the cloud has a price tag. We can first calculate the costs of our designs, and then decide whether it’s an eventually beneficial decision or otherwise. Let’s put a price tag on our supposed redundancy.
The price of performing 1k GET requests from S3 (AWS’s Object Storage) is 0.0004$. A call every 5 minutes sums up to 8.64k calls a month, about 3.5$ a month, 42$ a year. It is financially equivalent to 20 minutes of work time for our engineer. If other solutions would lower the redundancy but take more time to implement, it may not be something worth paying for. Unfortunately, this price increases linearly with the number of instances running. That’s a warning sign.
Back in 2021, RapidAPI had 6 backend services. If we wished to ensure high availability and Reliability, each service would require a cluster of 3 instances of our microservice. 6 services times 3 instances, that’s a total of 18 instances running for our microservice. It sums up to about 750$ a year. RapidAPI’s suggested future architecture had expected to potentially split each backend Service easily to 4 Services. Our redundancy would potentially cost 4.5k$ annually. Amazing how such a small design choice can eventually have such a big impact.
Supposedly we can circumvent this redundancy with just a few lines of code, to check the metadata for modifications before blindly refetching the data. Unfortunately a HEAD operation costs exactly the same as a GET operation. All we did was maybe save some of the cost of traffic in M/Bs.
Frequently Changing
Supposedly, settings and configuration really isn’t something that one customer frequently Changes. Just to play with the numbers, let’s assume that one customer Changes his own configuration once a week. Each does so only during working hours of Monday to Friday / 9 to 5, and all of our customers work in the same time zone.
Having a thousand customers, entails having a thousand updates a week combined. Will they all be performing their updates together exactly in the same 5 minutes window? Obviously not. Will they all stand together in a queue to perform one update per window? Obviously not as well.
Presuming it is something we can observe and measure, we will find these updates spread across working hours. They do have a distribution, probably an unknown one. But what we do know for sure is that with enough customers, there would be at least one update in each 5 minutes window. As the data in our S3 does Change every 5 minutes, checking its metadata with a HEAD operation would be redundant and we’d be paying for nothing.
It would be interesting to know what will happen to our data transfer costs. In the worst case, our data would be refteched 12 times an hour summing up to about 2k times a month. For a 1MB file, that’s 2GB fetched per month per instance. For RapidAPI’s future 72 instances required, that’s 144GB/s a month which is about 3$ a month (or alternatively consumers the entire company’s free tier).
Although it seems like a neglectable amount, data transfer cost scales linearly with our data size. Another warning sign. But it also decreases with our data size. For small enough files who grow extremely slowly, we can safely say data transfer costs are of no concern for us in this design.
Cost Leakage
Two years after we implemented the above design, our beloved product manager walks in. He says that propagating configurations within 5 minutes no longer meets our customers expectations. He managed to manage their expectations, and they settled on one minute only. A recently recruited engineer goes ahead and just Changes the interval parameter from 5 minutes to 1 minute. The job got done within minutes. Everyone is happy.
Unfortunately, the engineer who designed this is long gone. He left without leaving any documentation on the considerations made that led to our interval based re-fetching design. He was the only one who knew that the costs scale linearly with the time interval. It was a long forgotten warning sign. If that were to happen at RapidAPI, that would make the design’s annual cost jump from 750$ a year to 3.75k$.
What would be more amazing, would be it going unnoticed. We do our math for annual costs, but we actually pay the bill on a monthly basis. A jump from 62.5$ to 321.5$ is exactly the same x5 increase, but it would be swallowed in with the rest of our cloud bill. There is no reason for someone who is unfamiliar with how the cost scales, to remember to check the bill a month later. Only once the increased costs would accumulate enough, maybe someone will notice it. Months after the bill was due.
If it was me, I would code the application to crash when the interval is set to anything lower than 5 minutes. It would put up a critical error message referring to the cost issues. Problem is, the first time it has ever occurred to me to do something like this.. is at the time of writing this. Whoopy me.
Long Poll
There is a way to get rid of our recurring GET requests. Although not supported on S3, for our story’s sake let’s presume it is or we made it happen somehow.
Our configuration microservice would still be performing a GET request to our Object Storage, just not to our data file but to a lock file. As long as the lock file does not exist, S3 will not fulfill the GET request. The connection would remain open until we would put in and create the lock file. Something we would only do only after we Change the data file. This would be a signal to our microservice to refetch the data file.
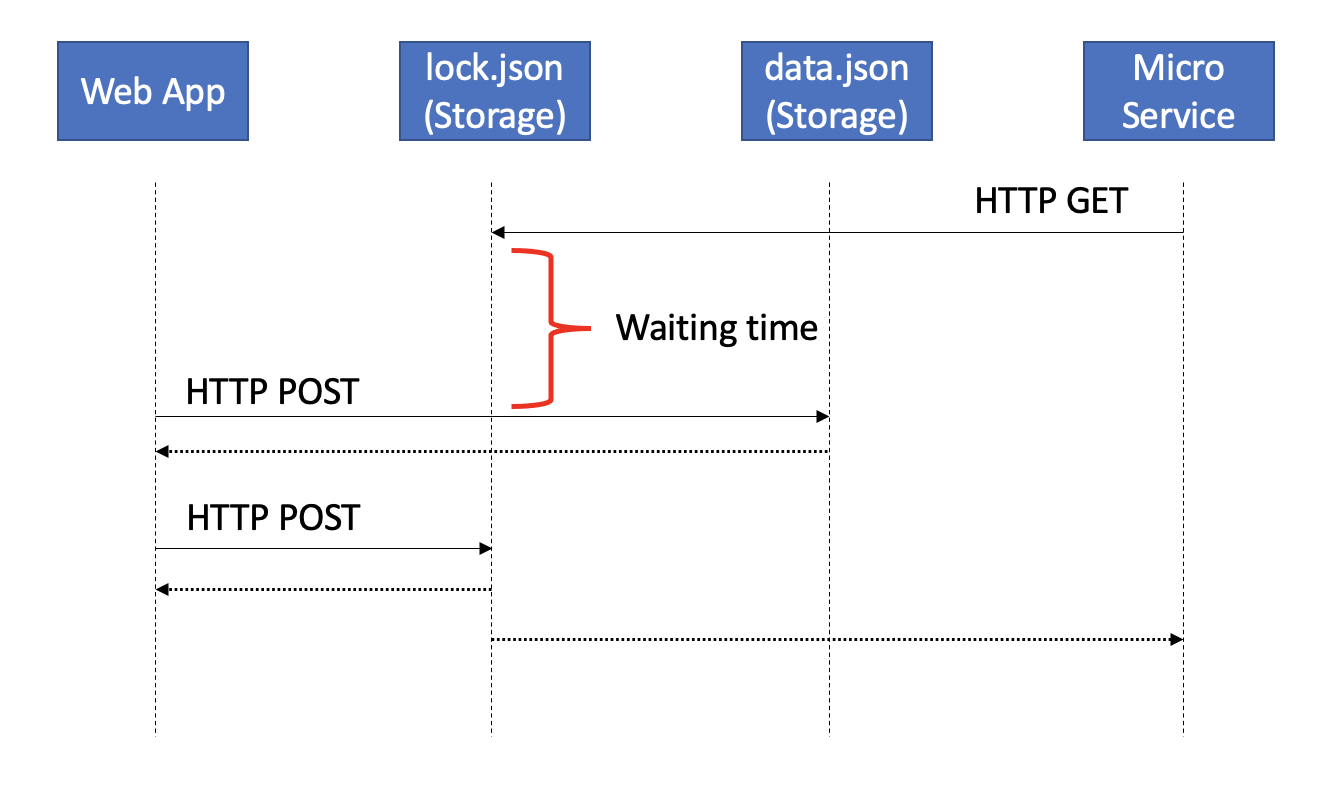
We would still be fetching the data in its entirety thousands of times, it would still accumulate to GBs. However, we are no longer performing or paying for redundant calls. And also, an interval no longer exists. Our design’s cost will no longer scale with it, but might cost more in effort. We’d also be meeting our customers’ expectations of fast propagation and freshness.
Our instances would also be more consistent with each other. We had presumed all of our instances would be pulling the file together at once, but that’s unrealistic. Each pulling the data on its own schedule would create a time gap and an inconsistency. With long polling, each instance’s connection would be closed by our storage at nearly the same time. It would lead to a much shorter time gap, maybe even short enough to meet our customers’ expectations of a consistent experience.
Of course nothing comes without a cost. This solution has a technical limitation due to keeping our connections open for a long duration, even 24/7. For a small number of clients it would not be an issue, even for hundreds of instances.
For a few thousands of customer-facing applications, such as our Actors, our servers will quickly reach the maximum number of open files/connections available. An issue known as the C10k problem, something which requires expertise in network engineering and maybe even dedicated hardware to overcome.
If we’re considering WebSockets, it would still be a connection remaining open for a long duration. Although not supported on S3, WebSockets are supported on AWS’s API Gateway and AWS IoT. And guess what? We would be paying for the connection’s duration, and it scales linearly both with duration and number of clients. A warning sign.
In the next chapter, we’ll try to come up with designs who require no open connections. Another step towards a candidate for a system architecture.