In the previous chapter we reviewed a use case over at RapidAPI, of its frontend application which about 15 engineers had been constantly working on. One day, years after the application evolved into a Monolith a specific technology and practice had come to a fruition. Once splitting to micro-frontends was feasible, the option to break the Monolith had opened for us.
The frontend Monolith had been forever a Bottleneck in the development workflow, but only once it was optional to remove the Bottleneck, we started to consider it to be an Inefficiency. The only question was, why were we sure that splitting one single application into multiple ones, would be something beneficial to do.
We examined colleagues from multiple teams, what and how frequent their Tasks are, and the expected effect of the split on their development workflows. We noticed it has a lot to do with the frequency of Change and the unsteadiness of the Change Stream. And as we’ve seen throughout this series and the Change Driven Design series, to overcome it has something to do with Cohesion of Change and Cohesion of Causes.
In this chapter, we’re going to focus on the ties between cohesion and splitting applications. That is by reviewing another use case of a split done at RapidAPI, an internal one done between the Monetization and the Analytics teams (which was later renamed to Data).
The Damage Done
One of RapidAPI’s earliest and most unique features was the ability to monetize your API, to charge your consumers for its usage. It could have been a monthly subscription, and it could have been per quota. To allow the latter, each individual API request needed to be logged. As they were already logged, there was another set of features called API Analytics. It allows you to gain insights on your API traffic, such as its error rate and response time.
Logging a single request is easy. Logging and ingesting 40k requests per minute, a rate which was expected to grow x3 to x10 times, is a challenge in the technical domain of data engineering. For that reason, both business domains of Monetization and Analytics were owned by the same team. As a result, there were two backend applications to serve them both. One was the database, the other was the Service.
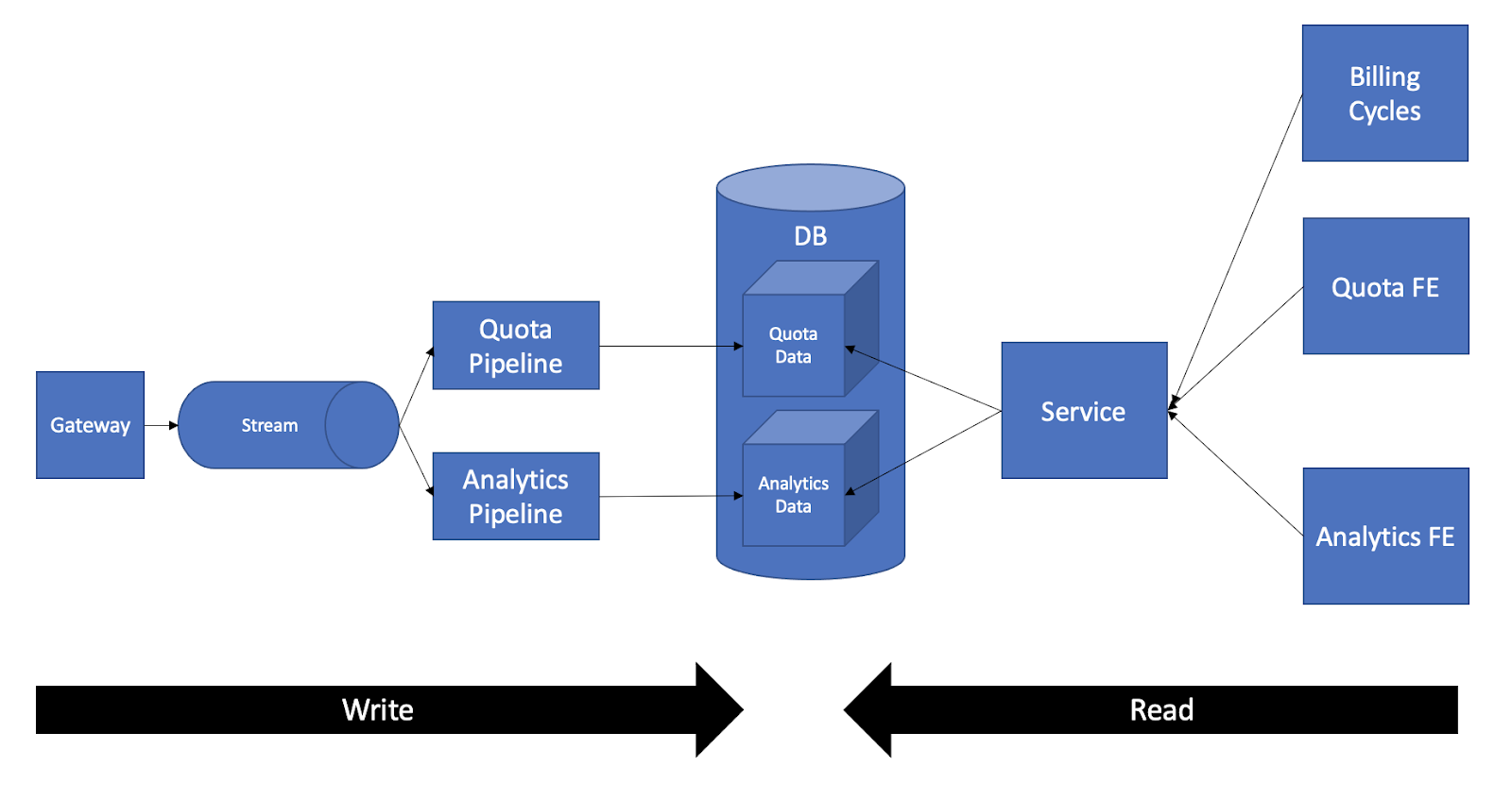
The API requests were coming into a single Stream. They were being independently processed by two pipelines/consumers. Each pipeline stores its output in a dedicated and isolated set of tables, both sets stored in the same DB. The Quota frontends, about 8 of them, called the Service’s HTTP endpoints, which would issue SQL queries over the quota data. The Analytics frontend, called a different set of HTTP endpoints but of the same Service.
When I joined the company in 2020, I noticed a reliability issue with Eventualism in mind and designing for failure. While the team was making Changes due to Analytics related Causes, they sometimes introduced an Instability as every Change has the potential to be one.
Sometimes it would bring the entire Service down, taking everything Quota related with it all the way through our frontends and customers. But it was far more serious than that. There was a business process running in the background called Billing Cycle, the one that charges our customers per quota. During an Instability it led to incorrect charges being made. Although everyone was reimbursed or eventually correctly charged to the cent, it was after the fact and after the damage to our customer’s satisfaction and our brand was done.
Reliability
I already knew that these Instabilities would become more and more frequent. First, I had a hiring plan. It was expected of me as the manager to grow the engineering team 3 times over the next year, from 5 to 15 engineers. It would entail an increase to our Throughput, around 2-2.5 times. Second, there were product roadmaps. All of the Monetization features, all of the Analytics features, and the entirety of the data infrastructure. Everything was expected to Change.
I also noticed that not only Monetization and Analytics should not Change together to prevent Instabilities, but they actually had no Cause to Change together. Within that Service, there actually are two mutually exclusive applications. Both do not even share data, only share a database.
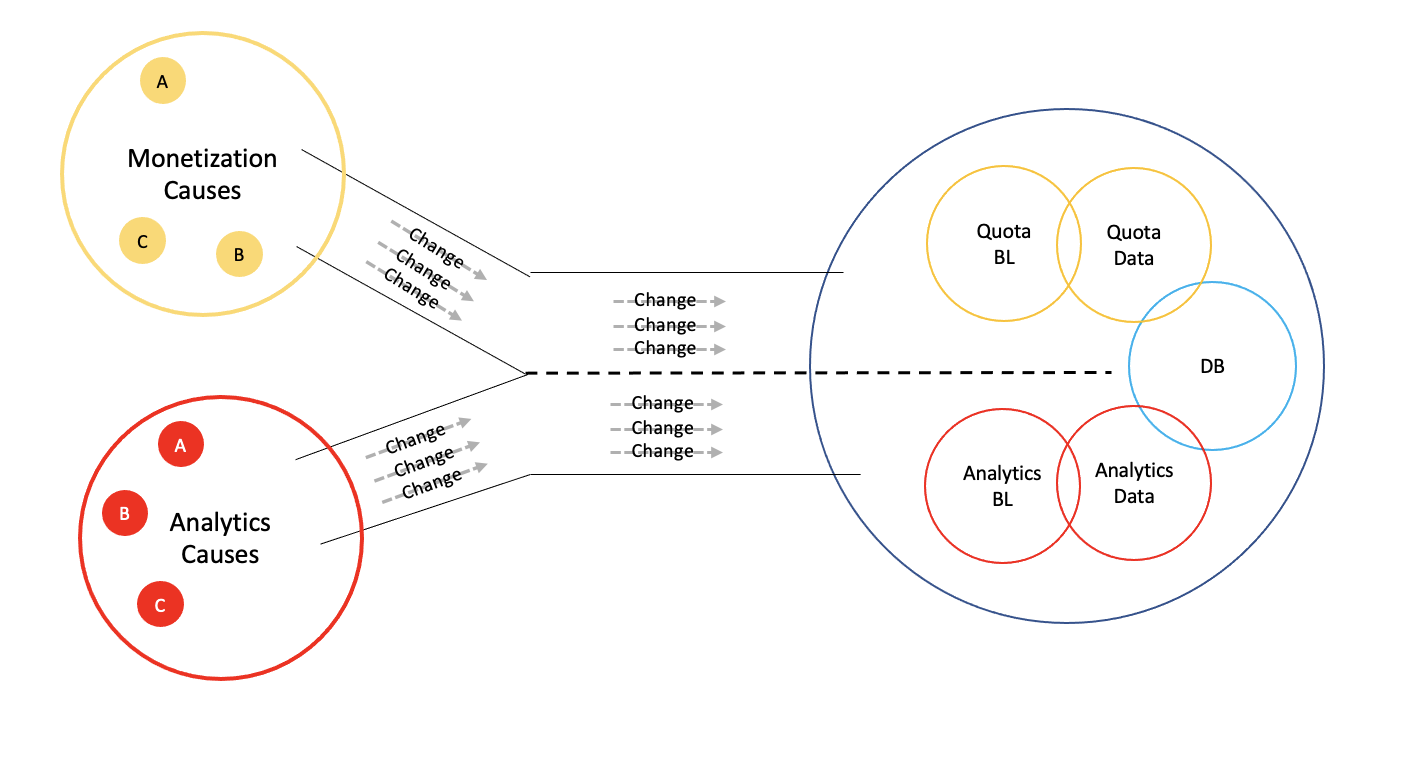
It shouldn’t come as a surprise, because Monetization and Analytics were already two separate business domains. Each an independent cut within the Change Stream. They were only merged together due to technical reasons and organization structure.
We split the Service into two applications, the Analytics Service and the Quota Service. Instabilities were still introduced, maybe even more than before because removing a Bottleneck increases Throughput. On the contrary, it was easier for us to trace and revert issues as Changes from the two business domains were no longer bundled. Doing this more efficiently meant less downtime for us when Instability occurs, thus higher reliability.
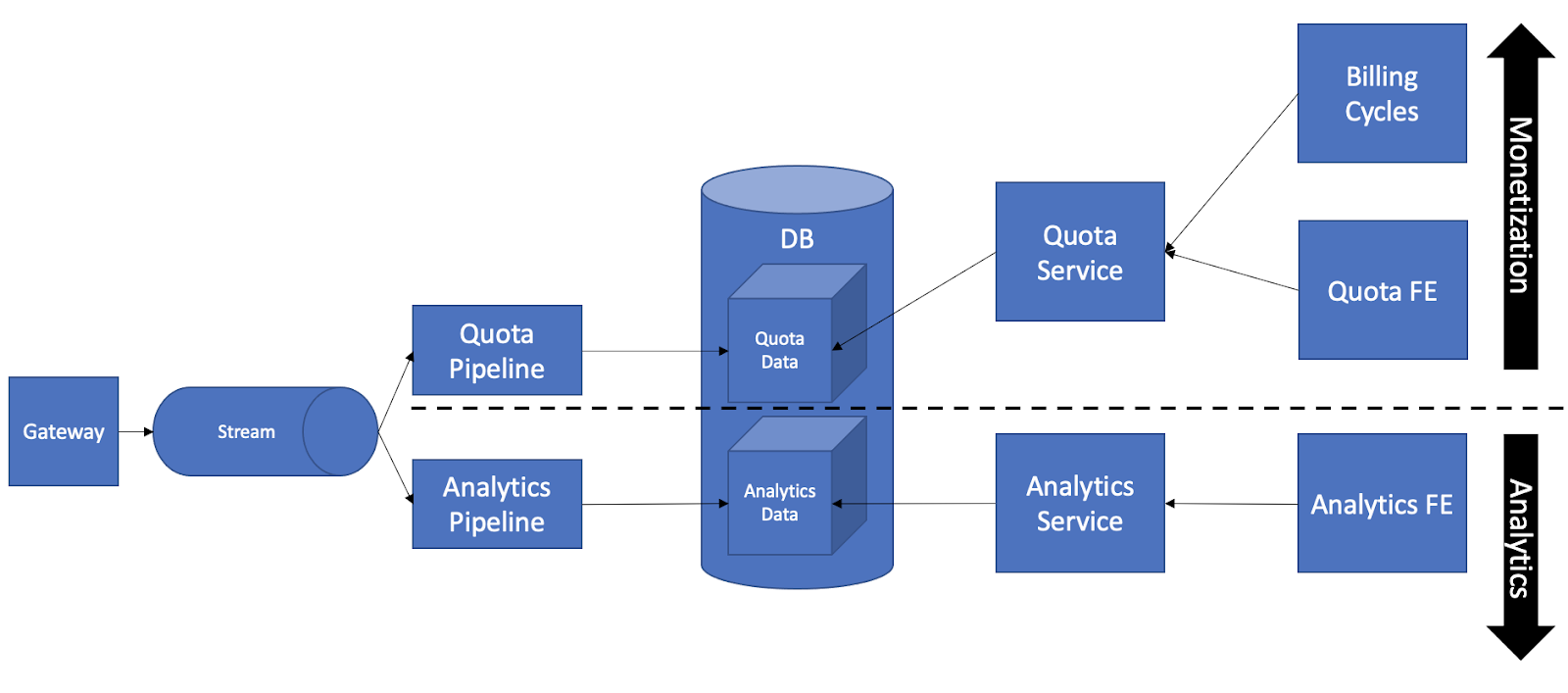
But the big difference was that the two applications no longer intersected. An Instability to Analytics Service did not have any effect on Quota Service at all, and vice-versa. These were future Instabilities prevented, meaning higher Throughput. When they happened, the Instability was contained within a smaller blast radius, resulting in an even higher reliability. And indeed, our customers experienced far less issues with their charges.
There was one last interesting consequence. Let’s recall that I was tasked with tripling the team’s size and it owned two business domains. If we notice carefully, two mutually exclusive collections of applications have been formed. One collection would be Changed only due to Monetization Causes, the other only due to Analytics Causes. A technical restraint was lifted that would otherwise have prevented me from splitting the team into two. To split the Throughput once it grew large enough.
Well, that’s not 100% correct. They did still share the database.
Noise
One of the outcomes of running an unmanaged service is the need to overcome operational maintenance and observability. One of which is to remember to precisely monitor everything, even the littlest most basic metrics such as disk space. So we ran out of disk space.
As a consequence, the Quota Pipeline came into a halt for a few hours and the Quota data was no longer fresh. As the Billing Cycle business process continued periodically as usual, once again incorrect charges were made to our customers.
Both the Analytics and Quota data were stored in the same database, and it was the Analytics data that caused the disk space to run out. Although there was a 1:1 ratio in the number of records, an Analytics record was 20 times larger than Quota’s. An Instability in Analytics has led to an Instability in Quota. Once again, a reliability issue.
This is an effect known as a noisy neighbor, where a tenant who runs out of control causes a disturbance to another. In our case, it was two of our own Services sharing the same database. I suspect the incident described is one of the reasons why both in Service Oriented Architecture and Microservices Architecture, each Service has its own independent database.
As a database in an application, a split here would have the same consequences of splitting mutually exclusive applications. It would have the same increase in reliability we’ve gained by splitting the Analytics and Quota Services. But not without a cost.
There is a lot to lose when data is split between multiple databases, such as the ability to easily query all of our data. Luckily for us, the two data sets were mutually exclusive anyway and there was never a need to do a cross query between them.
So, although everything suggested splitting the data to two independent clusters of our database, we did not. There are always more factors when design patterns meet reality. Another cluster would cost a minimal additional cost of 1,200$ a month per environment. As back then RapidAPI deployed servers per customer (private tenancy), that would be a minimal annual cost of 14,400$ per customer. For some customers, that would be about 10% of their contract. Instead we’ve remained with a single cluster, storing each dataset in its own hard drive and monitored disk space.
We knew it would barely do anything to our reliability. It only made sure that the similar Instabilities would not reoccur. We knew it would not contain other kinds of Instabilities. Not contradictory, it was also not a good enough reason to cut 10% of the income to overcome an unknown future concern. It would have made it into a non-beneficial one.
Unfortunately, eventually everything fails. We ran into an Instability a few months afterwards with dire consequences. We’ve upgraded the database cluster to a newer major version, and it all went haywire. Not even a revert helped and not rebuilding it entirely from our Source of Truth. Both Analytics and Quota were hit at once. If we had two separate databases, the update could have been Rolled Out gradually, and we would have hit only one Service and not the two. One bird, one stone.
It was resolved after I left the company, by moving the Quota data away to another kind of database. As by then RapidAPI had dropped private tenancy to a single multi-tenancy environment, it was also a financially feasible solution and a beneficial one.
In the last two chapters, we’ve seen a split has a lot to do with frequency of Change and Cohesion of Change. We have one last use case to review, in order to see where the combination of the two would lead to non-beneficial splits. On this, in the next chapter.