In the last chapter, we had found a design that seems to solve something. With also tying a few last knots, it could also be a system architecture. One that technically enables multiple applications to be entirely mutually exclusive, from the most front-facing Actors all the way through the backend and the databases.
We had reached this architecture through the last three chapters, by inspecting many parameters and perspectives. Out of those, only two have a direct effect on our customers. Freshness and consistency. The third one has an indirect effect, one that constitutes a difference between a software architecture and a system architecture.
In a way, this chapter is a prequel. Most of what we’re about to read happened before we found the technical design. We can say it even gave birth to. Reading it after knowing the technical design is an important lesson on its own. Everything we do, comes to serve a purpose, most likely to serve our customers. The sooner we understand those, the better our designs and our system architecture will be.
So, we’re going to start all over again. With Silo’s customer expectations out of Silo’s product. And of Silo’s expectation of itself.
Inconsistent Expectations
Silo had three Actors, each one is its own application running somewhere unique. They had a shared experience, one we have intentionally kept as an abstract and just named it Food Management. Let’s start and uncover what it is, one Actor after the other.
With the first Actor of a mobile application, you could have scrolled through a list of food items. You could have edited them with a virtual keyboard, label an item as “Strawberries” and add a purchase date “1/1/2020”. With the second Actor, the Alexa Skill, you could have asked “Alexa, what is my strawberries purchase date?”, or “Alexa, what did I purchase in January 2020?”. The experience was of Food Management, and was decomposed into multiple Actors due to technical/physical constraints.
From the description of the customer’s experience above, we can see an input from one Actor will be queried or be an output to another Actor. In a way, we can generalize Food Management and say it is a set of Actions applied on the Food Inventory. Some Actions query the data, some mutate the data. And when the data is mutated, it will have an effect on the experience.
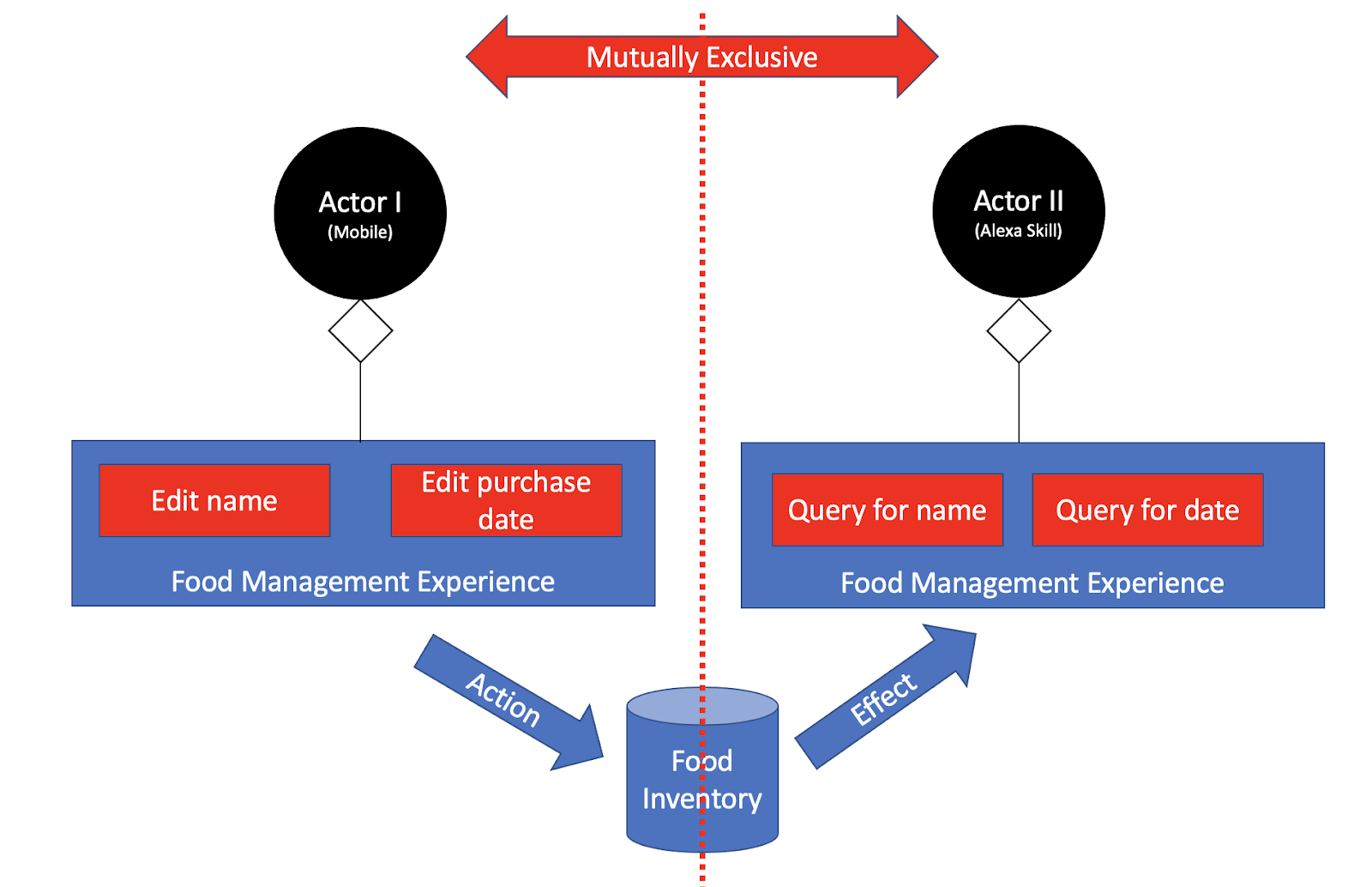
The two Actors are two mutually exclusive products/applications. They will never share any code and will never be deployed to the same physical entity. Each has its own unique interface, leading each to have its own closed set of mutually exclusive User Journeys. Entire independent product features/Flows coded into each.
On the contrary, It is one Actor making an effect on another through the shared data. If we’re thinking of a technical coupling of sorts, that is correct and the outcome of something shared between multiple Actors, which our candidate for a system architecture is technically able to overcome.
When we brought in Silo’s 3rd Actor, the physical device, we noticed something curious. An experience running across multiple Actors, was setting different customer expectations for freshness and consistency.
Silo’s physical device was a smart kitchen appliance that extended food shelf life by creating vacuum conditions inside Silo’s food containers. Each container had an RFID chip to uniquely identify it (don’t ask why). Once placed on top of the device, the container’s current food label was shown. The same food label that can also be edited by the mobile application and queried by the Alexa Skill.
The label had to be shown quickly enough on the physical device’s screen. If it would have taken seconds, it would be a customer standing staring at a device seeming stuck for a few good seconds. An annoying experience. If we need to imagine it, think about how annoyed we would be if updating our To Do List would have taken a few seconds instead of a few ms. So, what is quick enough? As a rule of thumb, only above 250-400ms a customer may experience an annoying jitter. So the time required to for round-trip fetch of the freshest data from the server, should be less than that. But not significantly so.
Once the label is shown, a customer could have touched a physical button. It would invoke the Alexa Skill, letting our customer speak out a new label, ”Apples”. Processing it did cause annoyance, but only after about 4-5 seconds. First, because a customer expects an Alexa reply to take a few seconds. Second, the screen itself also had a “processing” indication, signaling the customer his experience is still in progress. Signaling the device is not stuck, and is about to do something soon. Third, the experience was designed for our customers not having to wait until it is done, in order to move on with their lives.
This experience only ended when the label had also been updated on the mobile application, and our customers barely had any sensitivity to how long it takes. From a mental perspective, it takes “time” for an update to “cross” a “physical distance” between two devices. A time delay was something to be expected. If it is expected, annoyance would not be created for an even longer time.
The real customer expectation is for another user-interface to be updated sometimes later. It could be a few seconds, similar to the time it takes to switch tabs and refocus our mind in our browser, or a few minutes until we finally reach out to our mobile to use Silo’s app. Or the few seconds it takes to switch focus from a physical device to a mobile application.
On the contrary, if someone were to edit his label through the mobile device, he’d expect feedback for success or failure, almost immediately on the same interface. The very same expectation a customer has while interacting with Silo’s physical device, an almost immediate interaction with its user interface.
To summarize, we noticed a difference in expectations between a customer continuously interacting with a single interface, and a customer interacting with multiple interfaces. The first must be a smooth experience. The second can be eventually consistent, and it is an asynchronous experience by nature. Putting an extra effort to make it a real time hard-consistency experience, would have no effect on any customer. As there is no gain of it, it would be a non-beneficial effort.
Reliable Expectations
Similarly to our customer experience for freshness and consistency, they also had an expectation for Reliability. One the reasons behind why our architecture revolves so much around Cohesion and Reliability.
Consider the following about any mobile or web application, Gmail for example. Let’s say a bug exists in the settings menu. For some reason, pressing the logout button does not work. Would that annoy you? Probably not. You’ll probably never know of it because you rarely use it. But if at that moment you do need it and it doesn’t work, you may just tell yourself “I’ll just do it later, no worries”. On the contrary, if the compose button would not work, you’d be extremely annoyed because you need to send this email right now. What’s the difference between the two?
Sending and receiving emails would forever be Gmail’s primary function to its customers. As long as it works, it is the largest annoyance avoided. However, sending an email is also an experience, a Flow where the button is only the customer-facing part of. If the Flow fails, it does not matter to our customer whether it was a bug in the button itself or if the servers went down. He would be most annoyed no matter where the technical problem actually is.
We may take a bug in our mobile application as something that happens, but we have no tolerance towards a bug in our oven. If it’s hard to open and close the oven, you’d be a little annoyed by it. But if a few times a year it doesn’t switch on and heats food, you’d be furious. First, because unlike for a mobile application, you paid hundreds of dollars for it. Second, that is your expectation of a kitchen appliance. It should just work. And that’s why Silo’s smart kitchen appliance, which is literally located next to other kitchen appliances, had to meet the same expectations.
This was not an imaginary scenario. We started working on Silo in 2017. A year before that, a smart pet food dispenser stopped functioning due to some server-side issue. As a result, millions of pets were not being fed for days, and went hungry. Their owners, the customers of that said company, were extremely furious for good reason. You had one job.
So Reliability is first doing whatever it takes to ensure primary functions will work no matter what. Or at the very least they should continue to work, even when everything else fails. Cohesion and Reliability, setting the right blast doors to minimize blast radiuses. But as a primary function is an experience, it is the entire experience that should continue to work no matter what.
Problem is, it is also an experience technically decomposed into multiple applications. It involves Actors, frontends, backends, databases, platforms, whatever. Each one on its own and all of them together must just work. It’s a challenge. Luckily, we loved challenges.
Consistency and Reliability
For Silo, the Reliability was somewhat correlative to the eventually consistent experience. When the mobile application’s Food Management goes down, once it is back up it must catch up with everything that happened during the down time. Which would also happen under heavy load, where freshness and consistency would be a little lower due to delays.
As long inconsistencies and too low freshness could lead both to annoyance or confusion, we chose for it to be unavailable while it’s down. To show nothing to the customer. As nothing is shown, there is nothing to confuse the customer.
We’ve decided both to be appropriately satisfying during heavy loads and downtimes, because between our Actors it is an eventually consistent experience anyhow. Whether it is better than showing an inconsistent state, is most definitely a product-driven decision not to be easily made. By considering the end effect on the customer, we’d reach the right answer for each and every use case we’ll handle.
And here’s the really cool part. So although Food Management is considered a prime function, even when the mobile Actor fails to participate, no harm is done. But if the Alexa Skill fails to participate in it due to a temporary Instability, it would merely be a label missed. A little annoyance to our customers, but also something could later be fixed by editing an item in the mobile application.
On the contrary, the labeling process was important for Silo. We created a new customer-friendly experience to keep track of most of your Food Inventory. It opened up the opportunity for Silo to automatically re-purchase food for you. It is one big and steady income stream for a company to have. And as the smart kitchen appliance was carefully designed to stay on your kitchen counter and was voice operated, it may end up being your primary way to purchase food. That was the company’s potential. And it was big enough of a potential for both Amazon and Whirlpool to take interest in. Alas, in the time of writing this in 2022, it did not come to fruition. But in an alternate universe, one day labeling became an extremely critical User Journey. As a label missed would have been a sale lost.
It is debatable how critical labeling was for Silo’s stakeholders, but it is definitely not as critical as its real primary function. As long as the smart kitchen appliance keeps on vacuuming containers and extending food shelf life, we will keep on being on the safe side with our customers.
Reliably Efficient
Throughout this entire book we’ve talked about Inefficiencies. Some are caused by our application’s evolutionary processes, and mismatches with the Change Stream. Both of which we’ve learned to design for and avoid in the series of Change Driven Design, and we’ve done the same for multiple applications in the series of Breaking Change. We saw how Inefficiencies are generated and affect our development workflow.
It all has something to do with Reliability, to deal with The Inevitable. A component in the system will eventually fail. Giving up on it and doing nothing to prevent it, would lead to an unreliable system and a non-beneficial outcome. Investing it all into 100% Reliability is also a non-beneficial outcome, as nothing can be made to be 100% reliable. Even AWS does not guarantee that.
The middle way would be to also invest in recovery. For when something does go wrong, we can recover as quickly as possible. It requires to make sure the damage would be limited and contained. Recovering from an independent and smaller portion of the system going down and not the entirety of it, gives better conditions to do so. It would be easier to trace the fault to a smaller part, and done under less stress. All of which contribute to a faster recovery time, keeping customers annoyed but not furious.
What also keeps them so is monitoring. We need to know as soon as possible something went wrong. Because down time starts when our customer experience stops working, not when our engineers find out about it.
We also wanted to recruit the best engineers. If we could run the company efficiently, we could offer something no other company can give. We could pay the same or less than our competitors, but also for less work time. A 4 week day job, a better work life balance. To some of the best engineers, it’s worth more than anything.
This line of thought, the insight into customer expectations for reliability, latency, consistency and freshness for multiple Actors participating in experiences, were the product requirements of the architecture. The very same candidate we came up with in the last few chapters, the one which enables this. Lest we forget, the requirements came before the solution. Architecture is only an answer.
In my perspective, it is again the difference between software architecture and system architecture. It is the latter that takes into account the customers, the personnel and the development workflow of the company. So let’s put those into our candidate for a system architecture. Something we’ll do in the next chapter.