In the previous chapter, we’ve taken our first step into the world of messaging. Specifically, with the Publish/Subscribe pattern. Unfortunately, we ended up with our data.json file on S3 being too big, concurrently written to, and easy to break its data structure. Exactly the kind of issues a database already takes care of for us.
In this chapter, we’re going to do something a little different. We’re going to first do what we’ve avoided doing so far, and store our data in a database. And in order to overcome it bundling our Actors together through the backend, we’ll try to have the database itself perform a publish/subscribe pattern on its own. By doing so, we’ll have an alternative to compare our messaging based design to.
Same but Different
In this series, we’ve been avoiding using databases in our designs, for several reasons:
- Not all scenarios require persistence. We wish to assume less than more.
- A database would be something shared between mutually exclusive applications. A fully decentralized database is a very Restrictive one, not a valid candidate for a system architecture .
- It’s too obvious of a solution.
- To have an introduction to the less known paradigm of messaging patterns, which we can read a whole lot more about in Enterprise Messaging Patterns.
I would like to bring in a fifth reason, a rather different perspective bridging between the two disciplines. Please do read it with a shred of doubt. Starting with what messaging and databases share in common.
Both are distributed systems, or participate in ones. They face exactly the same challenges we were facing in the last few chapters, the very same parameters we were playing with: freshness, consistency, size, concurrency and there are more we haven’t covered like transactions and atomicity, shards and replicas. These are issues a database already takes care for us, where in messaging we’d have to handle some of those ourselves. Funny thing is, within a database and between all of its instances, messaging exists. Wherever communication exists, in a way messaging exists.
For a database, it is internal “messaging” specifically optimized for its needs. Message sizes, types and frequency is minimized for the least data transfer required. To maintain consistency, some databases might use a gossip protocol, some might be doing leader elections to reach a consensus. We’re more than welcome to deeply dive into it in the book about database internals, or read about distributed communication patterns.
Both also share the matter of persistence, but have different requirements for it. While we expect a database to store data indefinitely, messages in transit are expected to be short living. A message needs to be temporarily persisted, only until its fan out is completed. Only until consumed by all those who are registered to receive it.
How long is temporary? A day when all consumers work perfectly and as expected, also giving each one enough buffer to consume messages in their own time. A week, for when a consumer fails to process and our engineers require a time buffer to fix it. Some message brokers store the message log indefinitely, something we can not assume done by all. Later in this series, we’ll deep dive into the matter of message Reliability.
Assuming Topologies
As we ran into an issue with our file size, fetching costs in S3 scales linearly with it, let’s move it into a database. We’ll also make it internally do something similar to our Publish/Subscribe pattern, make its own internal communication do so.
A common database such as MySQL or Postgres supports a main-replica topology. Writes are made only to the main instance, and reads are done only from dedicated read replicas. For our microservice instances to remain mutually exclusive, we wish for each instance to have a dedicated read replica.
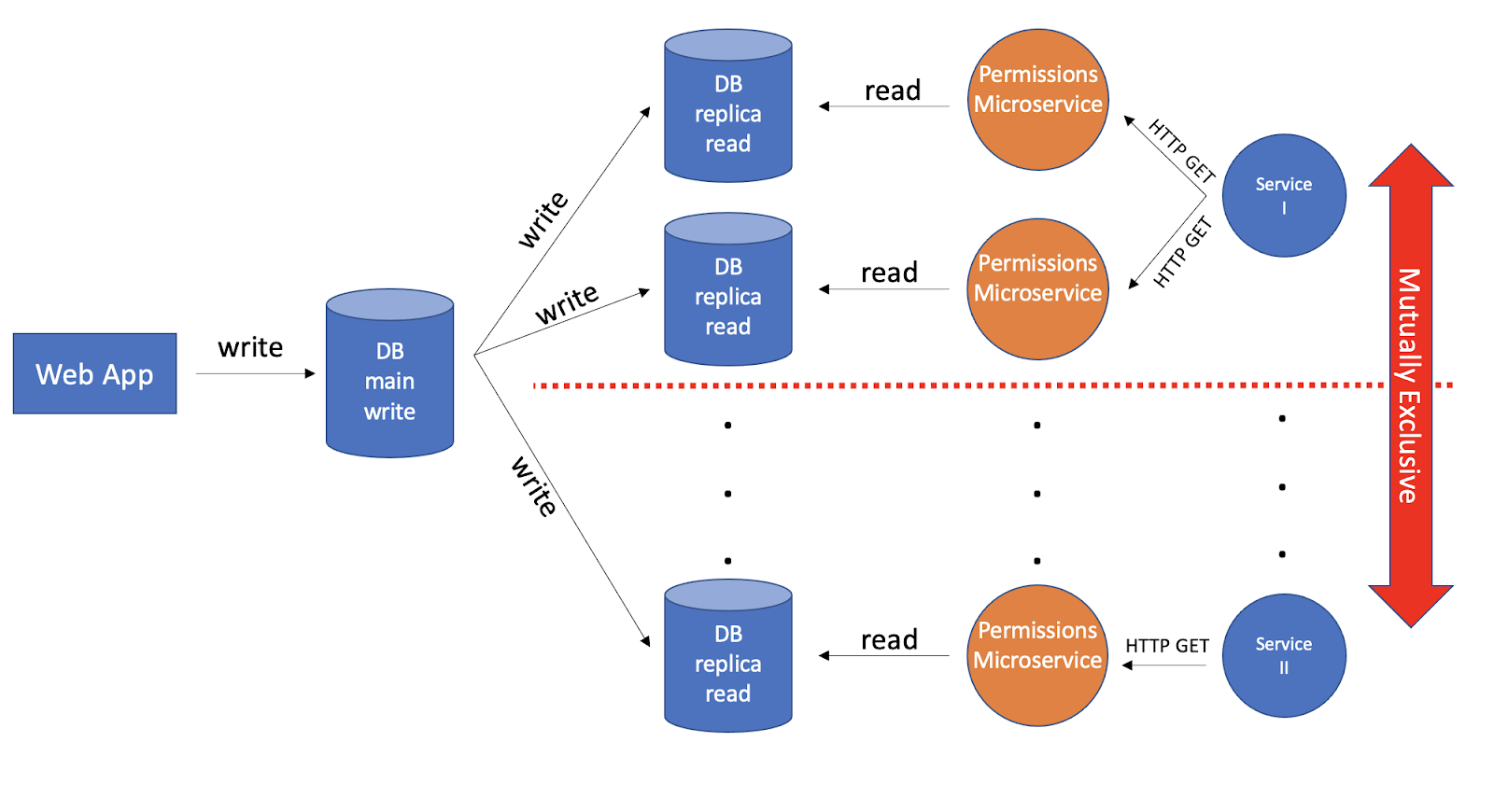
The fan out done while writing, along with our database’s replication capabilities, is a reflection of our pub/sub pattern. One without a need for any additional components. If neither our main nor our read replicas can withstand the traffic’s throughput, we’d need to scale them up vertically. It also fits all of our customers’ expectations of freshness and propagation. If required, we also gained hard-consistency.
Problem is, we’ve run ourselves into a trap we’ve seen before. We had assumed all databases are capable of reflecting a pub/sub pattern. As a design to solve a specific problem, it is of no concern. As a system architecture Restricting our colleagues from using several other databases, such as DynamoDB, it just won’t do.
Cost Models
Let’s consider costs once again. As micro-sized DB instances are discouraged from being used in production, the cheapest AWS RDS instance would be db.XXX.small. Each one costs 0.032$ per hour, sums up to 23$ a month. If we recall RapidAPI’s numbers, 72 instances would be required + 1 for main, for them it would sum up to 1,681$ per month. A number to compare against messaging based costs.
In our scenario, we do 1m writes per day. On SNS, the cost of producing 1m messages is 0.5$, which sums up to 15$ a month. These would entail another 72 million messages fanned out to consumers. On SNS, delivery of 1m messages cost 0.6$, so it sums up to 43.2$ a day and 1,311$ a month (Data transfer costs out of SNS are negligible in comparison, because messages are small sized). Lest we forget these costs scale with how frequently our customers are Changing their data. We’ve seen scenarios measured in far less than millions writes.
Before we jump to a conclusion that one is cheaper than the other, we should notice we’ve been comparing apples and oranges. An RDS instance is a resource paid for its actual runtime, which is 24/7. Depending on our working hours and requirements, we may be able to pay less with Amazon Aurora, which can be hibernated. Or maybe choosing DynamoDB with its on demand pricing we could have reached a lesser cost. Unfortunately, our supposedly architectural decision had Restricted us from using it. Goes to say how sensitive architecture is.
On the contrary, we could have differently reduced our messaging platform costs. Instead of paying per action with SNS, we could have selected a message broker which we pay for its actual runtime, like RabbitMQ. Making it no longer increase linearly with message count.
Maybe a better way to compare the two costs is with how it increases with scaling, how much an additional microservice instance would cost us. One more RDS instance starts with 23$ a month. A fan out of another 1m messages with SNS would cost 18$ a month.
Which is more cost-effective depends on our scenario and the problem we are trying to solve. If we try to solve it first with respect to size, persistence and costs, we may end up with a more costly solution with no additional value to our customers. The same result of designing without considering those.
Although.. maybe we’re just paying too much for databases, because we’ve made a mistake along the way?
Micro-conundrum
We’ve just realized that a reusable microservice with persistence is extremely costly. One of the reasons we kept it as a pure application as much as we can for as long as we can. We ended up with RapidAPI’s number of 72 instances, due to our efforts to maintain Cohesion and Reliability, high availability, and keeping our Services and Actors mutually exclusive. That has just led us to need 72+1 instances of our database. Maybe we overdid it, so we better change the design to pay less for those.
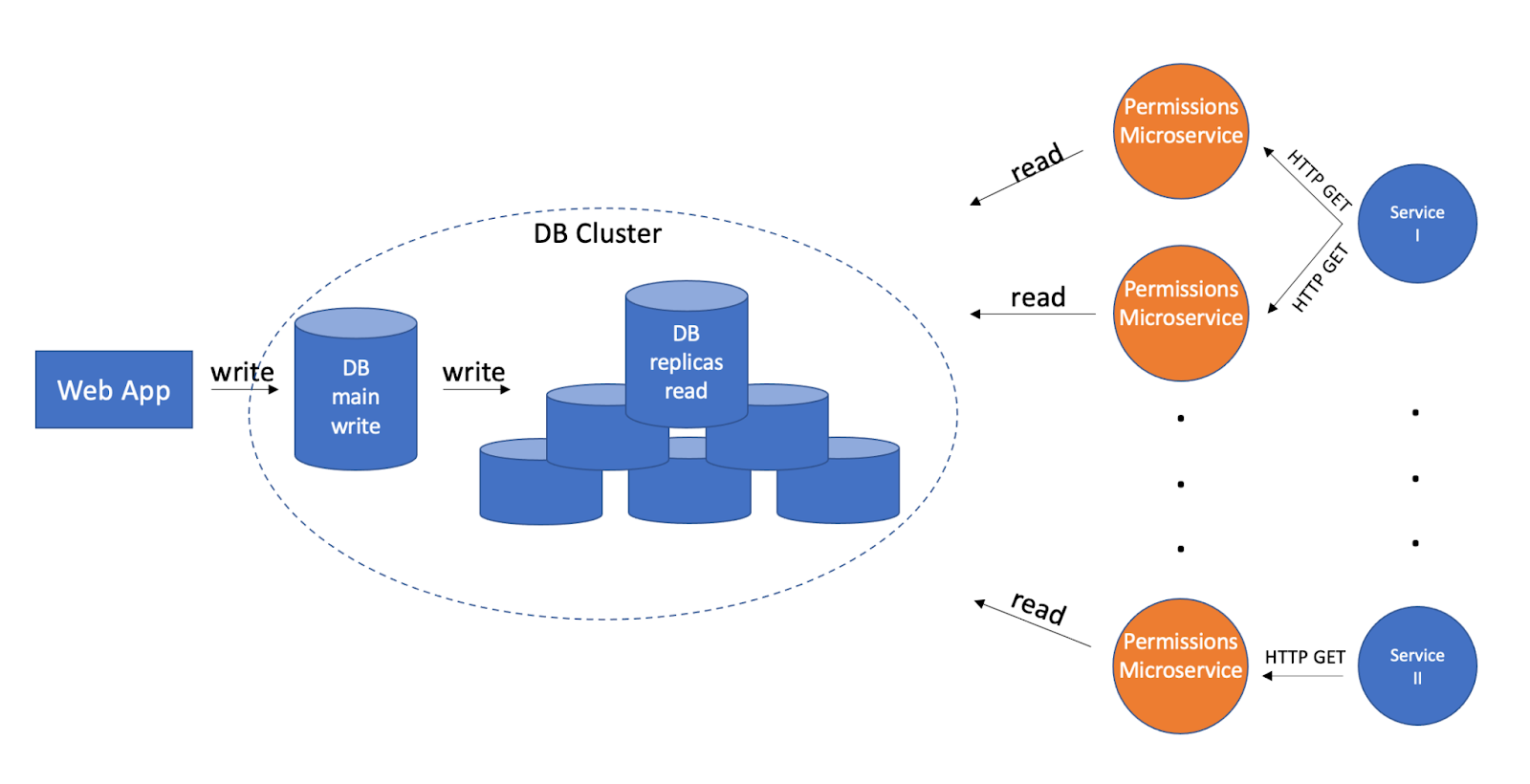
For the database, the topology remained the same. It would still have one main replica and multiple read replicas. The write/read separation remained the same as well. What’s different is the read replicas count will scale up and down with the combined traffic from all of our microservice instances. No longer from each one independently.
If that is so, what is it that we have now? Is our application still a microservice or just a Service wrapping a database? From a bird’s eye view, where does the share zone start and end now?
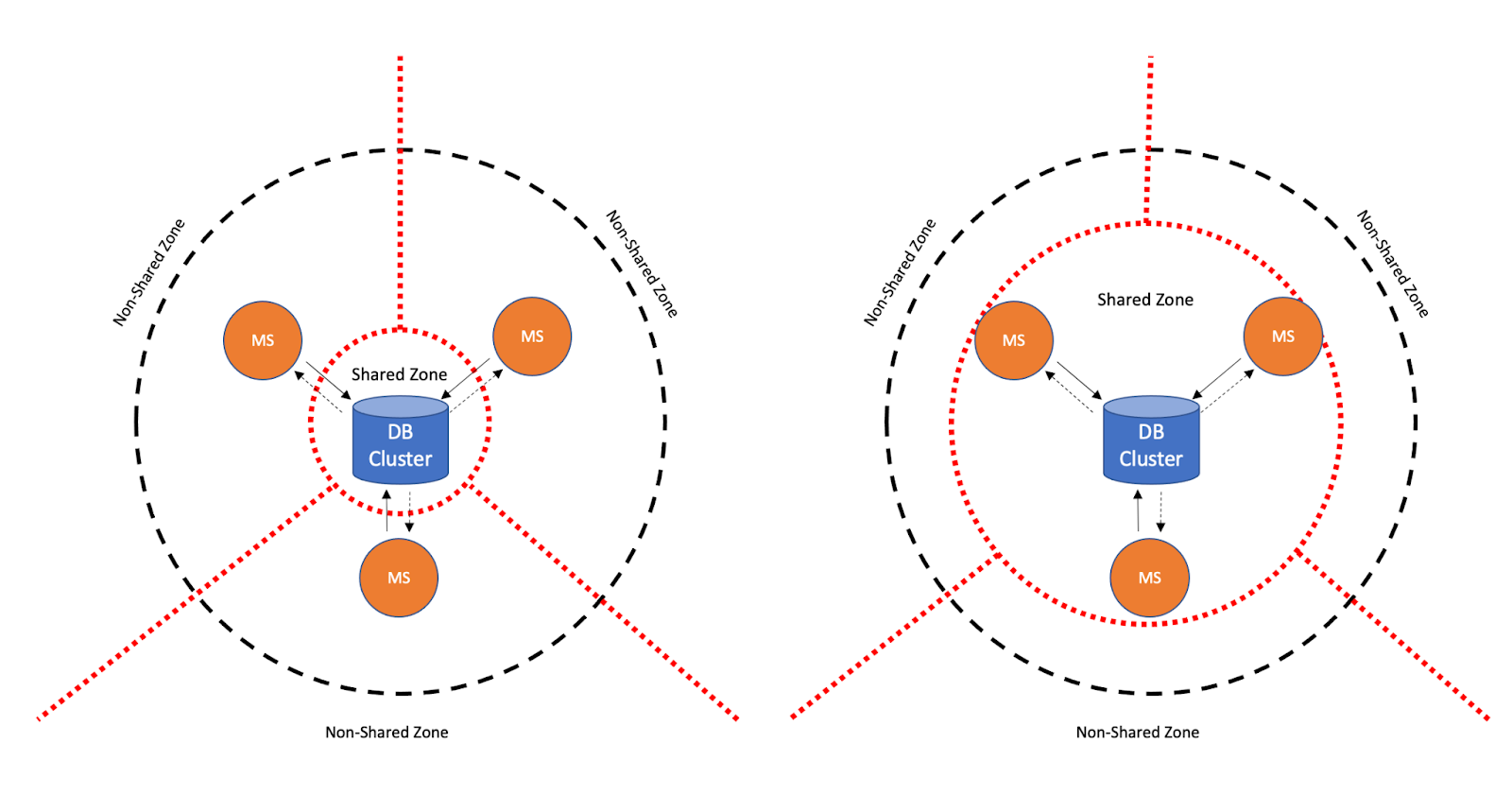
Wouldn’t it also be easier to maintain Cohesion and Reliability, by ensuring a gradual Rollout of a Service with a blue-green deployment, then it being a reusable infrastructure component microservice? And it would definitely be cheaper.
It seems like we ended up with a contradiction. A microservice that supposedly had been better off being just a Service. A consequence of persisting in a database. Something we suspected might happen once there is something shared between our microservices. However, we have seen we have a lot to gain once a database is used. So maybe a combination of messaging and databases would be a worthy candidate for a system architecture. On this, in the next chapter.